springboot整合elasticsearch实现文章搜索,elasticsearch学习三
springboot整合elasticsearch实现全文检索做文章搜索
最近做一个信息分享类的项目:使用springboot集成elasticsearch使用全文检索,实现文章搜索。
开发完成做一个总结记录。
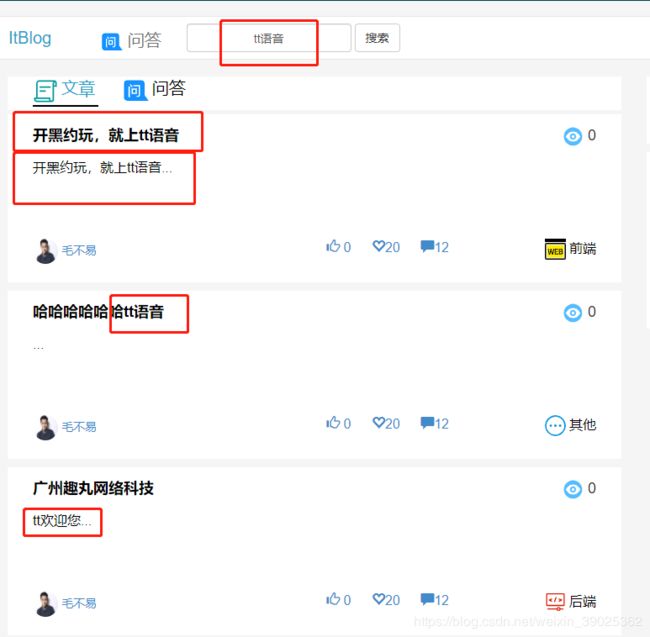
下面是es仓库数据和页面效果,笔者做的是mvc开发的在前端使用的是freemarker表达式,
如果有人愿意帮我写页面的话,做成前后端分离也不错。可以看到分词后,tt语音被ik分成三个单词,tt语音、tt、语音,
然后根据搜索的权值进行排序。

1.先介绍使用的技术,和开发的思维吧
1.首先当然是先集成elasticsearch环境,添加ik中文分词插件,笔者使用的es6.2.4,还是建议大家es的版本不要选择太高,
不然你不对着es的官方文档做出bug了百度搜都没有。配置elasticsearch环境可以参考笔者的上一篇文章,写得很详细了。
安装Elasticsearch6.2.4、IK分词器以及Head插件步骤
2.创建文章的索引仓库,我的思路是先进行ik分词,分词后的词语在es中做类似搜索引擎的搜索,利用在索引库检索标题和内容,搜出来的文章id,然后去mysql里面把对应的文章搜索出来,拼装成一个json对象,返回给前端。

2.es索引仓库创建过程
1.创建文章的es索引仓库,es的索引从概念上讲和mysql的表类似,也当成创建一个mysql表,
里面的字段含义,以及操作实现笔者另外写了一篇博客给大家说明。
springboot整合elasticsearch实现增删改查
可以使用postman创建索引库,也可以使用head插件运行代码创建索引库

{
"settings": {
"index.number_of_shards": 1,
"index.number_of_replicas": 0,
"index.refresh_interval": "-1"
},
"mappings": {
"article": {
"properties": {
"id": {
"type": "long",
"index": false
},
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word",
"boost": 1.5
}
}
}
}
}
2.代码实现过程
Elasticsearch Java API 大致分如下四类:
- TransportClient
- RestClient
- Jest
- Spring Data Elasticsearch
笔者在本篇中使用Spring Data Jpa,原因当然就是因为这需求相当于是查询单表的操作,jpa实现起来非常简单,
如果使用mybatis来操作es的话,又要集成一堆东西,而jpa还好,springboot集成了es有starter给我们使用
1.引入maven
<!-- mysql -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.48</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- freemarker -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-freemarker</artifactId>
</dependency>
<!--devtools热部署-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<optional>true</optional>
<scope>true</scope>
</dependency>
<!-- 为了可以使用StringUtils的方法 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.8.1</version>
</dependency>
<!-- redis -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- elasticsearch -->
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
2.创建es的实体类
@Document: 代表一个文档记录 ,indexName: 用来指定索引名称, type: 用来指定索引类型
@Id: 用来将对象中id和ES中_id映射
@Field: 用来指定ES中的字段对应Mapping,其中的type: 用来指定ES中存储类型,analyzer: 用来指定使用哪种分词器
@Getter
@Setter
@ToString
@Document(indexName = "itblog",type = "article",shards = 1,replicas = 0, refreshInterval = "-1")
public class EsArticle implements Serializable {
private Long id;
private String title; //标题
private String content;// 缩略内容
public EsArticle(Long id, String title, String content) {
this.id = id;
this.title = title;
this.content = content;
}
public EsArticle() {
}
}
3.EsService
@Service
public class EsService {
@Autowired
private ArticleRepository articleRepository;
public void save(EsArticle article){
articleRepository.save(article);
}
public void deleteById(Long articleId){
articleRepository.deleteById(articleId);
}
public Page<EsArticle> search(String title, String content, Pageable pageable){
return articleRepository.findByTitleLikeOrContentLike(title,content,pageable);
}
public Page<EsArticle> search(String content, Pageable pageable){
return articleRepository.findByContentLike(content,pageable);
}
public Page<EsArticle> findAll(Pageable pageable){
return articleRepository.findAll(pageable);
}
}
3.在控制层的调用
1.在一开始笔者的思路就是,es做搜索,然后把搜索得到的文字id去mysql里面查询出一个json对象,然后响应给前端
所以我们得到id之后,在mysql里使用in操作,但是in默认的排序是按照主键id排序,但是我们却是想它按照在es查出
来的id来排序,为什么呢?因为es在全文检索时,被搜索的文章含有倒排索引库的单词越多,它的权值就越大,然后
就越靠前,这里我们使用mysql的field()函数,这样就完成了
<select id="selectSearchArticles" resultType="com.wyu.itblog.common.vo.ArticleVo" parameterType="java.util.List">
SELECT a.article_id,a.title,a.create_time,a.simple_content,a.page_view,a.point_count,
t.type_id,t.type_name,type_url,
u.user_id,u.user_name,u.user_url
from article a,article_type t,`user` u
where a.article_id in
<foreach collection="list" index="index" item="item" open="(" separator="," close=")">
#{item}
</foreach>
and a.user_id = u.user_id
and a.flag = 1
and a.type_id = t.type_id
<if test="list!= null and list.size>0">
order by field( article_id,
<foreach collection="list" index="index" item="item" separator="," close=")">
#{item}
</foreach>
</if>
</select>
4. 方法总结
1.这是我一开始的思路,将文章的id、标题、内容插入到es中,搜索的时候,把id搜出来,然后再到mysql中根据id查询,拼装成前端需要展示的json的对象
2.之后,第二种方法,我们可以看到展示的时候,需要把需要展示的数据一并查出来然后插入到es中,但是这一种方法不能将变化比较大的字段插入进去,比如浏览次数点赞数,因为他们随时都在增加着。但是可以把所属用户的id、头像、姓名,文章所属分类、分类id插入到es中,这样做的话,速度更快,但是可展示的内容就少了一点。
5.最后
笔者在这里,更多的是提供一种思路给大家,其实自己做的虽然可以实现搜索功能,第一种方式需要再去mysql查数据做不到搜索词光亮的效果,但是显示内容多速度相对慢。第二种则可以做到搜索词高亮效果,速度快,但是展示内容少。
这比较简单实现搜索的两种实现方式,如果有同学想了解更多的话,可以私信我一下一起交流。