Python网络爬虫之制作股票数据定向爬虫 以及爬取的优化 可以显示进度条!
候选网站:
新浪股票:http://finance.sina.com.cn/stock/
百度股票:https://gupiao.baidu.com/stock/
选取原则:
- 无robots协议
- 非js网页
- 数据在HTMLK页面中的
F12,查看源代码,即可查看。
新浪股票,使用JS制作。脚本生成的数据。
百度股票可以在HTML中查询到!
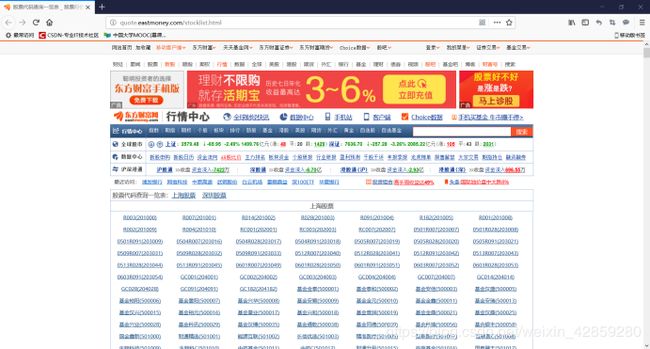
http://quote.eastmoney.com/stocklist.html
这个地址可以查询股票详细列表!
程序思路:
1. 获取股票列表
2. 根据列表信息到百度获取个股信息2,根据列表信息到百度获取个股信息
3. 将结果存储
考虑用字典作为数据容器进行存储!
火狐浏览器可以查看源代码,蓝色的IE浏览器就会出现乱码:
火狐的:
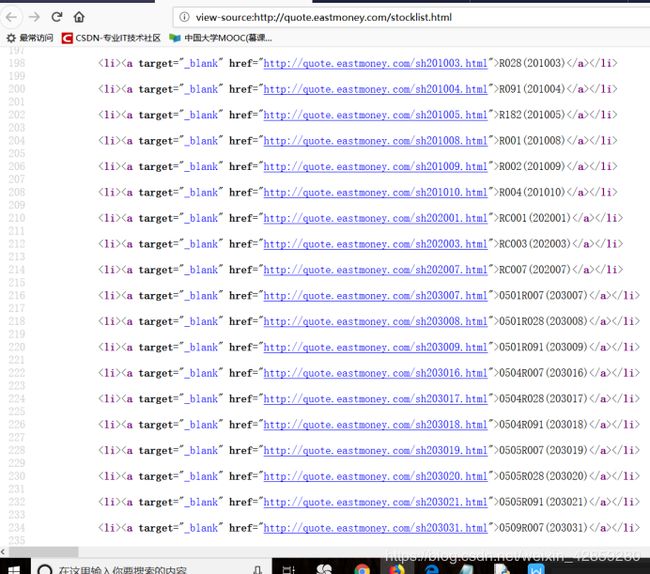
因为a标签,太多所以正则表达式匹配比较困难。
可用try except来解决!

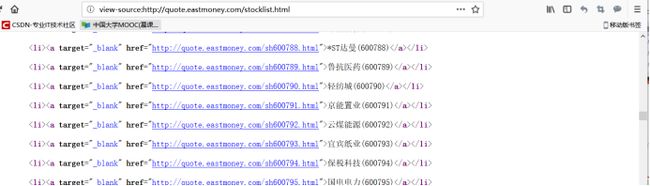
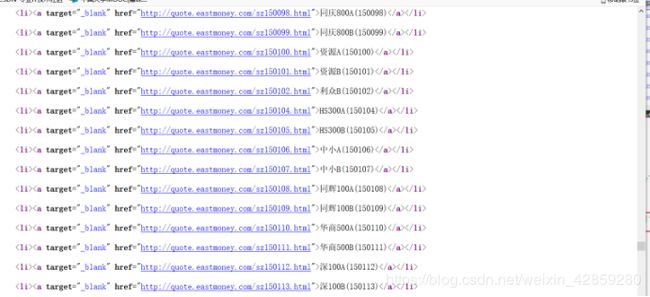
[s]:表示s。[hz]:表示h z。后面是随意6个数。
SH:
SZ:
优化:

- r.encoding:仅从头部获得
- r.apparent_encoding:是从全文获得的。r.apparent_encoding:是从全文获得的。
优化就是将编码直接给代码,另外一个就是显示进度。
下面就是代码部分啦:
最初的代码:(真长)
import requests
from bs4 import BeautifulSoup
import traceback
import re
def getHTMLText(url):
try:
r = requests.get(url, timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def getStockList(lst, stockURL):
html = getHTMLText(stockURL)
soup = BeautifulSoup(html, 'html.parser')
a = soup.find_all('a')
for i in a:
try:
href = i.attrs['href']
lst.append(re.findall(r"[s][hz]\d{6}",href)[0])
except:
continue
def getStockInfo(lst, stockURL, fpath):
for stock in lst:
url = stockURL + stock + ".html"
html = getHTMLText(url)
try:
if html == "":
continue
infoDict = {}
soup = BeautifulSoup(html, 'html.parser')
stockInfo = soup.find('div', attrs={'class':'stock-bets'})
name = stockInfo.find_all(attrs={'class':'bets-name'})[0]
infoDict.update({'股票名称':name.text.split()[0]})
keyList = stockInfo.find_all('dt')
valueList = stockInfo.find_all('dd')
for i in range(len(keyList)):
key = keyList[i].text
val = valurList[i].text
infoDict[key] = val
with open(fpath, 'a', encoding='utf-8') as f:
f.write(str(infoDict) + '\n')
except:
traceback.print_exc()
continue
def main():
stock_list_url = 'https://quote.eastmoney.com/stocklist.html'
stock_info_url = 'https://gupiao.baidu.com/stock/'
output_file = 'D:\234.txt'
slist = []
getStockList(slist, stock_list_url)
getStockInfo(slist, stock_info_url, output_file)
main()
代码执行结果;

