Java IO
文章目录
- 一、File文件操作类
- 1.1 File类的使用
- 1.2 目录操作
- 1.3 文件信息
- 1.4 综合案例(目录列表)
- 二、字节流与字符流
- 2.1 流操作简介
- 2.2 字节输出流(OutputStream)
- 2.3 AutoCloseable 自动关闭支持
- 2.3 字节输入流 (InputStream)
- 2.4 字符输出流 Writer
- 2.5 字符输入流 Reader
- 2.6 字节流 VS 字符流
- 三、转换流
- 3.1 转换流的基本使用
- 3.2 综合演练:文件拷贝(重要)
- 四、字符编码
- 4.1 常用字符编码
- 4.2 乱码产生分析
- 五、内存操作流
- 5.1 内存流概念
- 5.2 内存流操作
- 六、打印流
- 6.1 打印流的概念
- 6.2 使用系统提供的打印流
- 6.3 格式化输出
- 七、System类对IO的支持
- 7.1 系统输出
- 7.2 系统输入
- 八、两种输入流
- 8.1 BufferedReader类
- 8.2 java.util.Scanner类
Java IO 的核心组成就是五个类:File、OutputStream、InputStream、InputStream、Reader 、Writer 和 一个接口 Serializable。
一、File文件操作类
1.1 File类的使用
在 java.io 包中,FIle 类是唯一一个 与文件本身操作(创建、删除、取得信息)有关的程序类。
- 构造方法:
public File(String pathname)
public File(File parent, String child)
public File(String parent, String child)
public File(URI uri)
- ✨判断文件是否存在 ✨:
public boolean exists() {
- ✨删除文件✨:
public boolean delete() {
- 创建一个新文件
(如果文件不存在则进行创建,如果已存在则删除)
public class TestIO {
public static void main(String[] args) throws IOException {
//定义要操作的文件路径
File file=new File("/jia/files/TestIO.java");
//如果文件存在
if(file.exists())
{
//删除文件
file.delete();
}
else
{
file.createNewFile();
}
}
}
可以看到执行成功,在指定路径下新建了文件,目前这个文件的内容为空:

以上实现了最简化的文件处理操作,但是代码存在两个问题:
(1) 实际项目部署环境与开发环境不同。那么这个时候路径的问题就很麻烦了。Windows 下使用的是 “\”,而 Unix 系统下使用的是 “/”,所以在使用路径分隔符时,都会采用 File 类的一个常量 public static final String separator 来描述。
File file=new File(File.separator+"jia"+File.separator+"files"+File.separator+"TestIO.java");
这样 separator 会由不同操作系统下的 JVM 来决定使用那种杠杠。
(2) 在 Java 中要进行文件的处理操作是要通过本地操作系统支持的,在这之中如果操作的是同名文件,就可能出现延迟的问题。(开发中尽可能避免文件重名的问题)(解决文件名重复可以给文件添加不同的后缀 1、2、3… 或者以时间戳/随机数的方式命名。)
1.2 目录操作
- ✨取得父路径✨:
public String getParent() {
- ✨取得父File对象✨:
public File getParentFile() {
- ✨创建父路径:(无论有多少级父目录,都会创建)✨:
public boolean mkdirs() {
public class TestIO {
public static void main(String[] args) throws IOException {
//定义要操作的文件路径
File file=new File(File.separator+"jia"+File.separator+"files"+File.separator+"TestIO.java");
//如果父目录不存在
if(!file.getParentFile().exists())
{
//有多少级父目录就创建多少级
file.getParentFile().mkdirs();
}
if(file.exists())
//文件存在就进行删除
file.delete();
else
{
file.createNewFile();
}
}
}
要操作的文件是TestIO.java,它的父路径是\jia\files。
1.3 文件信息
在 File 类里提供一系列取得文件信息的操作:
- 判断路径是否是文件:
public boolean isFile() {
- 判断路径是否是目录:
public boolean isDirectory() {
- 取得文件大小(字节):
public long length() {
- 最后一次修改日期:
public long lastModified() {
取得文件信息实例:
public class TestIO {
public static void main(String[] args) throws IOException {
//定义要操作的文件路径
File file=new File(File.separator+"jia"+File.separator+"files"+File.separator+"TestIO.java");
//保证文件存在再进行操作
if(file.exists()&&file.isFile())
{
System.out.println("文件大小:"+file.length());
System.out.println("最后一次修改时间:"+new Date(file.lastModified()));
}
}
}
运行结果:

以上操作是针对文件进行信息取得,Java 里也提供了以下方法 列出一个目录的全部组成:
public File[] listFiles() {
实例:
public class TestIO {
public static void main(String[] args) throws IOException {
//定义要操作的文件路径
