zipkin以mysql存储方式,部分源码分析
前言:这篇教程适合于已经看过zipkin的简单概念的伙伴,还不知道zipkin是什么的小伙伴请略过,zipkin学习传送门http://blog.csdn.net/liaokailin/article/details/52077620
本文配置:jdk8、 mysql(5.7)、 zipkin-server-2.4.3-exec.jar、 windows7 (有什么错误,欢迎指出,共同学习)
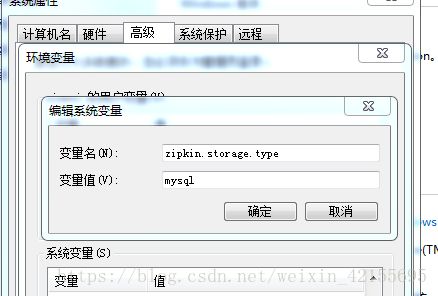
一、先配环境变量
zipkin.storage.type=mysql
二、先下载jar包
地址:https://repo1.maven.org/maven2/io/zipkin/java/zipkin-server 各种版本自己选(建议使用2.4.3,因为本人用过别的版本,各种连接不上数据库,头皮发麻,还好有dashen指点,发现是版本问题)
三、启动可执行jar
dos命令启动:
java -jar zipkin-server-2.4.3-exec.jar --STORAGE_TYPE=mysql --MYSQL_DB=zipkin --MYSQL_USER=root --MYSQL_PASS=root
解压jar包可以发现里面有很多子jar包以及文件,打开zipkin-server-shared.yml 第112行有mysql配置信息解释
配图在此: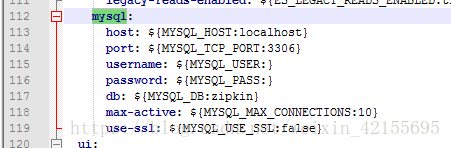
启动并且连接数据配图日志如下:
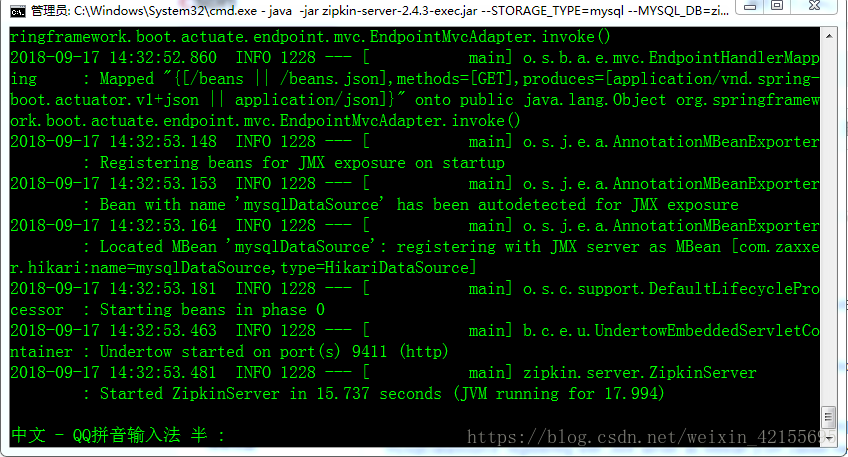
要注意日志中需要有DataSource等信息,如果没有就说明没有连接成功。
四、启动服务
我以Java的客户端Brave为例完成上面四个服务调用代码编写,源代码下载地址:https://github.com/dreamerkr/mircoservice.git文件夹springboot+zipkin下面。
五、创建数据库
创建数据库zipkin(源码中默认寻找的是zipkin)
sql脚本:
CREATE TABLE IF NOT EXISTS zipkin_spans (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL,
`id` BIGINT NOT NULL,
`name` VARCHAR(255) NOT NULL,
`parent_id` BIGINT,
`debug` BIT(1),
`start_ts` BIGINT COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL',
`duration` BIGINT COMMENT 'Span.duration(): micros used for minDuration and maxDuration query'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_spans ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `id`) COMMENT 'ignore insert on duplicate';
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`, `id`) COMMENT 'for joining with zipkin_annotations';
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTracesByIds';
ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT 'for getTraces and getSpanNames';
ALTER TABLE zipkin_spans ADD INDEX(`start_ts`) COMMENT 'for getTraces ordering and range';
CREATE TABLE IF NOT EXISTS zipkin_annotations (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.trace_id',
`span_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id',
`a_key` VARCHAR(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1',
`a_value` BLOB COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB',
`a_type` INT NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation',
`a_timestamp` BIGINT COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp',
`endpoint_ipv4` INT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_ipv6` BINARY(16) COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address',
`endpoint_port` SMALLINT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_service_name` VARCHAR(255) COMMENT 'Null when Binary/Annotation.endpoint is null'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `span_id`, `a_key`, `a_timestamp`) COMMENT 'Ignore insert on duplicate';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`, `span_id`) COMMENT 'for joining with zipkin_spans';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTraces/ByIds';
ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames';
ALTER TABLE zipkin_annotations ADD INDEX(`a_type`) COMMENT 'for getTraces';
ALTER TABLE zipkin_annotations ADD INDEX(`a_key`) COMMENT 'for getTraces';
CREATE TABLE IF NOT EXISTS zipkin_dependencies (
`day` DATE NOT NULL,
`parent` VARCHAR(255) NOT NULL,
`child` VARCHAR(255) NOT NULL,
`call_count` BIGINT
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_dependencies ADD UNIQUE KEY(`day`, `parent`, `child`);
六、访问项目http://localhost:8081/service1/test

