(三)elasticsearch 7.6.0整合springboot 2.1.4实现模糊查询/精确查询/高亮查询
本文分为三部分, 第三部分是本文内容, 主要讲述与springboot整合使用
(一)elasticsearch7.6.0 集群搭建 elasticsearch-head Kibana搭建
(二)elasticsearch7.6.0 使用,常见增删改查功能语句
(三)elasticsearch 7.6.0整合springboot 2.1.4实现模糊查询/精确查询/高亮查询
Elasticsearch整合Springboot
- 1.创建springboot项目,版本选择2.1.x版本
- 1.1 创建springboot项目
- 2.添加整合elasticsearch需要用的jar包
- 3.配置restHighLevelClient客户端
- 4.创建工具类和实体类
- 4.1 controller方法接收的参数实体类
- 4.2Elasticsearch查询结果由json转换接收的实体类
- 4.3SpringBoot用于返回结果的工具类
- 5.创建Controller
- 6.使用Postman测试数据
- 6.1 模糊查询请求及返回结果
- 6.2 精确匹配查询请求及返回结果
- 7.使用vue查看高亮效果
- 7.1 模糊查询
- 7.2 精确匹配查询
- 8.总结
- 9.项目源码
整合时需要做以下几件事
1.创建springboot项目,版本选择2.1.x版本
1.1 创建springboot项目
我的开发工具使用的VSCode,这里简单介绍一下创建项目(使用IDEA或者Eclipse的患者,相信你们创建一个项目还是不需要看教程的,是在不会创建去查找一些别的文章,创建出来项目再继续看本篇)
VSCode中快捷键Ctrl+Shift+P即可调出窗口,里面第一个选项"Spring Initializr:Generate a Maven Project"
意为生成一个maven项目,点击即可

选择java

输入项目文件路径结构,输入完成之后回车

输入项目名称

选择springboot版本,这里注意选择2.1.13,稍后会在pom文件中改为2.1.4版本
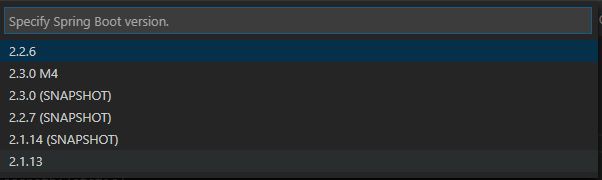
选择需要添加的插件,常用的有这四个

