Linux内核文件系统
Linux 内核文件系统
概述
文件系统这一词在不同上下文时有不同的含义:
- 指一种具体的文件格式。例如Linux的文件系统是
Ext2,MSDOS的文件系统是FAT16,而Windows NT的文件系统是NTFS或FAT32 - 指按特定格式进行了“格式化”的一块存储介质。
- 值操作系统中用来管理文件系统以及对文件进行操作的机制及其实现。
事实上,Linux除了本身的Ext2以外,还支持其他各种不同的文件系统。Linux是通过将自身的文件系统抽象为一个文件系统界面,用户通过这个文件系统界面(即一组系统调用),可以对不同的文件系统进行操作。在用户看来,这是一个虚拟的、同一的、抽象的文件系统,用户并不关注文件系统的实际细节(文件系统类型、相关操作如何进行)。这就是所谓的虚拟文件系统VFS。这个抽象的界面为用户提供一组标准的、抽象的文件操作,以系统调用的形式存在于用户程序,如read()、write()、lseek()等等。比如Linux操作系统中,可以将DOS格式的磁盘或者分区(即文件系统)安装到系统中,然后用户程序可以以相同的方式访问这些文件,好像它们也是Ext2格式的文件一样。
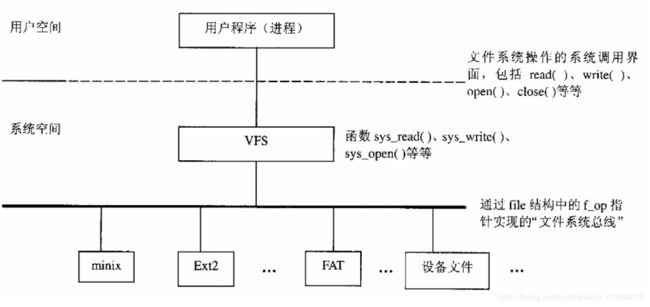
内核与不同文件系统的接口是通过file_operation这个数据结构实现的。
/*
* NOTE:
* read, write, poll, fsync, readv, writev can be called
* without the big kernel lock held in all filesystems.
*/
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*aio_read) (struct kiocb *, char __user *, size_t, loff_t);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
ssize_t (*aio_write) (struct kiocb *, const char __user *, size_t, loff_t);
int (*readdir) (struct file *, void *, filldir_t);
unsigned int (*poll) (struct file *, struct poll_table_struct *);
int (*ioctl) (struct inode *, struct file *, unsigned int, unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *);
int (*release) (struct inode *, struct file *);
int (*fsync) (struct file *, struct dentry *, int datasync);
int (*aio_fsync) (struct kiocb *, int datasync);
int (*fasync) (int, struct file *, int);
int (*lock) (struct file *, int, struct file_lock *);
ssize_t (*readv) (struct file *, const struct iovec *, unsigned long, loff_t *);
ssize_t (*writev) (struct file *, const struct iovec *, unsigned long, loff_t *);
ssize_t (*sendfile) (struct file *, loff_t *, size_t, read_actor_t, void __user *);
ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);
unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long);
};
可以看到该结构体内几乎全部是函数指针。每一个文件系统都要负责实现自己的file_operations数据结构,比如这里的read就指向该文件系统的用来实现读文件操作的入口函数。
每个进程通过打开文件open()与具体的某一个文件建立起联系,或者说建立起一个读写上下文。这种联系的实际承载者为file数据结构。
在代表进程的task_struct数据结构中有两个指针:
/* filesystem information */
struct fs_struct *fs;
/* open file information */
struct files_struct *files;
fs_struct代表文件系统的信息,files_struct代表已打开文件的信息
struct fs_struct {
atomic_t count;
rwlock_t lock;
int umask;
struct dentry * root, * pwd, * altroot;
struct vfsmount * rootmnt, * pwdmnt, * altrootmnt;
};
前三个指针指向dentry结构体,dentry记录目录项,因此pwd代表进程当前的目录,root代表进程的根目录,就是当用户登录进入系统时的目录,altroot是为用户设置的替换根目录。实际运行时这三个目录不一定在同一个文件系统中,比如root通常是安装于/节点上的Ext2文件系统中,而当前工作目录则可能安装于/dosc的一个DOS文件系统中。后三个指针就各自指向代表着这些安装的vfsmount数据结构。
一个进程已经打开的文件相关的信息存储在file结构体中,而files_struct结构体的主要内容就是file结构体数组。
struct files_struct {
atomic_t count;
spinlock_t file_lock; /* Protects all the below members. Nests inside tsk->alloc_lock */
int max_fds;
int max_fdset;
int next_fd;
struct file ** fd; /* current fd array */
fd_set *close_on_exec;
fd_set *open_fds;
fd_set close_on_exec_init;
fd_set open_fds_init;
struct file * fd_array[NR_OPEN_DEFAULT];
};
在file结构体中:
struct file{
...