File file=new File(File.separator+"jia"+File.separator+"files");
//保证目录存在再进行操作
if(file.exists()&&file.isDirectory())
{
//列出目录中全部内容
File[] result=file.listFiles();
for(File file1:result)
{
System.out.println(file1);
}
}
}
}
运行结果:

listFiles() 方法只能列出本目录中的第一级信息,比如,在 jia 文件夹下新增一个目录 otherFiles:

如果把定义的操作路径改为:
File file=new File(File.separator+"jia";
运行结果只能看到 \jia\files,即 “第一级信息”,如果要求列出目录中所有级的信息,必须自己来处理,这种操作就必须通过递归的模式完成:
1.4 综合案例(目录列表)
public class TestIO {
public static void main(String[] args) throws IOException {
//定义要操作的文件路径
File file = new File(File.separator + "jia" );
//从此处开始递归
listAllFiles(file);
}
/**
* 列出指定目录中的全部子目录信息
* @param file
*/
public static void listAllFiles(File file)
{
//如果给定的file对象属于目录
if(file.isDirectory()) {
//继续列出子目录内容
File[] result = file.listFiles();
if (result != null) {
for (File file2 : result) {
listAllFiles(file2);
}
}
}
else
{
//给定的 file 是文件,可以打印
System.out.println(file);
}
}
}
运行结果:
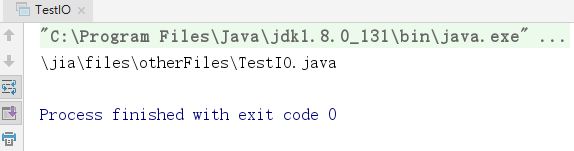
——线程阻塞问题
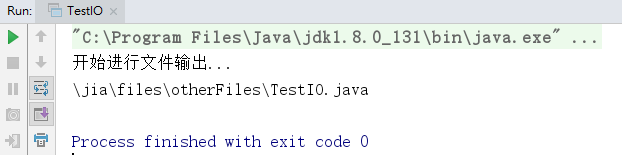
现在所有代码在 main 线程下完成的,如果 listAllFiles() 方法没有完成,那么对于 main 后续的执行将无法完成,这种耗时的操作让主线程出现了阻塞,而导致后续代码无法正常执行完毕。如果不想让阻塞产生,最好再产生一个新的线程进行处理。
示例:新增子线程进行耗时操作:
public class TestIO {
public static void main(String[] args) throws IOException {
//开启子线程进行列出处理
new Thread(() ->
{ //定义要操作的文件路径
File file = new File(File.separator + "jia");
//定义要操作的文件路径
listAllFiles(file);
}, "输出线程").start();
System.out.println("开始进行文件输出...");
}
/**
* 列出指定目录中的全部子目录信息
* @param file
*/
public static void listAllFiles(File file)
{
//如果给定的file对象属于目录
if(file.isDirectory()) {
//继续列出子目录内容
File[] result = file.listFiles();
if (result != null) {
for (File file2 : result) {
listAllFiles(file2);
}
}
}
else
{
//给定的 file 是文件,可以打印
System.out.println(file);
}
}
}
二、字节流与字符流
2.1 流操作简介
File 类不支持 文件内容处理,如果 要处理文件内容 ,必须要通过 流 的操作模式来完成。 流分为 输入流 和 输出流。
在 java.io 包中,流分为两种:字节流 与 字符流。
1. 字节流:InputStream、OutputStream
2. 字符流:Reader、Writter
字节流 与 字符流 操作的本质区别只有一个:
字节流是原生的操作,字符流是经过处理后的操作。
在进行网络数据传输、磁盘数据保存所支持的数据类型只有 字节。而所有磁盘中的数据必须先读取到内存后才能进行操作,而内存中会帮助我们把字节变为字符。字符更加适合处理中文。
不管使用的是 字节流 还是 字符流,其基本的操作流程几乎是一样的,以 文件操作为例:
1. 根据文件路径创建 File 类对象。
2. 根据字节流或字符流的子类实例化父类对象。
3. 进行数据的读取或写入操作。
4. 关闭 close 流。
(对于 IO 操作属于资源处理,所有的资源处理操作(IO操作、数据库操作、网络)最后都必须进行关闭。)
2.2 字节输出流(OutputStream)
public abstract class OutputStream implements Closeable, Flushable {
OutputStream 是个抽象类,实现了 Closeable 接口,该接口的方法: public void close() throws IOException; ;实现了 Flushable 接口,该接口的方法: void flush() throws IOException; 。除此之外,OutputStream 还定义了其他方法:
- 将给定的字节数组内容全部输出(它这个“输出”,是写入到文件的意思,即 “输出到文件”。):
public void write(byte b[]) throws IOException {
- 将部分字节数组内容输出:
public void write(byte b[], int off, int len) throws IOException {
- 输出单个字节:
public abstract void write(int b) throws IOException;
OutputStream 的子类有 FileOutputStream,其构造方法:
- 接受 File 类(覆盖):
public FileOutputStream(File file) throws FileNotFoundException {
- 接受 File 类(追加):
public FileOutputStream(File file, boolean append)
