scrapy自带文件下载器,实现多层级目录结构的存储
概scrapy既然是一款强大的爬虫框架,自然也实现了图片和文件的下载,FilesPipeline、ImagesPipeline分别是图片和文件的下载器,image也是文件的一种为什么还要单独提供一个image下载器?这是因为图片下载器还提供了一些额外方法:缩略图生成、图片过滤;今天就来介绍这两款特殊的下载器。
使用方法
1.常规的使用方法是首先在item中定义关键字,images和files关键字段如下:
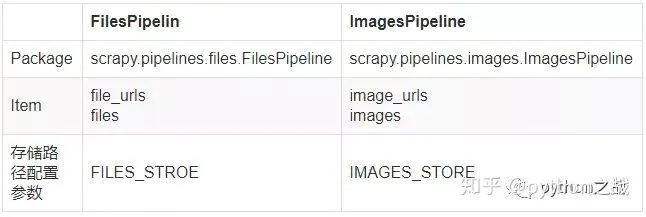
image
当然其中字段还可以增加可以加title、Word等自定义字段
2.在setting.py中启用下载管道
ITEM_PIPELINES = { 'scrapy.pipelines.files.FilesPipeline': 1, 'scrapy.pipelines.images.ImagesPipeline': 2}
上面启用的是内部的下载器,如果实现了自定义需要将路径替换为自定义的下载器
3.在爬虫主程序中传递url,yield item{'file_urls':[url1, url2,`````````]}
下面将从源码和案例来分析具体如何使用
注:file下载和image下载的原理是一样的,只是images下载图片可以配置,所以我们分析file的源码,讲image的实例
FilesPipeline源码
FilesPipeline文件位于:
scrapy.pipelines.files
源码有点多,我们只需要关注两个地方,一个是下载的实现一个是下载的文件命名
class FilesPipeline(MediaPipeline):
"""Abstract pipeline that implement the file downloading
This pipeline tries to minimize network transfers and file processing,
doing stat of the files and determining if file is new, uptodate or
expired.
`new` files are those that pipeline never processed and needs to be
downloaded from supplier site the first time.
`uptodate` files are the ones that the pipeline processed and are still
valid files.
`expired` files are those that pipeline already processed but the last
modification was made long time ago, so a reprocessing is recommended to
refresh it in case of change.
"""
### Overridable Interface
def get_media_requests(self, item, info):
return [Request(x) for x in item.get(self.files_urls_field, [])]
def file_path(self, request, response=None, info=None):
## start of deprecation warning block (can be removed in the future)
def _warn():
from scrapy.exceptions import ScrapyDeprecationWarning
import warnings
warnings.warn('FilesPipeline.file_key(url) method is deprecated, please use '
'file_path(request, response=None, info=None) instead',
category=ScrapyDeprecationWarning, stacklevel=1)
# check if called from file_key with url as first argument
if not isinstance(request, Request):
_warn()
url = request
else:
url = request.url
# detect if file_key() method has been overridden
if not hasattr(self.file_key, '_base'):
_warn()
return self.file_key(url)
## end of deprecation warning block
media_guid = hashlib.sha1(to_bytes(url)).hexdigest() # change to request.url after deprecation
media_ext = os.path.splitext(url)[1] # change to request.url after deprecation
return 'full/%s%s' % (media_guid, media_ext)
其中get_media_requests用于解析item中的file_urls字段里的url列表,并构造成请求
file_path是给文件命名,使用的url的sha1散列值也我们只需要让return返回我们想要的文件名即可。
图片下载的关键源码同上。
image自定义下载路径及文件名实例
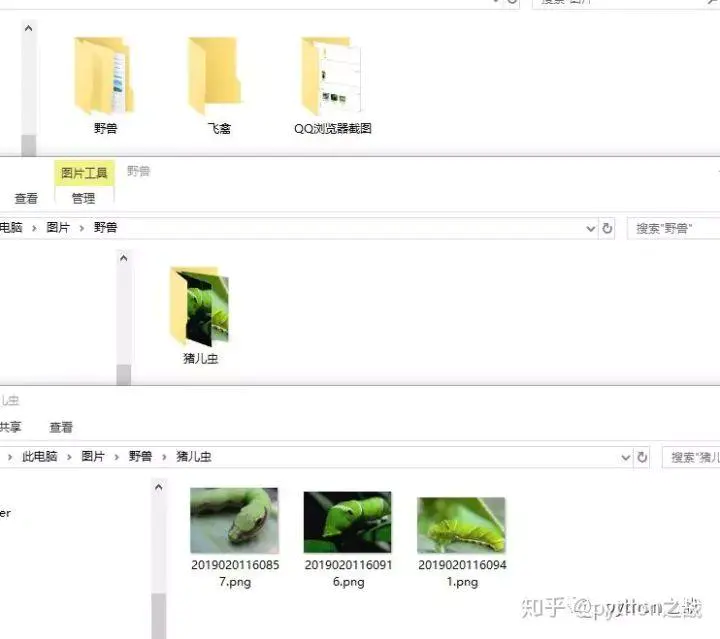
目标:下载图片按照原网站的文件目录组织结构、文件名按照原网站命名,本地生成缩略图,小于200*200以下的文件。
目标明确就开工,先创建一个项目模板,然后开始做我们的案例。