struct dentry *f_dentry;
struct vfsmount *f_vfsmnt;
struct file_operations *f_op;
...
}
f_op指针指向该文件所属文件系统的file_operation结构体,因此通过file可以知道如何对该文件进行操作;f_dentry指向该文件的dentry数据结构,即记录了该文件的目录信息,为什么这里不将dentry作为file文件的成员而是用一个指针来指向dentry呢?是因为同一个文件只有一个dentry结构体,而该文件可能被多个进程打开,每当该文件被一个进程打开就会在该进程的task_struct中创建一个file结构体实例。
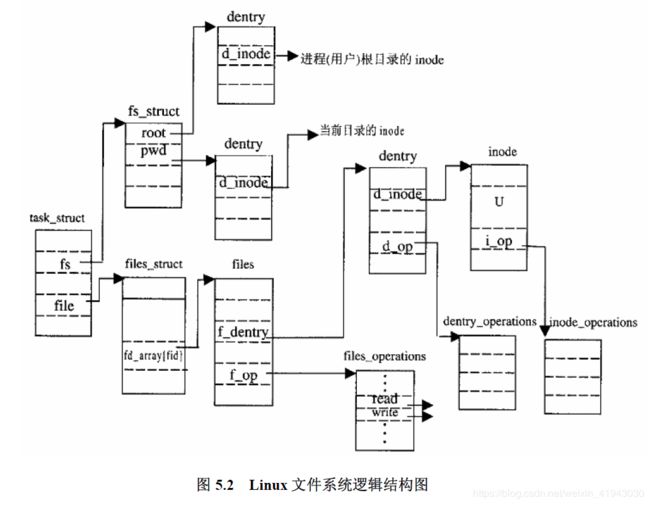
总之,Linux通过虚文件系统提供一组约定的数据结构,包括有dentry、inode、dentry_operations、inode_operations等。这些数据结构的内容在进程与某一个文件建立联系open之后被初始化,初始化的结果与文件所处介质的文件系统类型有关。虽然不同文件系统的实现细节不同,比如不同的文件系统可能使用不同的索引机制,但是他们都会有实现类似功能的具体数据结构。因此只对于不同的文件系统,Linux利用函数指针数组去寻找对应文件系统设备驱动中的函数,来完成相似的任务。
Virtual Filesystem中的主要数据结构
The Superblock Object
struct super_block {
struct list_head s_list; /* list of all superblocks */
dev_t s_dev; /* identifier */
unsigned long s_blocksize; /* block size in bytes */
unsigned char s_blocksize_bits; /* block size in bits */
unsigned char s_dirt; /* dirty flag */
unsigned long long s_maxbytes; /* max file size */
struct file_system_type *s_type; /* filesystem type */
struct super_operations *s_op; /* superblock methods */
struct dquot_operations *dq_op; /* quota methods */
struct quotactl_ops *s_qcop; /* quota control methods */
struct export_operations *s_export_op; /* export methods */
unsigned long s_flags; /* mount flags */
unsigned long s_magic; /* filesystem’s magic number */
struct dentry *s_root; /* directory mount point */
struct rw_semaphore s_umount; /* unmount semaphore */
struct semaphore s_lock; /* superblock semaphore */
int s_count; /* superblock ref count */
int s_need_sync; /* not-yet-synced flag */
atomic_t s_active; /* active reference count */
void *s_security; /* security module */
struct xattr_handler **s_xattr; /* extended attribute handlers */
struct list_head s_inodes; /* list of inodes */
struct list_head s_dirty; /* list of dirty inodes */
struct list_head s_io; /* list of writebacks */
struct list_head s_more_io; /* list of more writeback */
struct hlist_head s_anon; /* anonymous dentries */
struct list_head s_files; /* list of assigned files */
struct list_head s_dentry_lru; /* list of unused dentries */
int s_nr_dentry_unused; /* number of dentries on list */
struct block_device *s_bdev; /* associated block device */
struct mtd_info *s_mtd; /* memory disk information */
struct list_head s_instances; /* instances of this fs */
struct quota_info s_dquot; /* quota-specific options */
int s_frozen; /* frozen status */
wait_queue_head_t s_wait_unfrozen; /* wait queue on freeze */
char s_id[32]; /* text name */
void *s_fs_info; /* filesystem-specific info */
fmode_t s_mode; /* mount permissions */
struct semaphore s_vfs_rename_sem; /* rename semaphore */
u32 s_time_gran; /* granularity of timestamps */
char *s_subtype; /* subtype name */
char *s_options; /* saved mount options */
};
内核中的超级块对象由函数alloc_super()负责创建。当一个文件系统被mount时,alloc_super()函数会通过设备驱动从disk中读出该文件系统的superblock,用文件系统的superblock来初始化内核中的superblock对象。
Superblock Operations
superblock对象中最重要的成员时s_op,它是一个指向superblock operation table的指针,superblock operation struct中的函数指针规定了对一个文件系统可以执行的操作。
struct super_operations {
struct inode *(*alloc_inode)(struct super_block *sb);
void (*destroy_inode)(struct inode *);
void (*read_inode) (struct inode *);
void (*dirty_inode) (struct inode *);
void (*write_inode) (struct inode *, int);
void (*put_inode) (struct inode *);