选择生成文件的路径,
生成完成之后添加到当前工作空间
项目创建完毕,对应手动创建一些实体类/配置类/controller/配置文件,目录结构如下

文件名及其功能介绍
| 序号 | 文件名 | 说明 |
|---|---|---|
| 1 | ElasticConfig.java | elasticsearch的客户端配置,用户获取客户端对象 |
| 2 | ElasticSearchController.java | controller控制器,里面对请求进行处理 |
| 3 | ElasticResult.java | 查询Elasticsearch返回的结果由json转换的实体类 |
| 4 | LibraryQuery.java | controller中用于接收参数的实体类 |
| 5 | ResultJSON.java | springBoot用于返回的实体类对象 |
| 6 | DemoApplication.java | 项目启动类,程序入口 |
| 7 | application-dev.yml | 配置elasticsearch的配置文件 |
| 8 | application.yml | 指定使用哪个配置 文件 |
2.添加整合elasticsearch需要用的jar包
整合elasticsearch需要添加一些必要的jar包, 具体pom文件如下
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.4.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.example.elastic.demo</groupId>
<artifactId>elasticsearch_demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>demo</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- *********************elasticsearch需要用的jar包 begin********************* -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.6.0</version>
<exclusions>
<exclusion>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
</exclusion>
<exclusion>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.6.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.6.0</version>
</dependency>
<!-- *********************elasticsearch需要用的jar包 end********************* -->
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
配置文件如下:
application.yml文件
spring:
profiles:
active: dev
application-dev.yml文件
server:
port: 8080
spring:
thymeleaf:
suffix: .html
prefix: classpath:/static/
jmx:
enabled: false
#--------------------------elasticsearch config start------------------------
data:
elasticsearch:
cluster-name: my-application
hosts: 192.168.5.32,192.168.5.33,192.168.5.34
port: 9200
scheme: http
timeout: 5000
jackson:
default-property-inclusion: NON_NULL
#----------------------------elasticsearch config end------------------------
这里配置的是三台机器搭建的集群, 具体集群搭建参考文章1
3.配置restHighLevelClient客户端
elasticsearch需要配置一个客户端,在对服务器进行操作时使用
建议各位自己写文章时, java类一定要把导包import的部分粘贴出来, 有时候初学者看着未识别的类文件, 真的不知道是哪个包里的
package com.example.elastic.demo.elasticsearch_demo.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ElasticConfig {
private static final Logger logger = LoggerFactory.getLogger(ElasticConfig.class);
@Value("${spring.data.elasticsearch.hosts}")
private String hosts;
@Value("${spring.data.elasticsearch.port}")
private int port;
@Value("${spring.data.elasticsearch.scheme}")
private String scheme;
@Value("${spring.data.elasticsearch.timeout}")
private int timeout;
@Bean(name = "highLevelClient")
public RestHighLevelClient restHighLevelClient() {
// 可以传httpHost数组
String[] hostArray = hosts.split(",");
logger.info("elasticsearch初始化配置开始");
RestClientBuilder builder = RestClient.builder(new HttpHost(hostArray[0], port, scheme),
new HttpHost(hostArray[1], port, scheme), new HttpHost(hostArray[2], port, scheme));
builder.setRequestConfigCallback(requestConfigBuilder -> {
// 设置超时
return requestConfigBuilder.setSocketTimeout(timeout);
});
logger.info("elasticsearch初始化配置完成");
return new RestHighLevelClient(builder);
}
}
这里配置类中对获取到的hosts进行了分割, 为的是配置文件直观简洁一些
4.创建工具类和实体类
工具类和实体类主要包括三个:
4.1 controller方法接收的参数实体类
package com.example.elastic.demo.elasticsearch_demo.entity;
public class LibraryQuery{
private int currentPage;
private int libraryId;
private String queryText;
private int pageSize;//页面显示数据条数,在系统参数中配置
public int getCurrentPage() {
return currentPage;
}
public void setCurrentPage(int currentPage) {
this.currentPage = currentPage;
}
public int getLibraryId() {
return libraryId;
}
public void setLibraryId(int libraryId) {
this.libraryId = libraryId;
}
public String getQueryText() {
return queryText;
}
public void setQueryText(String queryText) {
this.queryText = queryText;
}
public int getPageSize() {
return pageSize;
}
public void setPageSize(int pageSize) {
this.pageSize = pageSize;
}
}
4.2Elasticsearch查询结果由json转换接收的实体类
public class ElasticResult {
private String pwd;
private String index; // 索引
private int id;
private String shopcode;
public void setPwd(String pwd) {
this.pwd = pwd;
}
public String getPwd() {
return this.pwd;
}
public String getIndex() {
return index;
}
public void setIndex(String index) {
this.index = index;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getShopcode() {
return shopcode;
}
public void setShopcode(String shopcode) {
this.shopcode = shopcode;
}
}
4.3SpringBoot用于返回结果的工具类
import org.springframework.util.StringUtils;
public class ResultJSON {
// code 状态码: 成功:200,失败:500, 202登录失效
private String code;
// 错误信息
private String msg;
// 返回的数据
private Object responseData;
private int currentPage;// 当前页码
private int pageSize;// 每页数据条数
private int recordCount; // 总记录数
// 计算
private int pageCount; // 总页数
// 成功返回<无返回数据>
public static ResultJSON success() {
ResultJSON result = new ResultJSON("200", "操作成功", null);
return result;
}
// 成功返回<有返回数据>
public static ResultJSON success(Object responseData) {
ResultJSON result = new ResultJSON("200", "操作成功", responseData);
return result;
}
// 成功返回<返回分页数据>
public static ResultJSON success(int currentPage, int pageSize, int recordCount, Object responseData) {
ResultJSON result = new ResultJSON("200", "操作成功", responseData, currentPage, pageSize, recordCount);
return result;
}
// 代码抛异常
public static ResultJSON error(String string) {
ResultJSON result = new ResultJSON("200", string, null);
result.setCode("500");
if (StringUtils.isEmpty(string)) {
result.setMsg("操作失败");
}
return result;
}
// 自定义返回状态及返回数据
public ResultJSON(String code, String msg, Object responseData) {
this.code = code;
this.msg = msg;
this.responseData = responseData;
}
// 自定义返回分页状态及返回数据
public ResultJSON(String code, String msg, Object responseData, int currentPage, int pageSize, int recordCount) {
this.currentPage = currentPage;
this.pageSize = pageSize;
this.recordCount = recordCount;
this.code = code;
this.msg = msg;