七、访问localhost:9411,可以查看到链路,响应时长等信息。

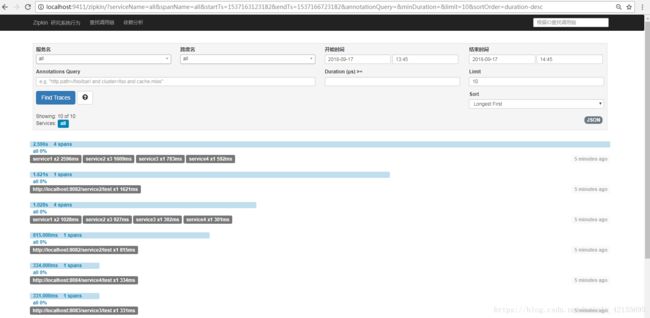
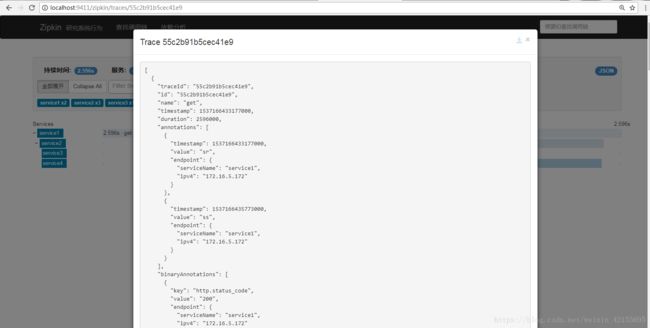
八、查看数据库

这个时候zipkin读取数据已经开始从数据库读取了,不在是从内存中读取,重启之后也不用担心数据丢失等问题。
九、数据库中数据疑虑
如果有需求导入日志实现图像化展示,相信有做过的伙伴会发现数据库存放的数据有一些不是图形化中json数据,而是一长串数字代替了这些json数据