void (*drop_inode) (struct inode *);
void (*delete_inode) (struct inode *);
void (*put_super) (struct super_block *);
void (*write_super) (struct super_block *);
int (*sync_fs)(struct super_block *sb, int wait);
void (*write_super_lockfs) (struct super_block *);
void (*unlockfs) (struct super_block *);
int (*statfs) (struct super_block *, struct kstatfs *);
int (*remount_fs) (struct super_block *, int *, char *);
void (*clear_inode) (struct inode *);
void (*umount_begin) (struct super_block *);
int (*show_options)(struct seq_file *, struct vfsmount *);
};
当文件系统需要对其superblock执行操作时,就会从其super_block struct中的指针找到super_operations结构,再根据函数指针跳转到相应的处理程序。而相应的处理程序是由不同的on-disk filesystem来决定的。
The Inode Object
inode object代表了内核管理一个文件或者目录所需要的全部信息。对于Unix-style filesystem来说,这些信息可以直接从on-disk inode读取,如果一个文件系统不包含inode那么它需要根据自己文件系统的设计,找出具有相似功能的信息填充kernel inode。
struct inode {
struct hlist_node i_hash; /* hash list */
struct list_head i_list; /* list of inodes */
struct list_head i_sb_list; /* list of superblocks */
struct list_head i_dentry; /* list of dentries */
unsigned long i_ino; /* inode number */
atomic_t i_count; /* reference counter */
unsigned int i_nlink; /* number of hard links */
uid_t i_uid; /* user id of owner */
gid_t i_gid; /* group id of owner */
kdev_t i_rdev; /* real device node */
u64 i_version; /* versioning number */
loff_t i_size; /* file size in bytes */
seqcount_t i_size_seqcount; /* serializer for i_size */
struct timespec i_atime; /* last access time */
struct timespec i_mtime; /* last modify time */
struct timespec i_ctime; /* last change time */
unsigned int i_blkbits; /* block size in bits */
blkcnt_t i_blocks; /* file size in blocks */
unsigned short i_bytes; /* bytes consumed */
umode_t i_mode; /* access permissions */
spinlock_t i_lock; /* spinlock */
struct rw_semaphore i_alloc_sem; /* nests inside of i_sem */
struct semaphore i_sem; /* inode semaphore */
struct inode_operations *i_op; /* inode ops table */
struct file_operations *i_fop; /* default inode ops */
struct super_block *i_sb; /* associated superblock */
struct file_lock *i_flock; /* file lock list */
struct address_space *i_mapping; /* associated mapping */
struct address_space i_data; /* mapping for device */
struct dquot *i_dquot[MAXQUOTAS]; /* disk quotas for inode */
struct list_head i_devices; /* list of block devices */
union{
struct pipe_inode_info *i_pipe; /* pipe information */
struct block_device *i_bdev; /* block device driver */
struct cdev *i_cdev; /* character device driver */
};
unsigned long i_dnotify_mask; /* directory notify mask */
struct dnotify_struct *i_dnotify; /* dnotify */
struct list_head inotify_watches; /* inotify watches */
struct mutex inotify_mutex; /* protects inotify_watches */
unsigned long i_state; /* state flags */
unsigned long dirtied_when; /* first dirtying time */
unsigned int i_flags; /* filesystem flags */
atomic_t i_writecount; /* count of writers */
void *i_security; /* security module */
void *i_private; /* fs private pointer */
所有的inode都代表了文件系统中的一个文件,但是inode bject只会在文件被访问时才会在内存中被实例化。这包括了特殊文件,比如设备文件或者管道文件。因此,struct inode中的某些域就会与这些特定的文件相关。比如,i_pipe域指向一个命名管道的数据结构,i_bdev指向一个块设备数据结构。
Inode Operations
正如在superblock operation中一样,inode_opeartion成员非常重要。
It describes the filesystem’s implemented functions that the VFS can invoke on an inode.