this.responseData = responseData;
}
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
public String getMsg() {
return msg;
}
public void setMsg(String msg) {
this.msg = msg;
}
public Object getResponseData() {
return responseData;
}
public void setResponseData(Object responseData) {
this.responseData = responseData;
}
public int getCurrentPage() {
return currentPage;
}
public void setCurrentPage(int currentPage) {
this.currentPage = currentPage;
}
public int getPageSize() {
return pageSize;
}
public void setPageSize(int pageSize) {
this.pageSize = pageSize;
}
public int getRecordCount() {
return recordCount;
}
public void setRecordCount(int recordCount) {
this.recordCount = recordCount;
}
public int getPageCount() {
if (this.recordCount > 0) {
if (this.recordCount % this.pageSize == 0) {
this.pageCount = this.recordCount / this.pageSize;
return pageCount;
}
this.pageCount = this.recordCount / this.pageSize + 1;
return pageCount;
}
return 0;
}
public void setPageCount(int pageCount) {
this.pageCount = pageCount;
}
}
5.创建Controller
import static org.elasticsearch.index.query.QueryBuilders.matchQuery;
import java.io.IOException;
import java.util.LinkedList;
import java.util.List;
import javax.annotation.Resource;
import com.example.elastic.demo.elasticsearch_demo.entity.ElasticResult;
import com.example.elastic.demo.elasticsearch_demo.entity.LibraryQuery;
import com.example.elastic.demo.elasticsearch_demo.entity.ResultJSON;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.core.CountRequest;
import org.elasticsearch.client.core.CountResponse;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/elastic")
public class ElasticSearchController {
@Resource(name = "highLevelClient")
private RestHighLevelClient client;
public ElasticSearchController() {
}
/**
* @Author: wangran
* @Date: 2020-04-14 14:46:41
* @msg: 模糊查询
* @param {type}
* @return:
*/
@RequestMapping("/searchMatch")
public ResultJSON searchMatch(LibraryQuery query) throws IOException {
String index = "es-test-query-analyzer";// 测试环境使用固定的索引
String fieldName = "shopcode";// 使用固定的列
String queryText = query.getQueryText();// 获取查询的文本内容
String preTag = "";// 高亮查询, 使用google的色值
String postTag = "";
SearchRequest searchRequest = new SearchRequest(index);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
int pageNum = (query.getCurrentPage() - 1) * query.getPageSize();
searchSourceBuilder.query(matchQuery(fieldName, queryText))
.highlighter(new HighlightBuilder().field(fieldName).preTags(preTag).postTags(postTag));// 需要设置对应的列名和标签前/后缀
searchSourceBuilder.from(pageNum);// 起始记录
searchSourceBuilder.size(query.getPageSize());// 返回结果数量
searchRequest.source(searchSourceBuilder);
SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);
List<ElasticResult> queryList = new LinkedList<>();// ElasticResult类型为实体类,接收json转换后的对象
for (SearchHit searchHit : response.getHits()) {
if (response.getHits().getHits().length <= 0) {
return null;
}
ElasticResult esResult = new ElasticResult();
HighlightField esField = searchHit.getHighlightFields().get(fieldName);
if (esField != null) {
esResult.setShopcode(esField.fragments()[0].toString());
}
esResult.setIndex(index);
queryList.add(esResult);
}
Long count = this.count(index, fieldName, queryText);
// 由于elasticsearch在创建索引时, 默认查询数目需要小于10000, 这个值可以通过设置去改变,
//但是改变也是有上限的, 不能修改为无限大, 亲测百亿数据时,就已经设置不了了,10亿还是没问题的,
//如果10亿可以满足需求,那么可以设置,如果还是满足不了需求,可以跟我一样,最多让用户查询10000条
//因为用户查询时,模糊查询只会关心第一页的前几条,如果没有想要的结果,他会尽量的把搜索文本补充一些
// 所以10000条记录足够用了(注意count时Long类型的数据,这里需要转换为int类型)
return ResultJSON.success(pageNum, query.getPageSize(), count > 10000 ? 10000 : count.intValue(), queryList);
}
/**
* @Author: wangran
* @Date: 2020-04-14 14:46:41
* @msg: 精确匹配查询
* @param {type}
* @return:
*/
@RequestMapping("/searchMatchKeyWord")
public ResultJSON searchMatchKeyWord(LibraryQuery query) throws IOException {
String index = "es-test-query-analyzer";
String fieldKeyWord = "shopcode.keyword"; // 精确查询需要使用.keyword
String queryText = query.getQueryText();
SearchRequest searchRequest = new SearchRequest(index);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
String preTag = "";// google的色值
String postTag = "";
int pageNum = (query.getCurrentPage() - 1) * query.getPageSize();
searchSourceBuilder.query(matchQuery(fieldKeyWord, queryText))
.highlighter(new HighlightBuilder().field(fieldKeyWord).preTags(preTag).postTags(postTag)); // 精确查找
searchSourceBuilder.from(pageNum);// 起始记录
searchSourceBuilder.size(query.getPageSize());// 返回结果数
searchRequest.source(searchSourceBuilder);
SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);
List<ElasticResult> queryList = new LinkedList<>();
for (SearchHit searchHit : response.getHits()) {
if (response.getHits().getHits().length <= 0) {
return null;
}
ElasticResult esResult = new ElasticResult();
HighlightField esField = searchHit.getHighlightFields().get(fieldKeyWord);
if (esField != null) {
esResult.setShopcode(esField.fragments()[0].toString());
}
esResult.setIndex(index);
queryList.add(esResult);
}
Long count = this.count(index, fieldKeyWord, queryText);
return ResultJSON.success(pageNum, query.getPageSize(), count > 10000 ? 10000 : count.intValue(), queryList);
}
/**
* @Author: wangran
* @Date: 2020-04-14 15:22:27
* @msg: 获取查询结果的总记录数
* @param {type}
* @return:
*/
public Long count(String index, String name, String text) throws IOException {
CountRequest countRequest = new CountRequest(index);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(matchQuery(name, text));
countRequest.source(searchSourceBuilder);
CountResponse countResponse = client.count(countRequest, RequestOptions.DEFAULT);
long count = countResponse.getCount();
return count;
}
}
这里需要注意, 模糊查询和精确查询只有一个区别,那就是对同一个索引的同一个字段进行搜索, 但是在搜索的列上面有所区别, 模糊查询使用的是"shopcode"字段,精确匹配查询使用的是"shopcode.keyword"字段,这个需要在elasticsearch创建索引时, 对该字段进行设置, 将其设置为多类型字段, 参考文章
这里介绍了关于分词器的使用,多类型字段的创建和查询等,需要有这个设置的前提下, 才能实现模糊查询和精确查询
6.使用Postman测试数据
6.1 模糊查询请求及返回结果

