股票数据爬虫(Scrapy框架与requests-bs4-re技术路线)
Scrapy
中文名:抓取
一个功能强大、快速、优秀的第三方库
它是软件结构与功能组件的结合,可以帮助用户快速实现爬虫。
Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
框架安装
使用管理员权限启动command控制台
\>pip install scrapy
测试安装
输入指令查看所有scrpy命令
\>scrapy -h
出现以下界面则可视为安装成功

我们还可以通过指令查看帮助信息:
\>scrapy --help
命令提示符输出如下:

Scrapy框架常用命令:

我们本次实验只用到了startproject、genspider和crawl命令
Scrapy“5+2”框架结构
5个主体部分:
已有的功能实现:
Engine 控制模块间的数据流、根据条件触发事件
Schedule 对所有爬取请求进行调度
Downloader 根据请求下载网页
需要配置实现:
Spiders 解析返回的响应、产生爬取项与新的爬取请求
Item Pipelines 清理、检验和查重爬取项中的数据与数据存储
2个中间键(可配置):
SpiderMiddleware 修改、丢弃、新增请求或爬取项
Downloader Middleware 修改、丢弃、新增请求或响应

1. Spiders向Engine发送网页信息爬取请求
2. Scheduler从Engine接收爬取请求并进行调度
3,4. Engine从Scheduler获得下一个网页信息爬取请求,通过中间键发送给Downloader
5,6. Downloader连接互联网爬取网页内容,形成响应(爬取内容)通过中间键与Engine发送给Spiders
7. Spiders处理获得的响应(爬取内容),形成爬取项与新的网页信息爬取请求发送给Engine
8. Engine将爬取项发送给Item Pipelines,将新的爬取请求发送给Scheduler进行调度,形成循环为数据处理与再次启动爬虫进行爬取提供数据。
功能概述:
· 技术:Scrapy
· 目标:获取上交所和深交所的股票名称与交易信息
· 输出:txt文档
获取股票列表:
· 东方财富网:http://quote.eastmoney.com/stocklist.html
获取个股信息:
· 股市通:https://gupiao.baidu.com/stock/sz002338.html
过程概述:
1. 编写spider爬虫处理链接的爬取和网页解析
2. 编写pipeline处理解析后的股票数据并存储
具体流程
· 相关安装
使用管理员权限启动command控制台
\>pip install requests
\>pip install scrapy
====================================
接下来的工程我刚开始运行失败,后通过以下四步才得以运行
(视个人情况而定)
#先卸载scrapy框架
1. pip uninstall scrapy
#再卸载twisted框架
2. pip uninstall twisted
重新安装scrapy以及16.6.0版本的twisted
#先安装twisted框架
3. pip install twisted==16.6.0
#再安装scrapy,--no-deps指不安装依赖的twisted
4. pip install scrapy--no-deps
如仍不能运行可能需要安装pywin32模块
\>pip install pywin32
· 建立工程和Spider模板
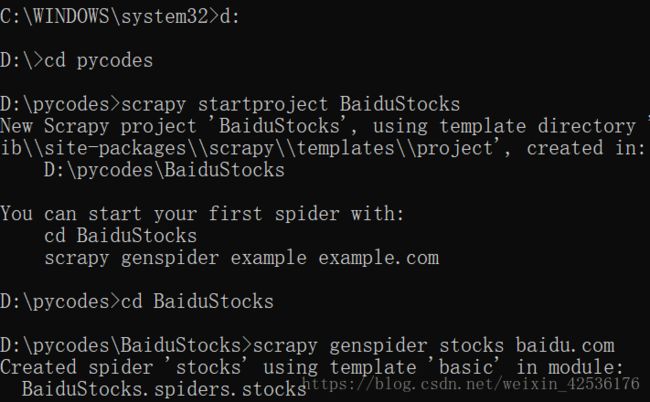
1. 转到目标目录
\>d:
\>cd pycodes
(注:目录位置不限定)
2. 生成BaiduStocks项目
\>scrapy startproject BaiduStocks
3. 修改当前目录
\>cd BaiduStocks
4. 生成stocks爬虫
\>scrapy genspider stocks baidu.com
· 编写spider
配置stocks.py
修改对返回页面与新增的URL爬取请求的处理,使其解析返回的信息
- import scrapy
- import re # 引入正则表达式库
- class StocksSpider(scrapy.Spider):
- name = "stocks"
- # 设置初始链接为股票列表页面链接
- start_urls = ['http://quote.eastmoney.com/stocklist.html']
- def parse(self, response): # 获取页面中股票代码并生成对应股票页面链接
- # for循环提取页面中所有标签中的链接
- for href in response.css('a::attr(href)').extract():
- # 使用try...except忽略错误信息
- try:
- # 通过正则表达式获取股票代码
- stock = re.findall(r"[s][hz]\d{6}", href)[0]
- # 生成对应股票代码的页面链接
- url = 'https://gupiao.baidu.com/stock/' + stock + '.html'
- # 使用yield将函数定义为生成器将新请求重新提交给scrapy
- yield scrapy.Request(url, callback=self.parse_stock)
- except:
- continue
- def parse_stock(self, response): # 从对应股票代码的页面提取信息
- infoDict = {} # 生成空字典
- stockInfo = response.css('.stock-bets') # 找到属性为"stock-bets"的区域
- # 在区域中检索"bets-name"属性提取股票名称
- name = stockInfo.css('.bets-name').extract()[0]
- # 提取股票中的其他信息存储为键值对
- keyList = stockInfo.css('dt').extract()
- valueList = stockInfo.css('dd').extract()
- for i in range(len(keyList)): # 将提取到的股票信息保存在字典中
- key = re.findall(r'>.*', keyList[i])[0][1:-5]
- try:
- val = re.findall(r'\d+\.?.*', valueList[i])[0][0:-5]
- except:
- val = '--'
- infoDict[key] = val
- # 保存对应股票代码的股票页面中的股票名称和相关信息
- infoDict.update(
- {'股票名称': re.findall('\s.*\(', name)[0].split()[0] + \
- re.findall('\>.*\<', name)[0][1:-1]})
- # 使用yield将函数定义为生成器传递信息给后续处理的pipeline模块
- yield infoDict
· 编写Pipelines
配置pipelines.py
定义对爬取项的处理类
- # -*- coding: utf-8 -*-
- # Define your item pipelines here
- #
- # Don't forget to add your pipeline to the ITEM_PIPELINES setting
- # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
- class BaidustocksPipeline(object):
- def process_item(self, item, spider):
- return item
- class BaidustocksInfoPipeline(object): # 尝试定义新类
- def open_spider(self, spider): # 爬虫调用时,对应启动的方法
- self.f = open('BaiduStockInfo.txt', 'w') # 打开文件
- def close_spider(self, spider): # 爬虫关闭时,对应启动的方法
- self.f.close() # 关闭文件
- def process_item(self, item, spider): # 对item项的处理方法
- try:
- line = str(dict(item)) + '\n'
- self.f.write(line) # 把每一个股票的字典信息写入文件中
- except:
- pass
- return item # 让其他函数也可以处理当前item
· 配置ITEM_PIPELINES选项
在settings.py找到以下代码块
- # ITEM_PIPELINES = {
- # 'BaiduStocks.pipelines.BaidustocksPipeline': 300,
- # }
将指向的pipelines修改为刚才定义的处理类BaidustocksInfoPipeline
- ITEM_PIPELINES = {
- 'BaiduStocks.pipelines.BaidustocksInfoPipeline': 300,
- }
· 运行爬虫
使用管理员权限启动command控制台
修改当前路径:
\>d:
\>cd pycodes
\>cd BaiduStocks
运行爬虫
\>scrapy crawl stocks

