python模块(pip、datatime和time、collections、random、glob、shutil、hashlib、argparse、 logging、doctest、unittes)
1、pip
python包索引:https://pypi.python.org/pypi (可以去查询相关的pip的包的信息)

2、常用模块


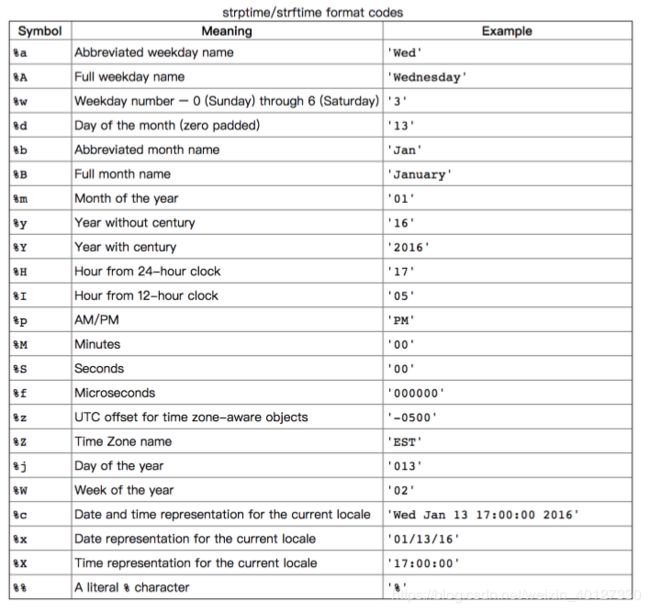
2.1 datatime模块和time模块
datatime模块重新封装了time模块,提供更多接口,提供的类有:date,time,datetime,timedelta,tzinfo。
参考:https://www.cnblogs.com/tkqasn/p/6001134.html
2.2、collections模块
collections模块在内置数据类型的基础上,提供了几个额外的数据类型
namedtuple(): 生成可以使用名字来访问元素内容的tuple子类
可以认为是只有成员变量的最简单的类;内部元素无法修改;
import collections
Person = collections.namedtuple('Person','name age')
bob = Person(name='Bob',age=30)
print(bob)
jane = Person(name='Jane',age=29)
print(jane.name)
for p in [bob,jane]:
print('{} is {} year old'.format(*p))
输出:
Person(name='Bob', age=30)
Jane
Bob is 30 year old
Jane is 29 year olddeque: 双端队列,可以快速的从另外一侧追加和推出对象
拥有list的一般操作;
import collections
d1 = collections.deque()
d1.extend('abcdefg')
print(d1)
d1.append('h')
print(d1)
d2 = collections.deque()
d2.extendleft(range(6))
print(d2)
d2.appendleft(6)
print(d2)
输出:
deque(['a', 'b', 'c', 'd', 'e', 'f', 'g'])
deque(['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h'])
deque([5, 4, 3, 2, 1, 0])
deque([6, 5, 4, 3, 2, 1, 0])import collections
print('from the right:')
d = collections.deque('abcdefg')
while True:
try:
print(d.pop(),end='')
except IndexError:
break
print() # 默认追加一个换行符
print('from the left:')
d = collections.deque(range(6))
while True:
try:
print(d.popleft(),end='')
except IndexError:
break
输出:
from the right:
gfedcba
from the left:
012345Counter: 计数器,主要用来计数
参考:http://www.pythoner.com/205.html
import collections
c = collections.Counter('abcdefab')
print(c['a'])
print(c.most_common())
print(c.most_common(3))
输出:
2
[('a', 2), ('b', 2), ('c', 1), ('d', 1), ('e', 1), ('f', 1)]
[('a', 2), ('b', 2), ('c', 1)]
OrderedDict:有序字典
import collections
d1 = collections.OrderedDict()
d1['a'] = 'A'
d1['b'] = 'B'
d1['c'] = 'C'
d2 = collections.OrderedDict()
d2['a'] = 'A'
d2['c'] = 'C'
d2['b'] = 'B'
print(d1 == d2)
输出:
False
import collections
d1 = collections.OrderedDict([('a','A'),('b','B'),('c','C')])
print('before:')
for k,v in d1.items():
print(k,v)
d1.move_to_end('b') #移动到dict的最后面,默认last=True
print('move_to_end()')
for k,v in d1.items():
print(k,v)
d1.move_to_end('b',last=False) #移动到dict的最前面
print('move_to_end(last = False)')
for k,v in d1.items():
print(k,v)
输出:
before:
a A
b B
c C
move_to_end()
a A
c C
b B
move_to_end(last = False)
b B
a A
c Cdefaultdict: 带有默认值的字典
参考:https://www.cnblogs.com/wqbin/p/10222768.html
defaultdict的作用是在于,当字典里的key不存在但被查找时,返回的不是keyError而是一个默认值,这个默认值依赖于构造参数
import collections
#统计列表中同名项出现次数
list = [1,2,1]
dict = {}
dict2 = {}
for k in list:
if k not in dict:
dict[k] = 1
else:
dict[k] += 1
print(dict.keys(),dict.values())
#第二种方法
for k in list:
dict2.setdefault(k,0)
dict2[k] +=1
print(dict2.keys(),dict2.values())
#第三种方法
dict1 = collections.defaultdict(int)
for k in list:
dict1[k] +=1
print(dict1.keys(),dict1.values())
输出:
dict_keys([1, 2]) dict_values([2, 1])
dict_keys([1, 2]) dict_values([2, 1])
dict_keys([1, 2]) dict_values([2, 1])import collections
dict1 = collections.defaultdict(int)
print(dict1[1])
def string_duplicate_3(s):
a = collections.defaultdict()
for x in s:
a[x] = 0
return a.keys(),a.values()
b = string_duplicate_3([1,1,1,23,4,5,5])