{
"code": "200",
"msg": "操作成功",
"responseData": [
{
"index": "es-test-query-analyzer",
"id": 0,
"shopcode": "a@orange.es:orange"
},
{
"index": "es-test-query-analyzer",
"id": 0,
"shopcode": "em@orange.fr:orange"
},
{
"index": "es-test-query-analyzer",
"id": 0,
"shopcode": "h-as@orange.fr:orange"
},
{
"index": "es-test-query-analyzer",
"id": 0,
"shopcode": "orange2b@orange.nl:orange4y"
},
{
"index": "es-test-query-analyzer",
"id": 0,
"shopcode": "jbell@orange.ca:orange"
},
{
"index": "es-test-query-analyzer",
"id": 0,
"shopcode": "mayen.jm@orange.fr:Orange"
},
{
"index": "es-test-query-analyzer",
"id": 0,
"shopcode": "orange@hvdm.nl:orange1"
},
{
"index": "es-test-query-analyzer",
"id": 0,
"shopcode": "wahiba.n@orange.fr:ORANGE"
},
{
"index": "es-test-query-analyzer",
"id": 0,
"shopcode": "orange[email protected]:orange"
},
{
"index": "es-test-query-analyzer",
"id": 0,
"shopcode": "a.orange@ew-inc.com:orange1"
}
],
"currentPage": 0,
"pageSize": 10,
"recordCount": 10000,
"pageCount": 1000
}
可以看到使用高亮查询的结果中,匹配到的结果已经有了标签高亮, 实际使用中,在前台处理一下标签就可以了
6.2 精确匹配查询请求及返回结果