示例:实现文件的内容输出:
public class TestIO {
public static void main(String[] args) throws IOException {
//定义要操作的文件路径
File file = new File(File.separator + "jia" + File.separator + "files" + File.separator + "hello.text");
//保证父目录存在
if (!file.getParentFile().exists()) {
//创建多级父目录
file.getParentFile().mkdirs();
}
OutputStream outputStream = new FileOutputStream(file);
//要求输出到文件的内容
String msg = "This is Hello.text ";
//将内容变为字节数组
outputStream.write(msg.getBytes());
//关闭输出
outputStream.close();
}
}
运行结果:
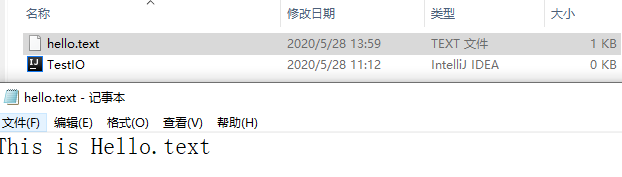
而且在进行文件输出的时候,所有的文件会自动帮助用户创建,不再需要调用 creatFile( )方法手动创建。 这时如果程序重复执行,并不会出现内容追加的情况,而是一直覆盖。如果需要进行内容的追加,需要调用 FileOutput 提供的另一种构造方法:
![]()
如果只想输出部分内容:

2.3 AutoCloseable 自动关闭支持
JDK 1.7 追加了一个 AutoCloseable 接口,这个接口的主要目的是 自动进行关闭处理,但是这种处理一般不好用,因为必须结合 try catch,语法结构比较混乱,还是推荐使用 close() 方法手动关闭资源,示例:
class Message implements AutoCloseable
{
public Message()
{System.out.println("创建一条新的消息");}
@Override
public void close() throws Exception {
System.out.println("AutoCloseable 自动关闭方法");
}
public void print()
{System.out.println("print方法");}
}
public class TestAutoClose {
public static void main(String[] args) {
try(Message msg=new Message();)
{
msg.print();
} catch (Exception e) {
e.printStackTrace();
}
}
}
2.3 字节输入流 (InputStream)
使用 InputStream 类在程序中读取文件内容。
public abstract class InputStream implements Closeable {
- 读取数据到字节数组中,返回数据的读取个数:
public int read(byte b[]) throws IOException {
如果此时开辟的字节数组的大小 大于 读取数据的大小,则返回数据的读取个数;
如果要读取的数据 大于 数组的大小,那么返回的就是数组的长度。
如果没有数据了还读取,返回 -1;
- 读取数据到字节数组中,每次只读取部分内容:
public int read(byte b[], int off, int len) throws IOException {
如果读取满了就返回长度 len,否则返回读取的数据个数;
如果读取到最后没有数据了,返回 -1。
- 读取单个字节,每次读取一个字节的内容,直到没有了返回 -1:
public abstract int read() throws IOException;
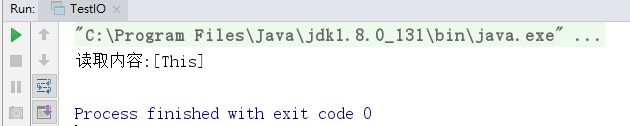
示例:实现文件信息的读取:
public class TestIO {
public static void main(String[] args) throws IOException {
//定义要操作的文件路径
File file = new File(File.separator + "jia" + File.separator + "files" + File.separator + "hello.text");
InputStream inputStream=new FileInputStream(file);
byte[] data=new byte[1024];
//返回读取的数据个数
int length=inputStream.read(data);
String result=new String(data,0,length);
System.out.println("读取内容:["+result+"]");
inputStream.close();
}
}
2.4 字符输出流 Writer
字符适合于处理中文数据,Writer 是字符输出流的处理类,这个类的定义:
public abstract class Writer implements Appendable, Closeable, Flushable {
Writer 类中也有 write 方法,它的构造方法和 write 方法和 OutputStream 的相似,只是 Writer 类 对于中文的支持很好,并且提供了直接写入 String 的方法:
public void write(String str, int off, int len) throws IOException {
如果要操作文件使用 FileWritter 子类,示例:
public class TestWriter {
public static void main(String[] args) throws IOException {
File file=new File(File.separator+"jia"+File.separator+"files"+File.separator+"hello.text");
//必须保证父目录存在
if(!file.getParentFile().exists())
{
//创建多级父目录
file.getParentFile().mkdirs();
}
String msg="ohh";
Writer out=new FileWriter(file);
out.write(msg);
/*
所有 字符流 的操作,无论是输入还是输出,数据都先保存在 缓存 中。
