pandas 重新索引
重新索引
pandas对象的一个重要方法是 reindex ,其作用是创建一个适应新索引的新对象。

#reindex函数的参数 reindex(index,method,fill_value,limit,level,copy) #index:用作索引的新序列 #method:插值(填充)方式 #fill_value:在重新索引的过程中,需要引入缺失值时使用的代替值 #limit:前向或后向填充时的最大填充量 #level:在MultiIndex的指定级别上匹配简单索引,否则选取其子集 #copy:默认为True,无论如何都复制,如果为False,则新旧相等就不复制
obj=Series([4.5,7.2,-5.3,3.6],index=['d','b','a','c']) obj #调用该Series的reindex将会根据新索引进行重排 #如果某个索引值当前不存在,就引入缺失值 obj2=obj.reindex(['a','b','c','d','e']) obj2 #填充缺失值 obj.reindex(['a','b','c','d','e'],fill_value=0)
重新索引时,可能需要做一些插值处理。method选项可以达到此目的。
obj3=Series(['blue','purple','yellow'],index=[0,2,4]) obj3 obj3.reindex(range(6),method='ffill')
reindex的(插值)method选项
ffill或pad ——向前填充(或搬运)值
bfill或backfill——后向填充(或搬运)值
重新索引行
frame=DataFrame(np.arange(9).reshape(3,3),index=['a','c','d'],
columns=['Ohio','Texas','California'])
frame
frame2=frame.reindex(['a','b','c','d'])
frame2
重新索引列
使用columns关键字进行重新索引
states=['Texas','Utah','California'] frame.reindex(columns=states)
同时对行和列进行重新索引
书上写法是:frame.reindex(index=['a','b','c','d'],method='ffill',columns=states) 报错:ValueError: index must be monotonic increasing or decreasing 改成以下写法: frame.reindex(index=['a','b','c','d'],columns=states).ffill()
利用ix的标签索引功能,重新索引任务可以变得更简洁:
frame.ix[['a','b','c','d'],states]
问题记录:
在同时对行和列进行索引时,书中代码是:
frame.reindex(index=['a','b','c','d'],method='ffill',columns=states)
但是会出现错误:
ValueError: index must be monotonic increasing or decreasing
#不加ffill填充 frame.reindex(index=['a','b','c','d'],columns=states)
结果为
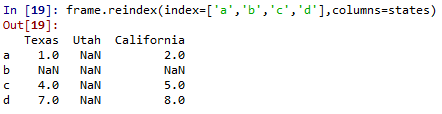
查找资料后自己初步理解为:为了重新索引方法,你的索引必须是有序/单调/递增的顺序,因为列也是重新索引的,而不是单调增加或减少。
书中的代码适合以前版本的pandas。
资料链接:https://stackoverflow.com/questions/44868877/valueerror-index-must-be-monotonic-increasing-or-decreasing-including-index-co/46893526#46893526
解决:
frame.reindex(index=['a','b','c','d'],columns=states).ffill()
上面写法可以达到与书中同样的结果。
参考链接:http://www.cnblogs.com/batteryhp/p/5006274.html
http://www.cnblogs.com/dataAnalysis/p/9287968.html