{
"code": "200",
"msg": "操作成功",
"responseData": [
{
"index": "es-test-query-analyzer",
"id": 0,
"shopcode": "[email protected]:single3"
}
],
"currentPage": 0,
"pageSize": 10,
"recordCount": 1,
"pageCount": 1
}
精确匹配查询时,如果使用部分内容进行查询,是没有返回结果的
道理就是 keyword类型的文本是不分词的, 而text类型的文本是会进行分词的, 如果是邮箱类型的数据,需要自定义分词器, 如果是中文类型的分词器,可以使用ik分词器,这里因为功能需求中需要使用的模糊查询和精确查询, 所以这里对shopcode字段设置多类型,满足既可以分词模糊查询又可以精确匹配, 多类型字段还有很多亮点, 这里没有用到就不介绍了, 有兴趣的可以自己查找一下资料
7.使用vue查看高亮效果
7.1 模糊查询
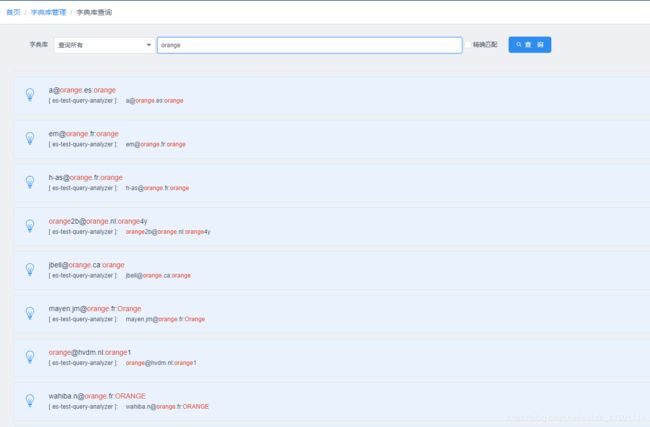
在前面介绍过, 查询结果数量超过10000条时,默认只显示10000条

7.2 精确匹配查询
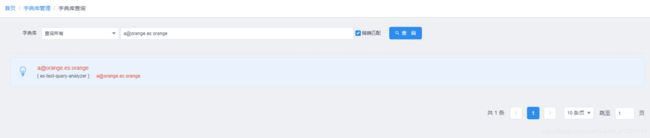
在导入数据时, 对保存格式进行了响应的处理,elasticsearch有一个特点就是当插入的数据_id相同时,如果重复插入会修改原有的值, 那么在海量数据时, 把需要去重的字段赋值给_id就可以满足数据清洗工作, 将重复的内容去掉.所以这里精确查询时,返回结果若不存在则结果为0条, 如果有结果那肯定是只有1条
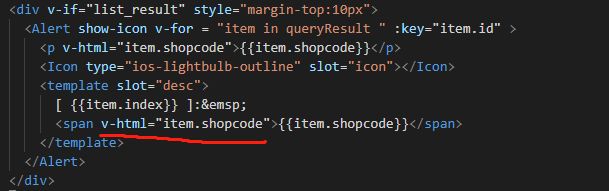
vue中处理字符串类型的标签文本使用如下方式就可以
8.总结
Elasticsearch是一个很高效率的搜索引擎, 从搭建到性能调优,到整合项目,最后实际使用, 从零开始真的是很需要时间和精力去学习, 越是新版本的elasticsearch, 对应的文章介绍就越少,需要自己摸索的东西就越多,加油努力吧!
9.项目源码
源码下载