如果字符流不关闭,数据就可能保存在缓存中并没有输出到目标源,这种情况下必须强制刷新 ,才能够得到完整数据。
//表示强制清空缓存内容,所有内容均输出
out.flush();
*/
out.close();
}
}
2.5 字符输入流 Reader
Reader 也是一个抽象类,如果要进行文件读取,同样要使用 FileReader。
之前的 Writer 可以直接向目标源中写入字符串,但是 Reader 类中并没有方法可以直接读取字符串,只能通过字符串数组进行读取操作。
示例:
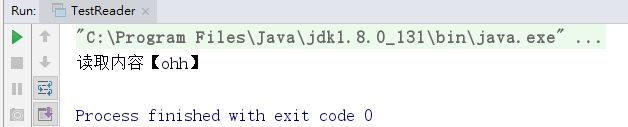
public class TestReader {
public static void main(String[] args) throws IOException {
File file=new File(File.separator+"jia"+File.separator+"files"+File.separator+"hello.text");
if(file.exists())
{
Reader in=new FileReader(file);
char[] data=new char[1024];
int length=in.read(data);
String result=new String(data,0,length);
System.out.println("读取内容【"+result+"】");
in.close();
}
}
}
运行结果:
2.6 字节流 VS 字符流
从上述一系列示例可以看出,使用字节流 和 使用字符流 在代码形式上区别不大,但是如果从实际开发来说,字节流一定是优先考虑的。只有在 处理中文时 才会考虑字符流。 因为所有的 字符 都需要通过内存 缓冲 来进行处理。(所以使用 字符流 的时候,需要使用 flush() 方法,强制清空缓冲内容,所有内容都输出。)
三、转换流
3.1 转换流的基本使用
字节流 和 字符流 相互可以进行转换处理:
- OutputStreamWriter:
将字节输出流 转换 成 字符输出流。
(Writer 对于 文字的 输出 比 OutputStream 方便。) - InputStreamReader:
将字节输入流 转换成 字符输入流。
(InputStream 读取的是字节,不方便中文的处理。)
3.2 综合演练:文件拷贝(重要)
class CopyFile1 {
private CopyFile1() {
}
/**
* 判断要拷贝的源文件是否存在
*
* @param path 输入的源路径信息
* @return 如果该路径真实存在返回 true,否则返回 false
*/
public static boolean fileIsExits(String path) {
return new File(path).exists();
}
public static void createParentsDir(String path) {
File file = new File(path);
//如果路径不存在
if (!file.getParentFile().exists())
//创建多级父目录
{
file.getParentFile().mkdirs();
}
}
/**
*
* @param sourcePath 源文件路径
* @param destPath 目标文件路径
* @return 是否拷贝成功
*/
public static boolean copyFile(String sourcePath,String destPath)
{
File inFile=new File(sourcePath);
File outFile=new File(destPath);
FileInputStream fileInputStream=null;
FileOutputStream fileOutputStream=null;
try
{
fileInputStream=new FileInputStream(inFile);
fileOutputStream=new FileOutputStream(outFile);
copyFileHandle(fileInputStream,fileOutputStream);
} catch (IOException e) {
e.printStackTrace();
return false;
}
finally {
try {
fileInputStream.close();
fileOutputStream.close();
}
catch (IOException e) {
e.printStackTrace();
}
}
return true;
}
/**
* 实现具体的文件拷贝操作
* @param inputStream 输入流对象
* @param outputStream 输出流对象
*/
private static void copyFileHandle(InputStream inputStream,OutputStream outputStream) throws IOException {
long start=System.currentTimeMillis();
int temp=0;
/*
*核心代码
* 后续在文件中上传就是这种模式
*/
//开启缓冲区一次性读入多个内容
byte[] data=new byte[1024];
int len=0;
/*
在开发里尽量不要使用 do while ,尽量去使用while
*/
/*
do {
//读取单个字节数据
temp=inputStream.read();
//通过输出流输出
outputStream.write(temp);
}
//如果有数据继续读取
*/
//判断这个读取后的字节(保存在 temp )中是否为 -1,如果不是表示有内容
while ((temp=inputStream.read())!=-1)
{
outputStream.write(temp);
}
long end = System.currentTimeMillis();
System.out.println("拷贝文件所花费的时间:"+(end-start)+"ms");
}
}
public class CopyFile {
public static void main(String[] args) {
//如果参数不是两个
if(args.length!=2)
{System.out.println("非法操作:命令为 java CopyFile 源文件路径 目标文件路径");
return;}
