数据结构之二叉树(java语言版)
数据结构之二叉树(java语言版)
数据结构与算法学习目录
之前的都是线性结构,而树结构在计算机应用中的应用更加广泛。linux中的目录结构,某些数据库的底层存储等,都是采用树结构进行构架的。
树的概念
线性表是一对一的关系,而树是一对多的关系。
树的结点:包含一个数据元素及若干指向子树的分支;
孩子结点:结点的子树的根称为该结点的孩子;
双亲结点:B 结点是A 结点的孩子,则A结点是B 结点的双亲;
兄弟结点:同一双亲的孩子结点; 堂兄结点:同一层上结点;
祖先结点: 从根到该结点的所经分支上的所有结点
子孙结点:以某结点为根的子树中任一结点都称为该结点的子孙
结点层:根结点的层定义为1;根的孩子为第二层结点,依此类推;
树的深度:树中最大的结点层
结点的度:结点子树的个数
树的度: 树中最大的结点度。
叶子结点:也叫终端结点,是度为 0 的结点;
分枝结点:度不为0的结点;
有序树:子树有序的树,如:家族树;
无序树:不考虑子树的顺序;
二叉树
最常用的树结构是二叉树。在计算机科学中,二叉树是每个结点最多有两个子树的树结构。通常子树被称作“左子树”和“右子树”。
1. 二叉树的性质
二叉树有以下几个性质:TODO(上标和下标)
性质1:二叉树第i层上的结点数目最多为 2**{i-1}** (i≥1)。
性质2:深度为k的二叉树至多有2{k}-1个结点(k≥1)。
性质3:包含n个结点的二叉树的高度至少为log2 (n+1)。
性质4:在任意一棵二叉树中,若终端结点的个数为n0,度为2的结点数为n2,则n0=n2+1。
2、二叉树的种类
完全二叉树
若设二叉树的高度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第h层有叶子结点,并且叶子结点都是从左到右依次排布,这就是完全二叉树。
满二叉树
除了叶子结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树
平衡二叉树
它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
3、二叉树的遍历方式
先序遍历
先访问根节点,先序遍历左子树,先序遍历右子树
中序遍历
中序遍历左子树,访问根节点,中序遍历右子树
后序遍历
后序遍历左子树,后序遍历右子树,访问根节点
层次遍历
即按照层次访问,通常用队列来做。访问根,访问子女,再访问子女的子女
4、二叉树的存储方式
1、顺序存储
用一组连续的存储单元存放二叉树的数据元素。结点在数组中的相对位置蕴含着结点之间的关系。
比较浪费空间,基本不用。
2、链式存储
链式存储结构的每个结点由数据域、左指针域和右指针域组成。左指针和右指针分别指向下一层的二叉树。
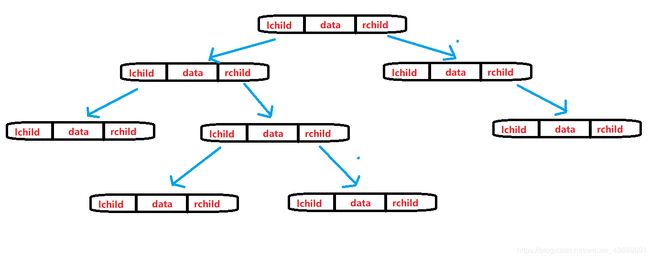
5、实现
节点类
class Node {// 节点
String data;
Node rchild;
Node lchild;
boolean isDel;// 标识是否被删除
public Node(String data) {// 构造方法,传入节点数据
this.data = data;
this.isDel = false;
}
public Node() {//构造方法
}
}
建立树
树默认使用先序遍历的顺序进行建立。
public class BinTree {
public BinTree() {// 构造方法
}
public Node init(Node root) {// 先序遍历的格式初始化
String data;
System.out.println("输入节点数据:");
Scanner scanner = new Scanner(System.in);
data = scanner.next(); //输入节点存储的数据
if (data.equals("0")) {//设0为null,即不存在
System.out.println("该节点为null");
} else {
System.out.println("data: " + data);
root = new Node(data);
root.lchild = init(root.lchild);//递归左孩子
root.rchild = init(root.rchild);//递归右孩子
}
return root;
}
}
遍历
使用递归进行遍历。
public void preOrder(Node root) {// 先序遍历
if (root == null) {//递归终止条件,某个节点为null时结束
return;
}
System.out.print(" " + root.data);//遍历根节点
preOrder(root.lchild);//遍历左节点,直到某个左节点为null
preOrder(root.rchild);//遍历右节点,直到某个右节点为null
}
public void midOrder(Node root) {// 中序遍历
if (root == null) {
return;
}
midOrder(root.lchild);
System.out.print(" " + root.data);
midOrder(root.rchild);
}
public void lastOrder(Node root) {// 后序遍历
if (root == null) {
return;
}
lastOrder(root.lchild);
lastOrder(root.rchild);
System.out.print(" " + root.data);
}
测试
这是一个测试类,输入节点数据建立一个树后,进行遍历。
public static void main(String[] args) {
BinTree binTree=new BinTree();
Node root=binTree.init(new Node());
System.out.println("先序遍历树:");
binTree.preOrder(root);
System.out.println("\n中序遍历树:");
binTree.midOrder(root);
System.out.println("\n后序遍历树:");
binTree.lastOrder(root);
}
就拿这个树作为模型测试。
输入0代表节点不存在,所以按照先序建立树,输入数据应该是:
ABC000DE00F00

输入数据:
输入节点数据:
A
data: A
输入节点数据:
B
data: B
输入节点数据:
C
data: C
输入节点数据:
0
该节点为null
输入节点数据:
0
该节点为null
输入节点数据:
0
该节点为null
输入节点数据:
D
data: D
输入节点数据:
E
data: E
输入节点数据:
0
该节点为null
输入节点数据:
0
该节点为null
输入节点数据:
F
data: F
输入节点数据:
0
该节点为null
输入节点数据:
0
该节点为null
输出遍历结果:
先序遍历树:
A B C D E F
中序遍历树:
C B A E D F
后序遍历树:
C B E F D A
插入删除
关于插入和删除,由于树不是线性的,插入的位置有很多选择。对于以上的测试二叉树来说增加一个节点就有很多位置可以,若是插入那么位置就更多了。
对于数据的增加和删除需要更多的约束,避免产生极端的树。
加入不同的约束会产生不同的树,如哈夫曼树,搜索树等。
不同的树有不同的优势,用于满足需求。

数据结构与算法学习目录