优化后的代码:
import requests
from bs4 import BeautifulSoup
import traceback
import re
def getHTMLText(url,code='utf-8'):#默认的是utf-8
try:
r = requests.get(url, timeout = 30)
r.raise_for_status()
r.encoding = code#直接赋值
return r.text
except:
return ""
def getStockList(lst, stockURL):
html = getHTMLText(stockURL,'GB2312')#已经查询过啦!
soup = BeautifulSoup(html, 'html.parser')
a = soup.find_all('a')
for i in a:
try:
href = i.attrs['href']
lst.append(re.findall(r"[s][hz]\d{6}",href)[0])
except:
continue
def getStockInfo(lst, stockURL, fpath):
count = 0
for stock in lst:
url = stockURL + stock + ".html"
html = getHTMLText(url)
try:
if html == "":
continue
infoDict = {}
soup = BeautifulSoup(html, 'html.parser')
stockInfo = soup.find('div', attrs={'class':'stock-bets'})
name = stockInfo.find_all(attrs={'class':'bets-name'})[0]
infoDict.update({'股票名称':name.text.split()[0]})
keyList = stockInfo.find_all('dt')
valueList = stockInfo.find_all('dd')
for i in range(len(keyList)):
key = keyList[i].text
val = valurList[i].text
infoDict[key] = val
with open(fpath, 'a', encoding='utf-8') as f:
f.write(str(infoDict) + '\n')
count = count +1
print('\r当前速度:{:.2f}%'.format(count*100/len(lst)),end=' ')
except:
count = count +1
print('\r当前速度:{:.2f}%'.format(count*100/len(lst)),end=' ')
traceback.print_exc()
continue
def main():
stock_list_url = 'https://quote.eastmoney.com/stocklist.html'
stock_info_url = 'https://gupiao.baidu.com/stock/'
output_file = 'D:\234.txt'
slist = []
getStockList(slist, stock_list_url)
getStockInfo(slist, stock_info_url, output_file)
main()
提前给出了编码方式以及可以显示进度条的代码
给出编码方式的代码:
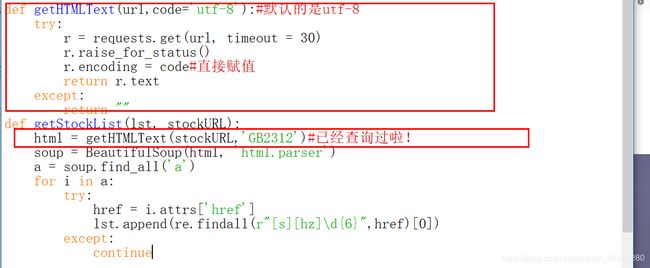
def getHTMLText(url,code='utf-8'):#默认的是utf-8
try:
r = requests.get(url, timeout = 30)
r.raise_for_status()
r.encoding = code#直接赋值
return r.text
except:
return ""
def getStockList(lst, stockURL):
html = getHTMLText(stockURL,'GB2312')#已经查询过啦!
soup = BeautifulSoup(html, 'html.parser')
a = soup.find_all('a')
for i in a:
try:
href = i.attrs['href']
lst.append(re.findall(r"[s][hz]\d{6}",href)[0])
except:
continue
照片:
(如果不是utf-8,就要提前给替换掉!)
可以显示进度条的代码
def getStockInfo(lst, stockURL, fpath):
count = 0
for stock in lst:
url = stockURL + stock + ".html"
html = getHTMLText(url)
try:
if html == "":
continue
infoDict = {}
soup = BeautifulSoup(html, 'html.parser')
stockInfo = soup.find('div', attrs={'class':'stock-bets'})
name = stockInfo.find_all(attrs={'class':'bets-name'})[0]
infoDict.update({'股票名称':name.text.split()[0]})
keyList = stockInfo.find_all('dt')
valueList = stockInfo.find_all('dd')
for i in range(len(keyList)):
key = keyList[i].text
val = valurList[i].text
infoDict[key] = val
with open(fpath, 'a', encoding='utf-8') as f:
f.write(str(infoDict) + '\n')
count = count +1
print('\r当前速度:{:.2f}%'.format(count*100/len(lst)),end=' ')
except:
count = count +1
print('\r当前速度:{:.2f}%'.format(count*100/len(lst)),end=' ')
traceback.print_exc()
continue
照片:
 不过,显示进度在IDLE那里不可以显示。
不过,显示进度在IDLE那里不可以显示。
但是最后我也没成功有文件生成以及显示进度条,算啦。先去吃饭啦~