//取得源文件路径
String sourPath=args[0];
//取得目标文件路径
String destPath=args[1];
if(CopyFile1.fileIsExits(sourPath))
{ //创建目录
CopyFile1.createParentsDir(sourPath);
System.out.println(CopyFile1.copyFile(sourPath,destPath)?"文件拷贝成功":"文件拷贝失败");
}
else {
System.out.println("文件不存在,无法进行拷贝");
}
}
}
四、字符编码
4.1 常用字符编码
常见的编码:
1. GBK、GB2312:表示的是国标编码,GBK 包含简体中文和繁体中文,而GB2312只包含简体中文。也就是说,这两种编码都是描述 中文 的编码。
2. UNICODE 编码:Java 提供的 16 进制编码,可以描述世界上任意的文字信息,但是有个问题,如果现在所有的字母也都使用16进制编码,那么这个编码太庞大了,会造成网络传输的负担。
3. ISO8859-1:国际通用编码,但是所有的编码都需要进行转换。
4. UTF编码:相当于结合了 UNICODE、ISO8859-1,也就是说需要使用到 16 进制文字使用 UNICODE,而如果只是字母就使用 ISO8859-1,而常用的就是UTF-8编码形式。
4.2 乱码产生分析
先读取 Java 运行属性,在控制台会输出很多属性值:
System.getProperties().list(System.out);
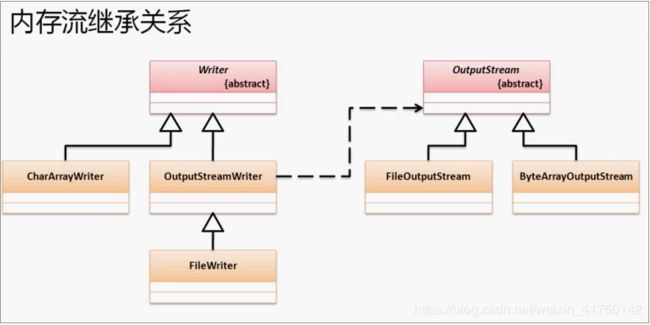
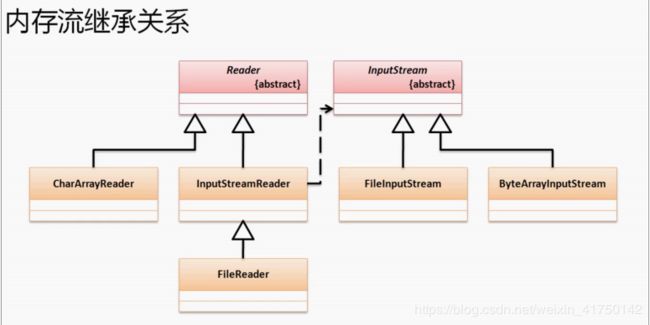
五、内存操作流
5.1 内存流概念
在之前所有的操作都是针对于 文件 进行的 IO 处理。除了文件之外,IO 的操作也可以发生在内存之中,这种流称之为
内存操作流。文件流的操作里面一定会产生一个文件数据(不管最后这个文件数据是否被保留)。
如果现在需求是:需要进行 IO 处理,但是又不希望产生文件。 这种情况下就可以使用 内存 作为操作终端。
对于内存流也分为两类:
1. 字节内存流:
ByteArrayInputStream、ByteArrayOutputStream
public ByteArrayInputStream(byte buf[]) {
public ByteArrayOutputStream() {
this(32);
}
2. 字符内存流:
CharArrayReader、CharArrayWriter
内存流的继承关系:
示例:
public class TestDemo {
public static void main(String[] args) throws IOException {
String msg="Hello World";
//实例化InputStream对象,实例化时需要将操作的数据保存到内存中
//最终读取的是设置的内容
InputStream inputStream=new ByteArrayInputStream(msg.getBytes());
OutputStream outputStream=new ByteArrayOutputStream();
int temp=0;
while ((temp=inputStream.read())!=-1)
//每个字节进行处理,处理之后所有数据都在 outputStream 类中
{
outputStream.write(Character.toUpperCase(temp));
}
//直接输出 output 对象
System.out.println(outputStream);
inputStream.close();
outputStream.close();
}
}
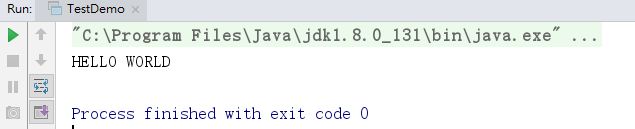
这时发生了 IO 操作,但是没有文件产生,可以理解为 一个临时文件处理。
5.2 内存流操作
内存操作流还有一个很小的功能,可以实现两个文件的合并处理(文件量不大)。
内存操作流最为核心的部分就是:将所有OutputStream输出的程序保存在了程序里面,所以可以通过这一特征实现处理。
需求:
现在有两个文件:data-a.txt、data-b.txt。现在要求将这两个文件的内容做一个合并处理。
示例:内存流实现文件合并处理
public class MergeFile
{
public static void main(String[] args) throws IOException {
File[] files=new File[]
{
new File
(File.separator+"jia"+File.separator+"files"+File.separator+"data-a.text"),
new File
(File.separator+"jia"+File.separator+"files"+File.separator+"data-b.text")
};
String[] data=new String[2];
for(int i=0;i<files.length;i++)
{
data[i]=readFile(files[i]);
}
StringBuffer buf=new StringBuffer();
String[] contextA=data[0].split(" ");
String[] contextB=data[1].split(" ");
for(int i=0;i<contextA.length;i++)
{
buf.append(contextA[i]).append("(").append(contextB[i]).append(")").append(" ");
}
System.out.println(buf);
}
/**
* 读取文件内容,使得 File 对象因为其包含有完整的路径信息
* @param file
* @return
* @throws IOException
*/
public static String readFile(File file) throws IOException {
if(file.exists())
{
InputStream inputStream=new FileInputStream(file);
ByteArrayOutputStream bos=new ByteArrayOutputStream();
int temp=0;
byte[] data=new byte[10];