案例图片是类似于妹子图的组图网站,不过内容不宜展示,并且网站也被封了,就不在其中展示敏感内容,这是以前的案例。
items.py 定义字段
import scrapy
class RgspoiderItem(scrapy.Item):
image_urls = scrapy.Field()
images = scrapy.Field()
title = scrapy.Field()
word = scrapy.Field()
title是分类名字,Word是组图的专题名字, 组图下载后将按照分类-专题-组图的目录结构存储,是三层结构。
Spider.py 爬虫主程序
# -*- coding: utf-8 -*-
import scrapy
from ..items import RgspoiderItem
class PicturnSpider(scrapy.Spider):
name = 'picturn'
allowed_domains = ['xxxxxx.com']
start_urls = ['http://xxxxxx/index.html']
def parse(self, response):
select = response.xpath('//*[@id="body"]/div[2]/ul//li')
for i in select:
URL = i.xpath('a/@href').extract()[0]
title = i.xpath('a/text()').extract()[0] # 获取分类名字并专递给解析函数
yield scrapy.Request(
response.urljoin(URL), callback=self.parse_ml, meta={'title': title})
def parse_ml(self, response):
mulu = response.xpath('//li[@class="zxsyt"]/a')
title = response.meta['title']
for i in mulu:
urls = i.xpath('@href').extract()[0]
word = i.xpath('text()').extract()[0]
yield scrapy.Request(
response.urljoin(urls), callback=self.parse_pict,
meta={'word': word, 'title': title}) # 将分类名字及其组图标题在传递给解析函数
next_url = response.xpath('//font[@class="PageCss"]/..//a/@href').extract()
for nuel in next_url:
title = response.meta['title']
yield scrapy.Request(response.urljoin(nuel), callback=self.parse_ml,
meta={'title': title})
def parse_pict(self, response):
items = RgspoiderItem()
items['title'] = response.meta['title']
items['word'] = response.meta['word']
pict = response.xpath('//div[@class="temp23"]//a/@href').extract()
items['image_urls'] = pict # 构造item数据传递给下载器,item包含了单张图片,并附带该图片所在分类和组图标题,后面自动归类
yield items
主程序实现了三层解析,第一层获取所有分类连接及其分类名字,第二层获取所有分类下的组图连接及其组图标题,第三层获取组图下的所有图片连接并将连接、分类、标题传递给下载器
pipeline.py 复写imagespipeline
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
from scrapy.pipelines.images import ImagesPipeline
import scrapy
class RgspoiderPipeline(ImagesPipeline):
def get_media_requests(self, items, info):
print(items)
title = items['title']
word = items['word']
for image_url in items['image_urls']:
yield scrapy.Request(image_url, meta={'title': title, 'word': word}) # 继续传递分类、标题
def file_path(self, request, response=None, info=None):
# 按照full\分类\标题\图片合集命名
filename = r'full\%s\%s\%s' % (request.meta['title'], request.meta['word'], request.url[-6:])
return filename
现在get_media_requests狗仔request请求,然后在file_path中解析构造的request请求中的meta字段来构建文件名字,并取url的后几个字符串作为组图中单张图片的名字。
setting.py
ITEM_PIPELNES={
'rgSpoider.pipelines.RgspoiderPipeline': 1,
}
IMAGES_STORE = 'D://A' # 问价存放的根目录
IMAGES_THUMBS = {
'thumbnail': (50, 50) # 生成缩略图标签及其尺寸
}
IMAGES_MIN_WIDTH = 200 # 过滤宽度小于200
IMAGES_MIN_HEIGHT = 300 # 过滤高度小于300
image
![]()
image
—END—