比如:
i->i_op->truncate(i)
这里的 i 是对某个特定inode的指针,对这个inode我们执行了truncate()操作,而这个操作的具体执行函数是由inode所在的文件系统提供的。
struct inode_operations {
int (*create) (struct inode *,struct dentry *,int, struct nameidata *);
struct dentry * (*lookup) (struct inode *,struct dentry *, struct nameidata *);
int (*link) (struct dentry *,struct inode *,struct dentry *);
int (*unlink) (struct inode *,struct dentry *);
int (*symlink) (struct inode *,struct dentry *,const char *);
int (*mkdir) (struct inode *,struct dentry *,int);
int (*rmdir) (struct inode *,struct dentry *);
int (*mknod) (struct inode *,struct dentry *,int,dev_t);
int (*rename) (struct inode *, struct dentry *,
struct inode *, struct dentry *);
int (*readlink) (struct dentry *, char __user *,int);
void * (*follow_link) (struct dentry *, struct nameidata *);
void (*put_link) (struct dentry *, struct nameidata *, void *);
void (*truncate) (struct inode *);
int (*permission) (struct inode *, int);
int (*setattr) (struct dentry *, struct iattr *);
int (*getattr) (struct vfsmount *mnt, struct dentry *, struct kstat *);
int (*setxattr) (struct dentry *, const char *,const void *,size_t,int);
ssize_t (*getxattr) (struct dentry *, const char *, void *, size_t);
ssize_t (*listxattr) (struct dentry *, char *, size_t);
int (*removexattr) (struct dentry *, const char *);
void (*truncate_range)(struct inode *, loff_t, loff_t);
long (*fallocate)(struct inode *inode, int mode, loff_t offset, loff_t len);
int (*fiemap)(struct inode *, struct fiemap_extent_info *, u64 start, u64 len);
};
inode_create:VFS通过create()和open()系统调用来call这个函数,根据specified initial access mode来创建一个和特定dentry object相关联的新的inode对象实例
The Dentry Object
在on-disk文件系统中,通常将目录也理解为文件,目录文件也有对应的inode,只是目录文件的数据块中存储的是名字到inode的映射关系。不过在Linux VFS中则是将所有文件与目录都抽象为目录,在所有inode之上都抽象出一个dentry,文件系统对inode操作首先需要找到inode在文件系统中对应的dentry。这个关系在前面的Linux 文件系统结构图中很清楚。之所以这么做,是为了加速对目录的访问。
比如有路径/bin/vi,bin在磁盘中是目录文件,vi是常规文件。这两个文件都有自己的inode。尽管有这种有用的统一化,VFS经常需要去执行一些directory-specific operation,比如一些路径查找。路径名查找需要翻译一个路径的各个部分,确保每一步都是合法的,然后从一个部分查找到下一个部分。为了加速这个过程,VFS引入了directory entry的概念。A dentry is a specific component in a path. 在前面的例子中,/,bin,vi都是dentry object。Dentry objects are all components in a path, including files. 这样就使得解析路径变得简单。
struct dentry {
atomic_t d_count; /* usage count */
unsigned int d_flags; /* dentry flags */
spinlock_t d_lock; /* per-dentry lock */
int d_mounted; /* is this a mount point? */
struct inode *d_inode; /* associated inode */
struct hlist_node d_hash; /* list of hash table entries */
struct dentry *d_parent; /* dentry object of parent */
struct qstr d_name; /* dentry name */
struct list_head d_lru; /* unused list */
union {
struct list_head d_child; /* list of dentries within */
struct rcu_head d_rcu; /* RCU locking */
} d_u;
struct list_head d_subdirs; /* subdirectories */
struct list_head d_alias; /* list of alias inodes */
