Redis cluster 从库自动failover机制
目录
一、每个节点维护的信息
二、故障发现(主观下线)
三、客观下线
1.下线报告链表
2.pfail到fail的转变
四、从库通过clusterCron发起自动切换
五、主库投票
六、从库执行切换
七、纪元更新
一、每个节点维护的信息
每个节点内的clusterState结构保存集群信息,从库自身视角所维护的一些信息。结构关键属性如下:
在cluster.h文件中:
typedef struct clusterState {
clusterNode *myself; /* 自身节点 */
int size; /* 当前节点认为的集群节点数 */
dict *nodes; /* 集群节点字典,当前节点认为集群中有哪些节点,key为节点ID,value为对应节点ClusterNode结构 */
...
} clusterState;此外每个节点都会为集群里的所有节点维护一个clusterNode结构,通过上述clusterState的nodes指针指向这些clusterNode,大致结构如下:
typedef struct clusterNode {
int flags; /* 节点的状态,如:master/slave,pfail/fail等 */
mstime_t ping_sent; /* 本节点最后一次与该节点发送ping消息的时间 */
mstime_t pong_received; /* 最后一次接收到该节点pong消息的时间 */
...
} clusterNode;
clusterNode里的flags,有以下状态:
CLUSTER_NODE_MASTER 1 /* 当前为主节点 */
CLUSTER_NODE_SLAVE 2 /* 当前为从节点 */
CLUSTER_NODE_PFAIL 4 /* 主观下线状态 */
CLUSTER_NODE_FAIL 8 /* 客观下线状态 */
CLUSTER_NODE_MYSELF 16 /* 表示自身节点 */
CLUSTER_NODE_HANDSHAKE 32 /* 握手状态,未与其他节点进行消息通信 */
CLUSTER_NODE_NOADDR 64 /* 无地址节点,用于第一次meet通信未完成或者通信失败 */
CLUSTER_NODE_MEET 128 /* 需要接受meet消息的节点状态 */
CLUSTER_NODE_MIGRATE_TO 256 /* 该节点被选中为新的主节点状态 */二、故障发现(主观下线)
集群节点间通过gossip相互通信,如果节点A收到节点B的pong,节点A则更新节点B clusterNode的pong_received。
每个节点都会检测自己维护的各节点clusterNode,是否有节点的pong_received大于cluster-node-timeout,如果有,则认为该节点不可用,将不可用节点的flags设为CLUSTER_NODE_PFAIL。
76803:S 09 Jun 17:01:19.274 . *** NODE 64cdc10096644b5bc3624f41ade916983806c47c possibly failing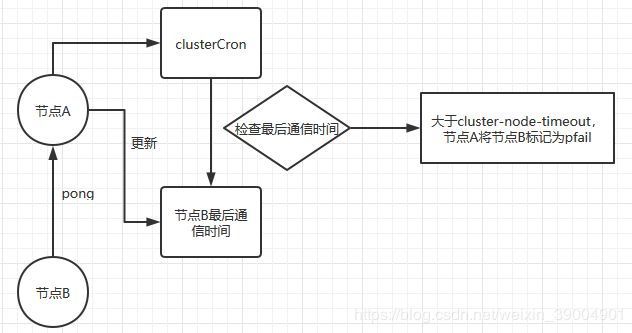
但这个状态并不是最终的故障判定,只能代表一个节点的意见,可能存在误判情况。
集群节点在通信ping/pong时,会附带自己对某个节点的pfail信息
三、客观下线
1.下线报告链表
当集群内某个节点出现问题时,需要通过一种健壮的方式保证识别出节点是否发生了故障。
Redis是通过半数以上持有slot的主节点都认为某一个节点挂了,该节点才是真的挂了,即客观下线。
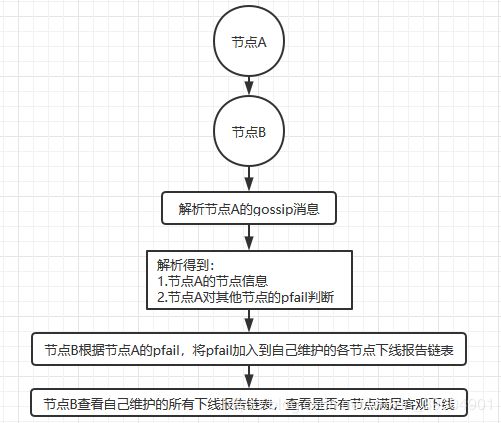
一个节点如果将另一个节点的flags设为CLUSTER_NODE_PFAIL状态,那么也会为该节点维护一条下线报告链表,来记录在集群通信期间来自其他主库对同一个节点的pfail信息:
1)当消息体内含有其他节点的pfail状态会判断发送节点的状态,如果发送节点是主节点则对报告的pfail状态处理,从节点则忽略;
2)找到pfail对应的节点结构,更新clusterNode内部下线报告链表;
3)根据更新后的下线报告链表告尝试进行客观下线。
struct clusterNode { /* 认为是主观下线的clusterNode结构 */
list *fail_reports; /* 记录了所有其他节点对该节点的下线报告 */
...