运行结束会在BaiduStocks文件夹生成BaiduStockInfo.txt
内容如下

我们还可以采用Beautiful Soup库与Requests库通过requests-bs4-re技术路线制作股票数据爬虫
Beautiful soup
BeautifulSoup是Python的一个库,最主要的功能就是从网页爬取我们需要的数据。BeautifulSoup将html解析为对象进行处理,全部页面转变为字典或者数组,相对于正则表达式的方式,可以大大简化处理过程。
BeautifulSoup默认支持Python的标准HTML解析库,但是它也支持一些第三方的解析库:
解析库 |
使用方法 |
优势 |
劣势 |
Python标准库 |
BeautifulSoup(html,’html.parser’) |
Python内置标准库;执行速度快 |
容错能力较差 |
lxml HTML解析库 |
BeautifulSoup(html,’lxml’) |
速度快;容错能力强 |
需要安装,需要C语言库 |
lxml XML解析库 |
BeautifulSoup(html,[‘lxml’,’xml’]) |
速度快;容错能力强;支持XML格式 |
需要C语言库 |
htm5lib解析库 |
BeautifulSoup(html,’htm5llib’) |
以浏览器方式解析,最好的容错性 |
速度慢 |
Requests
目前公认的爬取网页最好的第三方库
简单,简洁,甚至只用一行代码就可以从网页上获得相关资源
Requests库的七个主要方法:

具体实现
安装相关库,使用管理员权限启动command控制台
\>pip install beautifulsoup4
\>pip install requests
测试安装Requests库