unsigned long d_time; /* revalidate time */
struct dentry_operations *d_op; /* dentry operations table */
struct super_block *d_sb; /* superblock of file */
void *d_fsdata; /* filesystem-specific data */
unsigned char d_iname[DNAME_INLINE_LEN_MIN]; /* short name */
};
dentry也可能表示一个挂载点。比如在路径/mnt/cdrom/foo中,/,mnt,cdrom,foo都是dentry object。VFS在执行directory operations时实时地创建dentry object。dentry并不对应任何on-disk data structure。
注意在dentry中有
struct dentry *d_parent; /* dentry object of parent */
struct list_head d_subdirs; /* subdirectories */
可以先将这两个变量简单理解为指向父目录和自身所有子目录的指针。子目录是以一个d_subdirs队列的形式组织的。因此,可以想到,dentry就是在vfs内部用来模拟on-disk files and directires组织结构的数据结构。通过dentry操作系统无需直接访问磁盘便可以快速知道磁盘文件和目录的逻辑结构。当然了,对dentry的建立是基于磁盘数据组织结构的,因此起码需要对disk数据进行一次访问才能在内存中缓存磁盘数据逻辑结构。
总结dentry的主要作用是:
- 在路径解析时使用,VFS直接使用
dentry就可以得到磁盘上文件路径的信息。而不需要每次都要从磁盘读取目录文件进行路径解析; - 将每次路径解析的结果缓存形成
dentry cache。
Dentry State
一个合法的dentry对象可以有三种状态:used, unused, negative
- A used dentry corresponds to a valid inode (d_inode points to an associated inode) and indicates that there are one or more users of the object (d_count is positive).A used
dentry is in use by the VFS and points to valid data and, thus, cannot be discarded. - An unused dentry corresponds to a valid inode (d_inode points to an inode), but the VFS is not currently using the dentry object (d_count is zero). 未使用的
dentry对应着一个inode,但是并没有被任何进行所使用。通常会将这种dentry缓存起来,使得path name lookups变得更快。 - A negative dentry is not associated with a valid inode (d_inode is NULL) because either the inode was deleted or the path name was never correct to begin with.
negative dentry的主要作用是将失败的访问路径也缓存下来。
The Dentry Cache
dentry cache 由三部分组成:
- 由于同一个
inode会有不同的dentry,因此inode中的i_dentry队列保存了所有指向该inode的目录项。 - 一个双向链接的
lru队列保存了未被使用的以及negative dentry objects. - 一个hash table 以及 hashing function 用来快速根据路径名找到对应的 目录项。
Hash 表存储在dentry_hashtable数组中。每一个元素都是一个指针,指向一组具有相同hash值的dentries(链表形式组织起来),通过d_lookup()函数可以查询hash表。
比如:现在正在编辑一个位于home文件夹下的源文件/home/dracula/src/the_sun_sucks.c,每当访问这个文件时,为了解析全部路径:/,home,dracula,src,the_sun_sucks.c,VFS必须follow each directory entry。为了避免这种很费时间的操作,VFS可以首先尝试在dentry cache中查找路径名。如果查询成功,那就可以直接得到所需要的dentry object,如果失败了,那么VFS需要去向文件系统查找目录文件。在完成以后,内核将这些新的目录项加入dchche来加速未来的查询。
Dentry Operations
struct dentry_operations {
int (*d_revalidate) (struct dentry *, struct nameidata *);
int (*d_hash) (struct dentry *, struct qstr *);
int (*d_compare) (struct dentry *, struct qstr *, struct qstr *);
int (*d_delete) (struct dentry *);
void (*d_release) (struct dentry *);
void (*d_iput) (struct dentry *, struct inode *);
char *(*d_dname) (struct dentry *, char *, int);
};
d_hash()的作用是根据规定的dentry产生一个hash值,每当VFS将一个dentry加入哈希表时就会调用这个函数。
The File Objects
The file object is used to represent a file opened by a process. 当我们从用户空间的角度考虑VFS时,第一个遇到的就是file object。进程直接处理文件,而不是superblocks, inodes, 或者dentries.