};
2.pfail到fail的转变
在两种情况下,某一个节点的flags会转换成fail:
第一种情况
节点收到某个主库发来的fail广播,那么会马上将自己维护的相关节点flags设为fail。
第二种情况
上面说到,每次收到其他节点的pfail信息,都会根据更新后的下线报告链表告尝试进行客观下线,代码实现是markNodeAsFailingIfNeeded:
1)检查本地下线报告链表的长度(failures)是否大于needed_quorum,如果是,则更新本地关于故障节点clusterNode的flags为CLUSTER_NODE_FAIL;
2)如果当前节点是主库,还会调用clusterSendFail向集群所有节点广播故障节点的客观下线状态(fail)。其他节点收到广播后,会马上更新各自本地对于故障节点clusterNode的flags信息,即上述第一种情况;
3)如果当前节点是从库,则不会广播,只是更新本地的关于故障节点的flags,但没办法通知其他节点,让它们也更新故障节点的flags。
void markNodeAsFailingIfNeeded(clusterNode *node) {
int failures;
int needed_quorum = (server.cluster->size / 2) + 1; /*半数以上持有slot的主库*/
if (!nodeTimedOut(node)) return; /* We can reach it. */
if (nodeFailed(node)) return; /* Already FAILing. */
failures = clusterNodeFailureReportsCount(node); /*failures=下线报告链表长度*/
/* Also count myself as a voter if I'm a master. */
if (nodeIsMaster(myself)) failures++; /*下线报告链表只记录其他主库的pfail,如果执行函数的节点是主库,failures要加上自己的pfail*/
if (failures < needed_quorum) return; /* No weak agreement from masters. */
serverLog(LL_NOTICE,
"Marking node %.40s as failing (quorum reached).", node->name);
/* Mark the node as failing. */
node->flags &= ~CLUSTER_NODE_PFAIL;
node->flags |= CLUSTER_NODE_FAIL;
node->fail_time = mstime();
/* Broadcast the failing node name to everybody, forcing all the other
* reachable nodes to flag the node as FAIL. */
if (nodeIsMaster(myself)) clusterSendFail(node->name);
clusterDoBeforeSleep(CLUSTER_TODO_UPDATE_STATE|CLUSTER_TODO_SAVE_CONFIG);
}
四、从库通过clusterCron发起自动切换
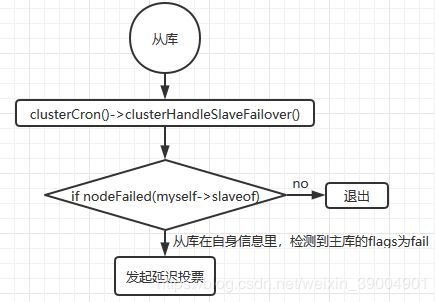
clusterCron是每个节点每秒都会执行10次,而对于从节点,执行clusterCron时,其中还包括了尝试否是需要进行切换
if (nodeIsSlave(myself)) {
clusterHandleManualFailover(); /*进入clusterHandleManualFailover,判断是否有人工切换*/
clusterHandleSlaveFailover(); /*进入clusterHandleSlaveFailover,判断是否需要自动切换成主库*/而在clusterHandleSlaveFailover中,其中有诸多判断条件来决定从库是否需要发起切换,其中一个就是通过nodeFailed(myself->slaveof)判断自己的主库是否已经客观下线
nodeFailed的定义:
#define nodeFailed(n) ((n)->flags & CLUSTER_NODE_FAIL)通过nodeFailed(myself->slaveof),从库会检查本地维护的clusterNode的flags是否为CLUSTER_NODE_FAIL,如果是,则发起切换延迟投票
五、主库投票
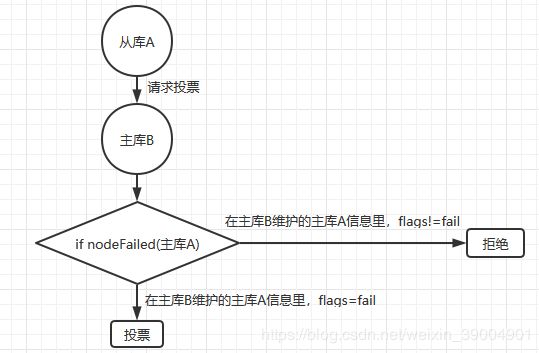
当从库经过delay后正式发起选举,通过clusterRequestFailoverAuth向所有存活主库发送投票请求。
主库收到从库的投票请求,通过clusterSendFailoverAuthIfNeeded来判断是否要投票。
如果请求投票节点的master还不是客观下线,则放弃投票,这里的客观下线,是判断本地节点信息里,请求投票节点的master的flag,同样是调用nodeFailed()来判断
if (nodeIsMaster(node) || master == NULL ||
(!nodeFailed(master) && !force_ack))
{
if (nodeIsMaster(node)) {
serverLog(LL_WARNING,
"Failover auth denied to %.40s: it is a master node",
node->name);
} else if (master == NULL) {
serverLog(LL_WARNING,
"Failover auth denied to %.40s: I don't know its master",
node->name);
} else if (!nodeFailed(master)) { /*判断挂掉的主库的flags是否为CLUSTER_NODE_FAIL,如果不是,则拒绝*/
serverLog(LL_WARNING,
"Failover auth denied to %.40s: its master is up",
node->name);
}
return;
}
经过各种判断,没有问题,存活主库则会投票给请求从库,上面的判断只是其中一个环节,具体看源码clusterSendFailoverAuthIfNeeded()。
有一个问题需要注意,一个节点是通过自己维护的clusterNode的flags属性来判断一个节点是否客观下线,由于从库在修改flags时并不会广播,所以从库A和主库B对于主库A的flags,是有可能不一致的,因为当从库A将主库A的flags设为fail时,并不会通知主库B也去更新flags。这就会造成可能从库A最先拿到了多数主库的pfail,从而将主库A设为fail状态,但并不通知其他存活主库;当下一次从库执行clusterCron时,检测到主库A的flags为fail,则发起投票,但在主库B投票时,主库B所维护的主库A的flags还不是fail,那么主库B就会拒绝给从库A投票。
六、从库执行切换
从库拿到大多数主库的投票后,执行切换