zipkin源码地址:https://github.com/openzipkin/zipkin
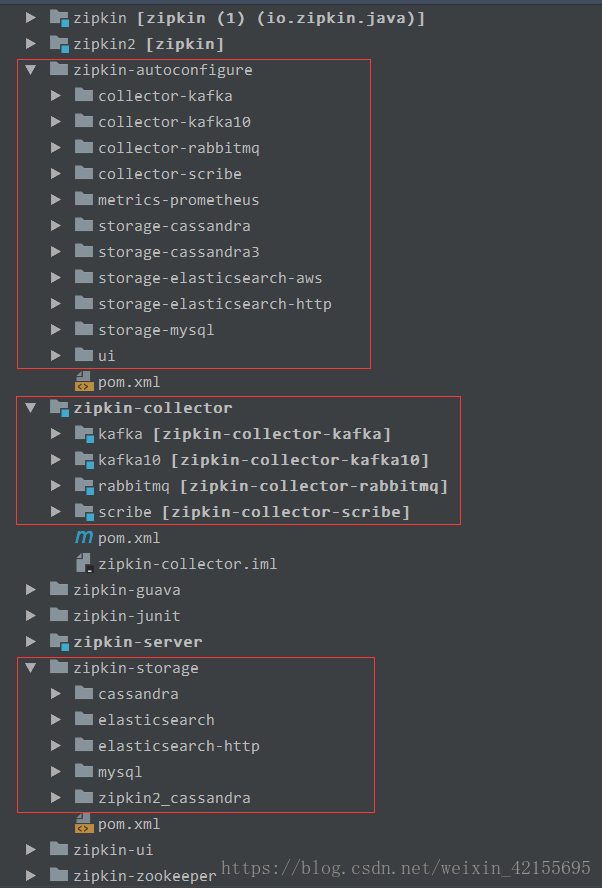
- zipkin - 对应的是zipkin v1
- zipkin2 - 对应的是zipkin v2
- zipkin-server - 是zipkin的web工程目录,zipkin.server.ZipkinServer是启动类
- zipkin-ui - zipkin ui工程目录,zipkin的设计师前后端分离的,zipkin-server提供数据查询接口,zipkin-ui做数据展现。
- zipkin-autoconfigure - 是为springboot提供的自动配置相关的类
collector-kafka
collector-kafka10
collector-rabbitmq
collector-scribe
metrics-prometheus
storage-cassandra
storage-cassandra3
storage-elasticsearch-aws
storage-elasticsearch-http
storage-mys
打开源码
zipkin-master\zipkin-master\zipkin-storage\mysql-v1\src\main\java\zipkin2\storage\mysql\v1\MySQLSpanConsumer.java
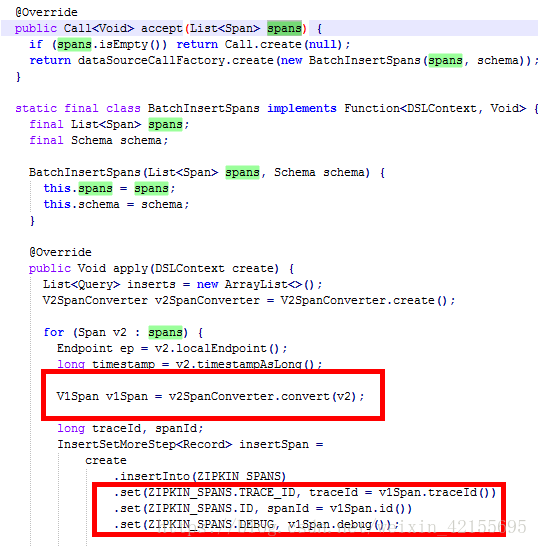
可以看到accept方法传进来装span的一个list,下面通过增强for循环遍历将值赋给了V1Span对象,点开V1Span才发现了新大陆
打开源码zipkin-master\zipkin-master\zipkin\src\main\java\zipkin2\v1\V1Span

重写了equals方法,hashcode方法,用了 >>> : 无符号右移,忽略符号位,空位都以0补齐,对图形中json数值进行了代替,保存到数据库。所以不一样,,,如果需要导日志进去,前面需要加这么一道程序。