The file object is the in-memory representation of an open file. The object is created in reponse to the open() system call and destroyed in response to the close() system call. 所有与文件相关的操作都被定义在file operation table中。因为有可能多个进程会打开和管理同一个文件,那么对于同一个文件来说有可能会有多个对应的file objects。The file object points back to the dentry that actually represents the open file. The inode and dentry objects, of course, are unique.(dentry 和 inode是多对一的关系,因为一个文件可能具有不同的路径)。
struct file {
union {
struct list_head fu_list; /* list of file objects */
struct rcu_head fu_rcuhead; /* RCU list after freeing */
} f_u;
struct path f_path; /* contains the dentry */
struct file_operations *f_op; /* file operations table */
spinlock_t f_lock; /* per-file struct lock */
atomic_t f_count; /* file object’s usage count */
unsigned int f_flags; /* flags specified on open */
mode_t f_mode; /* file access mode */
loff_t f_pos; /* file offset (file pointer) */
struct fown_struct f_owner; /* owner data for signals */
const struct cred *f_cred; /* file credentials */
struct file_ra_state f_ra; /* read-ahead state */
.u64 f_version; /* version number */
void *f_security; /* security module */
void *private_data; /* tty driver hook */
struct list_head f_ep_links; /* list of epoll links */
spinlock_t f_ep_lock; /* epoll lock */
struct address_space *f_mapping; /* page cache mapping */
unsigned long f_mnt_write_state; /* debugging state */
};
File Operations
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
ssize_t (*aio_read) (struct kiocb *, const struct iovec *, unsigned long, loff_t);
ssize_t (*aio_write) (struct kiocb *, const struct iovec *, unsigned long, loff_t);
int (*readdir) (struct file *, void *, filldir_t);
unsigned int (*poll) (struct file *, struct poll_table_struct *);
int (*ioctl) (struct inode *, struct file *, unsigned int,
unsigned long);
long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long);
long (*compat_ioctl) (struct file *, unsigned int, unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *, fl_owner_t id);
int (*release) (struct inode *, struct file *);
int (*fsync) (struct file *, struct dentry *, int datasync);
int (*aio_fsync) (struct kiocb *, int datasync);
int (*fasync) (int, struct file *, int);
int (*lock) (struct file *, int, struct file_lock *);
ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);
unsigned long (*get_unmapped_area) (struct file *,unsigned long, unsigned long, unsigned long, unsigned long);
int (*check_flags) (int);
int (*flock) (struct file *, int, struct file_lock *);
ssize_t (*splice_write) (struct pipe_inode_info *,
struct file *, loff_t *, size_t, unsigned int);
ssize_t (*splice_read) (struct file *,
loff_t *, struct pipe_inode_info *, size_t, unsigned int);
int (*setlease) (struct file *, long, struct file_lock **);
};
loff_t llseek(struct file *file, loof_t offset, int origin)用来将文件指针移动一个给定的距离。llseek()系统调用最后会调用到这个函数。
Data Structures Associated with Filesystems
由于Linux支持许多不同的文件系统,内核必须有一个特殊的数据结构来描述不同文件系统的所具备的能力。file_system_type就是这个作用:
struct file_system_type {
const char *name; /* filesystem’s name */
int fs_flags; /* filesystem type flags */
/* the following is used to read the superblock off the disk */
struct super_block *(*get_sb) (struct file_system_type *, int,
char *, void *);
/* the following is used to terminate access to the superblock */
void (*kill_sb) (struct super_block *);
struct module *owner; /* module owning the filesystem */
struct file_system_type *next; /* next file_system_type in list */
struct list_head fs_supers; /* list of superblock objects */