while ((temp=inputStream.read(data))!=-1)
{
//将数据保存在 bos 中
bos.write(data,0,temp);
}
bos.close();
inputStream.close();
//将读取内容返回
return new String(bos.toByteArray());
}
return null;
}
}
如果只是使用 InputStream 类,在进行数据完整读取时的时候会很不方便,结合内存流的使用会好很多。
六、打印流
打印流解决的就是OutputStream 的设计缺陷,属于OutputStream 功能的加强版。如果操作的不是二进制数据,只是想通过程序向终端目标输出信息的话,OutputStream不是很方便,其缺点有两个:
1. 所有的数据必须转换为字节数组。
2. 如果要输出的是int、double等类型就不方便了。
6.1 打印流的概念
打印流设计的主要目的是为了解决 OutputStream 的设计问题,其本质不会脱离 OutputStream。
示例:自己设计一个简单打印流(其实就是用 OutputStream 的 write 方法)
class PrintUnit {
private OutputStream outputStream;
public PrintUnit(OutputStream outputStream)
{
this.outputStream=outputStream;
}
//打印
public void print(String string) {
try {
this.outputStream.write(string.getBytes());
} catch (IOException e) {
e.printStackTrace();
}
}
public void println(String string)
{
this.print(string+"\n");
}
public void print(int data)
{
this.println(String.valueOf(data));
}
public void println(int data)
{
this.print(data);
}
public void print(double data)
{
this.println(String.valueOf(data));
}
}
public class PrintUnit1
{
public static void main(String[] args) throws FileNotFoundException {
PrintUnit printUnit=new PrintUnit(new FileOutputStream(new File(File.separator+"jia"+File.separator+"files"+File.separator+"hello.text")));
printUnit.print("姓名:");
printUnit.println("jia");
printUnit.print("年龄:");
printUnit.print(20);
printUnit.print("工资:");
printUnit.println("0.0000");
}
}
经过简单处理之后,让 OutputStream 的功能变得更加强大了,其实本质是对 OutputStream 的功能做了一个封装而已,Java 有专门的打印流处理类: PrintStream、PrintWriter。
6.2 使用系统提供的打印流
打印流分为 字节打印流:PrintStream、字符打印流 PrintWriter ,以后使用 PrintWriter 几率较高,首先观察它们的继承结构和构造方法:
public class PrintStream
extends FilterOutputStream
FilterOutputStream extends OutputStream
public PrintStream(OutputStream out)
public class PrintWriter
extends Writer
public PrintWriter(OutputStream out)
public PrintWriter (Writer out)
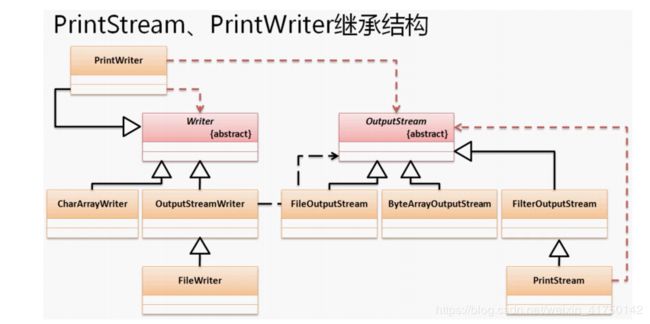
此时看上图继承关系我们会发现,有点像之前讲过的代理设计模式,但是代理设计模式有如下特点:
1. 代理是以接口为使用原则的设计模式。
2. 最终用户可以调用的方法一定是接口定义的方法。
打印流的设计属于 装饰设计模式 :核心依然是某个类的功能,但是为了得到更好的操作效果,让其支持的功能更多一些。
示例:使用打印流
public class TestPrint
{public static void main(String[] args) throws Exception
{ PrintWriter printUtil = new PrintWriter
(new FileOutputStream(new File("/jia/files/hello.txt"))) ;
printUtil.print("姓名:") ;
printUtil.println("jia") ;
printUtil.print("年龄:") ;
printUtil.println(22) ;
printUtil.print("工资: ") ;
printUtil.println(0.000000000000001) ;
printUtil.close();
}
}
这时可以看到新生成了一个 txt 文件:

6.3 格式化输出
C语言有一个 printf() 函数,这个函数在输出的时候可以使用一些占位符,例如:字符串(%s)、数字(%d)、小数(%m.nf)、字符(%c)等。
从 JDK1.5 开始,PrintStream 类中也追加了此种操作,同时在String类中也追加有一个格式化字符串方法。
public PrintWriter printf(String format, Object ... args) {
示例:观察格式化输出
public class TestPrint
{public static void main(String[] args) throws Exception
{ String name = "jia" ;
int age = 22;
double salary = 1.1070000000001 ;
PrintWriter printUtil = new PrintWriter
(new FileOutputStream(new File("/jia/files/hello.txt"))) ;