print(b)
输出:
0
(dict_keys([1, 23, 4, 5]), dict_values([0, 0, 0, 0]))2.3、random模块
用于生成随机数的,我们可以利用它随机生成数字或者选择字符串,生成方法:有随机正态分布,帕累托分布,高斯分布,β分布,γ分布,三⻆角分布,威布尔分布等各种函数
参考:https://www.cnblogs.com/askill/p/9979117.html
https://blog.csdn.net/weixin_41084236/article/details/81457949#randomgetstate
>>> import random
>>> s=random.getstate()
>>> random.random()
0.15441857485858956
>>> random.random()
0.6330314601528841
>>> random.setstate(s)
>>> random.random()
0.15441857485858956
>>> random.random()
0.6330314601528841
>>> random.random()
0.04725013105129261
import random
import os
import pickle
for i in range(5):
print('%06.3f' %random.random(),end=' ')
print()
random.seed(1) #设置随机种子
for i in range(5):
print('{:06.3f}'.format(random.uniform(1,100)),end=' ')
print()
if os.path.exists('state.dat'):
print('found state.dat,initializing random module')
with open('state.dat','rb') as f:
state = pickle.load(f)
#print(state)
random.setstate(state) #恢复状态
else:
print('no state.dat,seeding')
random.seed(1)
for i in range(3):
print('{:04.3f}'.format(random.random()),end=' ')
print()
with open('state.dat','wb') as f:
pickle.dump(random.getstate(),f) #获得当前状态,用于恢复状态
print('after saving state:')
for i in range(3):
print('{:04.3f}'.format(random.random()),end=' ')
print()
输出:
00.367 00.722 00.166 00.699 00.977
14.302 84.896 76.614 26.252 50.048
found state.dat,initializing random module
0.762 0.002 0.445
after saving state:
0.722 0.229 0.945 import random
for i in range(5):
print(random.randint(1,100),end=' ')
print()
for i in range(5):
print(random.randint(-5, 10), end=' ')
print()
输出:
80 73 6 17 81
3 -3 9 0 3
import random
for i in range(5):
print(random.randrange(0,101,5),end=' ') # 0到100随机5的倍数
print()
outcomes = {'heads':0,'tails':0}
sides = list(outcomes.keys())
for i in range(10000):
outcomes[random.choice(sides)] +=1 #返回对象中的一个随机元素
print('heads:',outcomes['heads'])
print('tails:',outcomes['tails'])
输出:
65 30 60 95 75
heads: 4975
tails: 50252.4、glob模块、shutil模块、sys模块、os模块
glob文件匹配模块,应用场景是要寻找一系列(符合特定规则)文件名。查找文件只用到三个匹配符:”*”, “?”, “[]”。
”*”匹配0个或多个字符;”?”匹配单个字符;”[ ]”匹配指定范围内的字符,如:[0-9]匹配数字
import glob
for name in glob.glob('C:/*'):
print(name)
print()
for name in sorted(glob.glob('C:/*')):
print(name)
for name in sorted(glob.glob('Lesson6/subdir/*')):#子文件夹,不会进行递归,需要写出路径
print(' {}'.format(name))
for name in sorted(glob.glob('Lesson6/*/*')):
print(' {}'.format(name))
for name in sorted(glob.glob('Lesson6/file?.txt')):
print(name)
for name in sorted(glob.glob('Lesson6/file[0-9].*')):
print(name)shutil模块文件操作模块;
print和pprint两者的区别 参考:https://blog.csdn.net/qq_24185239/article/details/80977556
import shutil
shutil.copyfile('Lesson6/file1.txt','Lesson6/file1.txt.copy') #复制文件
shutil.copytree('Lesson6/subdir','Lesson6/subdit_copy') #复制目录
shutil.move('Lesson6/subdir','Lesson6/subdit_copy') #移动
shutil.rmtree('Lesson6/subdir') #删除
for format,description in shutil.get_archive_formats(): #获取压缩类型
print('{:<5}:{}'.format(format,description))
shutil.make_archive('example','zip',root_dir='Lesson6/',base_dir='subdir')
for format,description in shutil.get_unpack_formats(): #获取解压缩类型
print('{:<5}:{}'.format(format,description))
shutil.unpack_archive('example.zip',extract_dir='tmp')sys模块和os模块
参考:https://blog.csdn.net/qq_38276669/article/details/83687738