/* the remaining fields are used for runtime lock validation */
struct lock_class_key s_lock_key;
struct lock_class_key s_umount_key;
struct lock_class_key i_lock_key;
struct lock_class_key i_mutex_key;
struct lock_class_key i_mutex_dir_key;
struct lock_class_key i_alloc_sem_key;
};
get_sb()函数从disk的超级块中读取数据,然后在文件系统被加载时将信息存入file_system_type中。其余的函数描述了文件系统的特性。
每一个文件系统都只有一个file_system_type,无论有多少个该文件系统的实例被挂载在系统中,或者该文件系统有没有被挂载。
当文件系统被挂载时,系统会创建一个vfsmount数据结构。这个数据结构代表了一个特定的文件系统实例,换句话说,一个挂载点。
struct vfsmount {
struct list_head mnt_hash; /* hash table list */
struct vfsmount *mnt_parent; /* parent filesystem */
struct dentry *mnt_mountpoint; /* dentry of this mount point */
struct dentry *mnt_root; /* dentry of root of this fs */
struct super_block *mnt_sb; /* superblock of this filesystem */
struct list_head mnt_mounts; /* list of children */
struct list_head mnt_child; /* list of children */
int mnt_flags; /* mount flags */
char *mnt_devname; /* device file name */
struct list_head mnt_list; /* list of descriptors */
struct list_head mnt_expire; /* entry in expiry list */
struct list_head mnt_share; /* entry in shared mounts list */
struct list_head mnt_slave_list; /* list of slave mounts */
struct list_head mnt_slave; /* entry in slave list */
struct vfsmount *mnt_master; /* slave’s master */
struct mnt_namespace *mnt_namespace; /* associated namespace */
int mnt_id; /* mount identifier */
int mnt_group_id; /* peer group identifier */
atomic_t mnt_count; /* usage count */
int mnt_expiry_mark; /* is marked for expiration */
int mnt_pinned; /* pinned count */
int mnt_ghosts; /* ghosts count */
atomic_t __mnt_writers; /* writers count */
};
Data Structure Associated with a Process
系统中的每一个进程都有自己的打开文件表,根文件系统,当前工作目录,挂载点等等。
files_struct定义在files域是一个指向files_struct的指针。所有的关于进程打开文件的信息,以及文件描述符都在files_struct其中。
struct files_struct {
atomic_t count; /* usage count */
struct fdtable *fdt; /* pointer to other fd table */
struct fdtable fdtab; /* base fd table */
spinlock_t file_lock; /* per-file lock */
int next_fd; /* cache of next available fd */
struct embedded_fd_set close_on_exec_init; /* list of close-on-exec fds */
struct embedded_fd_set open_fds_init /* list of open fds */
struct file *fd_array[NR_OPEN_DEFAULT]; /* base files array */
};
fd_array数组中的元素为struct file*指针。前面提到过,file结构对应一个dentry对象,open()系统调用创造一个dentry或者在dchche中找到一个dentry,并且创建一个指向dentry的file结构,将这个file结构的地址加入到struct file *fd_array[]中,然后返回在fd_array中的索引作为open()函数的返回值。
第二个与进程相关的数据结构是fs_struct,包含了与该进程有关文件系统的信息,并且进程描述符中的fs域指向这个数据结构。
struct fs_struct {
int users; /* user count */
rwlock_t lock; /* per-structure lock */
int umask; /* umask */
int in_exec; /* currently executing a file */
struct path root; /* root directory */
struct path pwd; /* current working directory */
};
这个结构中保存了当前工作目录(pwd)以及当前进程的根目录。
第三个重要的数据结构是namespace结构,定义在mnt_namespace域指向这个数据结构。从Linux 2.4内核开始,每个进程都有自己的namespace,它使每个进程对系统上已经挂载的文件系统有一个自己独特的视角————不再是仅仅有一个根目录,而是一个完全的唯一的文件系统层级。
struct mnt_namespace {
atomic_t count; /* usage count */
struct vfsmount *root; /* root directory */
struct list_head list; /* list of mount points */
wait_queue_head_t poll; /* polling waitqueue */
int event; /* event count */
};
list成员指向已经挂载了的文件系统的一个双向链表,这个双向链表组成了namespace。对于大部分进程来说,它们的进程描述符会指向自己特有的files_struct以及fs_struct。对于通过具有克隆标志CLONE_FLAGS或者CLONE_FS创建的进程来说,它们则会共享filse_strucr、fs_struct。这就导致不同的进程描述符会指向相同的
filse_strucr、fs_struct。count成员的作用就是记录共享文件进程的数量。
namespace机制从相反的方向解决问题。默认情况下,所有的进程都具有相同的namespace。(那就是说,they all see the same filesystem hierarchy from the same mount table)。只有当使用clone()期间设置了CLONE_NEWNS标志之后,每个进程才会具有一份namespace结构的拷贝。否则大部分进程只是从其父母处继承namespace。