printUtil.printf("姓名:%s,年龄:%d,工资:%1.2f", name,age,salary) ;
printUtil.close();
}
}

格式化字符串:
public static String format(String format, Object... args) {
示例:格式化字符串
public class TestPrint
{ public static void main(String[] args) throws Exception
{ String name = "yuisama" ;
int age = 25 ;
double salary = 1.1070000000001 ;
String str =String.format
("姓名:%s,年龄:%d,工资:%1.2f", name,age,salary,name,age,salary) ;
System.out.println(str);
}
}
Ajax都是打印流支撑的。
七、System类对IO的支持
学习完 PrintStream 与 PrintWriter 后,我们发现里面的方法名都很熟悉。例如:print()、println(),实际上我们一直在使用的系统输出就是利用了IO流的模式完成。在 System 类 中定义了三个操作的 常量 。
1. 标准输出(显示器) :
public final static PrintStream out
2. 错误输出 :
public final static PrintStream err
3. 标准输入(键盘):
public final static InputStream in
一直在使用的 System.out.println() 属于IO的操作范畴。
7.1 系统输出
系统输出一共有两个常量:out、err,并且这两个常量表示的都是PrintStream类的对象。
1. out输出的是希望用户能看到的内容
2. err输出的是不希望用户看到的内容
这两种输出在实际的开发之中都没用了,取而代之的是"日志"。
System.err只是作为一个保留的属性而存在,现在几乎用不到。唯一可能用到的就是System.out。
由于 System.out 是 PrintStream 的实例化对象,而PrintStream 又是 OutputStream 的子类,所以可以直接使用 System.out 直接为OutputStream实例化,这个时候的 OutputStream 输出的位置将变为屏幕。
示例:使用System.out为OutputStream实例化。
public class TestPrint
{ public static void main(String[] args) throws Exception
{ OutputStream out = System.out ; out.write("欢迎".getBytes()); }}
会在控制台输出"欢迎"。
抽象类不同的子类针对于同一方法有不同的实现,而用户调用的时候核心参考的是抽象类。
7.2 系统输入
System.in 对应的类型是 InputStream,而这种输入流指的是由用户通过键盘进行输入(用户输入)。Java 本身并没有直接的用户输入处理,如果要想实现这种操作,必须使用 java.io 的模式来完成。
示例:利用 InputStream 实现数据输入
public class TestPrint {
public static void main(String[] args) throws Exception {
InputStream in = System.in;
ByteArrayOutputStream bos = new ByteArrayOutputStream();
byte[] data = new byte[10];
System.out.print("请输入信息:");
int temp = 0;
while ((temp = in.read(data)) != -1) {
bos.write(data, 0, temp);
// 保存数据到内存输出流中
// 这里面需要用户判断是否输入结束
if (temp < data.length) {
break;
}
}
in.close();
bos.close();
System.out.println("输出内容为 :" + new String(bos.toByteArray()));
}
}
现在发现当用户输入数据的时候程序需要暂停执行,也就是程序进入了阻塞状态。直到用户输入完成(按下回车),程序才能继续向下执行。
以上的程序本身有一个致命的问题,核心点在于:开辟的字节数组长度固定,如果现在输入的长度超过了字节数组长度,那么只能够接收部分数据。这个时候是由于一次读取不完所造成的问题,所以此时最好的做法是引入内存操作流来进行控制,这些数据先保存在内存流中而后一次取出。
示例:引入内存流
public class TestPrint
{ public static void main(String[] args) throws Exception
{ InputStream in = System.in ;
ByteArrayOutputStream bos = new ByteArrayOutputStream() ;
byte[] data = new byte[10] ;
System.out.print("请输入信息:");
int temp = 0 ;
while((temp = in.read(data)) != -1)
{ bos.write(data,0,temp) ;
// 保存数据到内存输出流中
// 这里面需要用户判断是否输入结束
if (temp < data.length) { break ;
}
}
in.close() ;
bos.close() ;
System.out.println("输出内容为 :" +new String(bos.toByteArray())) ;
}
}

现在虽然实现了键盘输入数据的功能,但是整体的实现逻辑过于混乱了,即 java 提供的 System.in 并不好用,还要结合内存流来完成,复杂度很高。
如果要想在 IO 中进行中文的处理,最好的做法是将所有输入的数据保存在一起再处理,这样才可以保证不出现乱码。
八、两种输入流
8.1 BufferedReader类
BufferedReader类属于一个缓冲的输入流,而且是一个字符流的操作对象。
在 java 中对于缓冲流也分为两类:字节缓冲流(BufferedInputStream)、字符缓冲流(BufferedReader)。