2.5、hashlib模块
加解密模块
import hashlib
lorem = 'afhsdkhdkgdfjhf'
h = hashlib.md5() # MD5算法
h.update(lorem.encode('utf-8'))
print(h.hexdigest())2.6、argparse模块
命令行参数解析模块
参考:(主要)https://blog.csdn.net/leo_95/article/details/93783706
https://www.jianshu.com/p/00425f6c0936
import argparse
parser = argparse.ArgumentParser(description='this is a sample program') #创建解析
parser.add_argument('-a',action='store_true',default=False)
parser.add_argument('-b',action='store',dest='b')
parser.add_argument('-c',action='store',dest='c',type=int)
print(parser.parse_args())
#print(parser.parse_args(['-a','-bval','-c','3']))
命令行输入:
python test.py -a -b val -c 3
命令行输出:
Namespace(a=True, b='val', c=3)
2.7、开发模块
2.7.1 logging模块
日志:
日志的等级:DEBUG、INFO、NOTICE、WARNING、ERROR、CRITICIAL
日志的字段:时间点、代码位置、等级、事件信息
logging四大组件相关的类:Logger 日志器、Hanlder 处理器、Filter 过滤器、Formatter 格式器
import logging
LOG_FILENAME = 'logging_xeample.out'
logging.basicConfig(filename=LOG_FILENAME,level=logging.DEBUG)
logging.debug('this message should go to the logging file')
with open(LOG_FILENAME,'rt') as f:
body = f.readlines()
print('File:')
print(body)
输出:
File:
['i = 18\n', 'i = 19\n', 'DEBUG:root:this message should go to the logging file\n']import glob
import logging
import logging.handlers
LOG_FILENAME = 'logging_xeample.out'
my_logger = logging.getLogger('MyLogger')
my_logger.setLevel(logging.DEBUG)
handler = logging.handlers.RotatingFileHandler(LOG_FILENAME,maxBytes=20,backupCount=5)
my_logger.addHandler(handler)
for i in range(20):
my_logger.debug('i = %d',i)
logfiles = glob.glob('%s*'%LOG_FILENAME)
for filename in sorted(logfiles):
print(filename)
输出:
logging_xeample.out
logging_xeample.out.1
logging_xeample.out.2
logging_xeample.out.3
logging_xeample.out.4
logging_xeample.out.52.7.2 doctest模块
开发测试-单元测试模块
def my_function(a,b):
'''
>>> my_function(2,3)
6
>>> my_function('a',3)
'aaa'
'''
return a*b
import doctest
print(doctest.testmod())
输出:
TestResults(failed=0, attempted=2)
-----
def my_function(a,b):
'''
>>> my_function(2,3)
6
>>> my_function('a',3)
'aaa'
'''
return a*b
命令行输入:python -m doctest -v test.py
输出:
Trying:
my_function(2,3)
Expecting:
6
ok
Trying:
my_function('a',3)
Expecting:
'aaa'
ok
1 items had no tests:
test
1 items passed all tests:
2 tests in test.my_function
2 tests in 2 items.
2 passed and 0 failed.
Test passed.
2.7.3 unittest模块
1)导入unittest模块,被测文件或者其中的类
2)创建一个测试类,被继承unittest.TestCase
3)重写setUp和tearDown方法(如果有初始化条件和结束条件)
4)定义测试函数,函数名以test_开头。测试用例
5)在函数体中使用断言来判断测试结果是否符合预期结果
6)调用unittset.main()方法运行测试用例--------无此方法也是可以运行
参考:(写的非常详细)https://www.cnblogs.com/xiaoxiaolvdou/p/9503090.html
import unittest
class Test_Math(unittest.TestCase):
def setUp(self):
print("测试用例执行前的初始化操作========")
def tearDown(self):
print("测试用例执行完之后的收尾操作=====")
#正确的断言
def test_addTwoNum_01(self):
sum = 5+7
print(sum)
self.assertEqual(12,sum)
#设置错误的断言
def test_subTwoNum_02(self):
sub = 3-2
self.assertEqual(11,sub)
if __name__ == '__main__':
unittest.main()
输出:
#结果---直接打印出来失败的原因
Testing started at 10:14 ...
测试用例执行前的初始化操作========
测试用例执行完之后的收尾操作=====
测试用例执行前的初始化操作========
测试用例执行完之后的收尾操作=====
Failure
Traceback (most recent call last):
File "E:\柠檬班\python\python_API\unittest_lianxi.py", line 22, in test_subTwoNum_02
self.assertEqual(11,sub)
AssertionError: 11 != 1