出现以下界面则可视为成功安装Requests库

测试安装Beautiful Soup库

出现以下界面即可视为安装成功Beautiflu Soup库

· 代码实现
- import requests
- from bs4 import BeautifulSoup
- import traceback # 引用traceback库方便调试
- import re
- # 获得url对应的页面,第二个参数为编码方式
- def getHTMLText(url, code="utf-8"):
- try: # 使用try...except规避错误信息
- r = requests.get(url) # 通过get函数获取url信息
- r.raise_for_status() # 产生异常信息
- r.encoding = code # 直接修改编码方式提高效率
- return r.text # 将信息返回给程序的其他部分
- except:
- return "" # 出现错误则返回空字符串
- def getStockList(lst, stockURL):
- # 获得股票的信息列表,第一个参数为列表类型,第二个为获得信息的url
- html = getHTMLText(stockURL, "GB2312") # 获得股票列表页面
- # 使用beautifulsoup解析页面
- soup = BeautifulSoup(html, 'html.parser')
- a = soup.find_all('a') # 找到页面中所有标签
- for i in a:
- try: # 使用try...except规避错误信息
- href = i.attrs['href'] # 找到标签中所有href属性
- # 分析源代码通过正则表达式获得每只股票代码并存储到lst
- lst.append(re.findall(r"[s][hz]\d{6}", href)[0])
- except:
- continue
- # 第一参数为保存信息的列表,第二为获取信息的url,第三为存储信息的文件路径
- def getStockInfo(lst, stockURL, fpath): # 获得每一只股票的信息并存储
- count = 0
- for stock in lst: # 获取每一只股票代码
- url = stockURL + stock + ".html" # 构造具体股票页面url
- html = getHTMLText(url) # 获取具体股票页面信息
- try: # 使用try...except规避错误信息
- if html == "": # 判断是否为空页面
- continue
- infoDict = {} # 生成空字典
- # 构建解析网页的类型
- soup = BeautifulSoup(html, 'html.parser')
- # 找到属性为"stock-bets"的区域
- stockInfo = soup.find('div', attrs={'class': 'stock-bets'})
- # 在区域中检索"bets-name"属性提取股票名称
- name = stockInfo.find_all(attrs={'class': 'bets-name'})[0]
- # 将提取到的股票名称保存在字典中
- infoDict.update({'股票名称': name.text.split()[0]})
- # 提取股票中的其他信息并存储为键值对形式
- keyList = stockInfo.find_all('dt')
- valueList = stockInfo.find_all('dd')
- for i in range(len(keyList)): # 将股票其他信息存入字典
- key = keyList[i].text
- val = valueList[i].text
- infoDict[key] = val
- # 将信息保存到制定目录文件
- with open(fpath, 'a', encoding='utf-8') as f:
- f.write(str(infoDict) + '\n')
- count = count + 1
- # 显示当前爬取进度百分比提高用户体验
- print("\r当前进度: {:.2f}%".format(count * 100 / len(lst)), end="")
- except:
- count = count + 1
- print("\r当前进度: {:.2f}%".format(count * 100 / len(lst)), end="")
- continue
- def main():
- # 获取股票列表的url
- stock_list_url = 'http://quote.eastmoney.com/stocklist.html'
- # 获取每一只股票具体信息的初始url
- stock_info_url = 'https://gupiao.baidu.com/stock/'
- # 输出文件的保存路径
- output_file = 'D:/BaiduStockInfo.txt'
- slist = [] # 股票信息变量
- getStockList(slist, stock_list_url) # 获得股票列表
- getStockInfo(slist, stock_info_url, output_file) # 获取相关股票信息并存储
- # 执行主函数
- main()
在这里我们尝试使用PyCharm运行这个程序
PyCharm是一种Python IDE,带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制。此外,该IDE提供了一些高级功能,以用于支持Django框架下的专业Web开发。
首先我们需要新建工程

输入工程名点确定

在工程中点击右键新建python文件

输入python文件名,点击保存

导入bs4库与requests库
1.点击File->settings

2.选择Project Interpreter,点击右边绿色的加号添加包

3.输入你想添加的包名,点击Install Package

4.可以在Pycharm保存项目的目录下查看已经安装的包,路径D:\PycharmProjects\untitled\venv\Lib\site-packages(大致路径)
5.配置完成后,输入程序代码,点击上方的Run即可运行程序

BeautifulSoup库与Requests框架通过requests-bs4-re技术路线实现的爬虫执行速度相对较慢。
总结
通过本次Python实验,我学习到了第三方库的安装与使用,深化了对PyCharm及IDLE的使用,对Scrapy框架、BeautifulSoup库与Requests框架以及requests-bs4-re技术路线有了进一步的认识,对正则表达式的编写和Python的程序结构也有了更深入的了解,增加了Python的编程经验。