之所以选择BufferedReader类操作是因为在此类中提供有如下方法(读取一行数据):
public String readLine() throws IOException {
这个方法可以直接读取一行数据 (以回车为换行符) ,但是这个时候有一个非常重要的问题要解决,来看 BufferedReader 类的定义与构造方法 :
public class BufferedReader extends Reader {
public BufferedReader(Reader in) {
而 System.in 是 InputStream 类的子类,这个时候与 Reader没有关系,要建立起联系就要用到 InputStreamReader 类。如下:
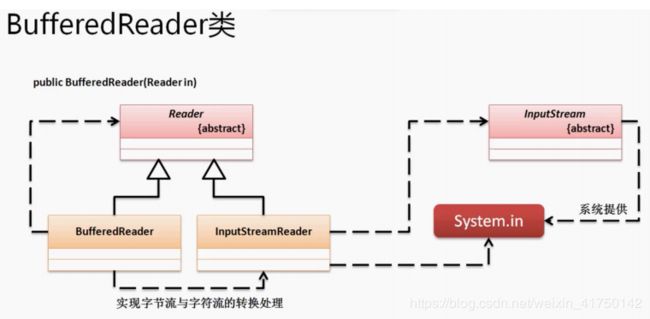
范例:利用BufferedReader实现键盘输入
public class TestPrint
{ public static void main(String[] args) throws Exception
{ BufferedReader buf = new BufferedReader(new InputStreamReader(System.in)) ;
System.out.println("请输入信息 :") ;
// 默认的换行模式是BufferedReader的最大缺点
String str = buf.readLine() ;
// 默认使用回车换行
System.out.println("输入信息为:" + str );
}
}

以上操作形式是 java10 多年前输入的标准格式,但是时过境迁,这个类也淹没在历史的潮流之中,被JDK1.5提供的java.util.Scanner类所取代。
使用以上形式实现的键盘输入还有一个最大特点,由于接收的数据类型为 String,可以使用String类的各种操作进行数据处理并且可以变为各种常见数据类型。
8.2 java.util.Scanner类
打印流解决的是 OutputStream 类的缺陷,BufferedReader解决的是 InputStream 类的缺陷。而 Scanner 解决的是 BufferedReader 类的缺陷(替换了BufferedReader类)。
Scanner 是一个专门进行输入流处理的程序类,利用这个类可以方便处理各种数据类型,同时也可以直接结合正则表达式进行各项处理,在这个类中主要关注以下方法:
1. 判断是否有指定类型数据:
public boolean hasNextXxx()
2. 取得指定类型的数据:
public 数据类型 nextXxx()
3. 定义分隔符:
public Scanner useDelimiter(Pattern pattern)
4. 构造方法:
public Scanner(InputStream source)
示例:使用Scanner实现数据输入:
public class TestPrint
{ public static void main(String[] args) throws Exception
{ Scanner scanner = new Scanner(System.in) ;
System.out.println("请输入数据:") ;
if (scanner.hasNext())
{
// 有输入内容,不判断空字符串
System.out.println("输入内容为: "+scanner.next());
}
scanner.close() ;
}
}
使用Scanner还可以接收各种数据类型,并且帮助用户减少转型处理。
示例:接收其他类型数据
public class TestPrint
{ public static void main(String[] args) throws Exception
{ Scanner scanner = new Scanner(System.in) ;
System.out.println("请输入年龄:") ;
if (scanner.hasNextInt())
{ // 有输入内容,不判断空字符串
int age = scanner.nextInt() ;
System.out.println("输入内容为: "+ age ); }
else
{ System.out.println("输入的不是数字!"); }
scanner.close() ;
}
}
最为重要的是,Scanner 可以对接收的数据类型使用正则表达式判断。
示例:利用正则表达式进行判断
import java.util.Scanner;
public class TestPrint
{ public static void main(String[] args) throws Exception
{ Scanner scanner = new Scanner(System.in) ;
System.out.println("请输入生日:") ;
if (scanner.hasNext("\\d{4}-\\d{2}-\\d{2}"))
{ String birthday = scanner.next() ;
System.out.println("输入的生日为:" + birthday); }
else { System.out.println("输入的格式非法,不是生日"); }
scanner.close() ;
}
}

但是以上操作在开发之中基本不会出现,现在不可能让你编写一个命令行程序进行数据输入。
使用 Scanner 本身能够接收的是一个 InputStream 对象,那么也就意味着可以接收任意输入流,例如:文件输入流 ;
Scanner 完美的替代了 BufferedReader,而且更好的实现了InputStream 的操作。
示例:使用Scanner操作文件
public class TestPrint
{ public static void main(String[] args) throws Exception
{ Scanner scan = new Scanner(new FileInputStream(new File("/jia/files/hello.txt"))) ;
scan.useDelimiter("\n") ;
// 自定义分隔符
while (scan.hasNext())
{ System.out.println(scan.next()); }
scan.close();
}
}
总结:
以后除了二进制文件拷贝的处理之外,那么只要是针对程序的信息输出都是用打印流(PrintStream、PrintWriter),信息输出使用Scanner。