超简单,Python爬取阴阳师游戏原声
Python爬取阴阳师游戏BGM,附完整代码
- 爬取阴阳师游戏原声
- 网页分析
- 教程开始
- 1 请求json文件并获取数据
- 2 保存文件
- 注意,一定要看
- 结语
- 完整源码
目标网址:https://yys.163.com/media/music.html
结果展示:

爬取阴阳师游戏原声
《阴阳师》作为一款和风巨制手游,不仅式神原画精美,而且其游戏中的配乐的制作也是十分用心,网易也在游戏官网给出了游戏原声供大家欣赏,我们今天就用爬虫来将这些BGM下载到本地。
目标:爬取所有BGM
网页分析
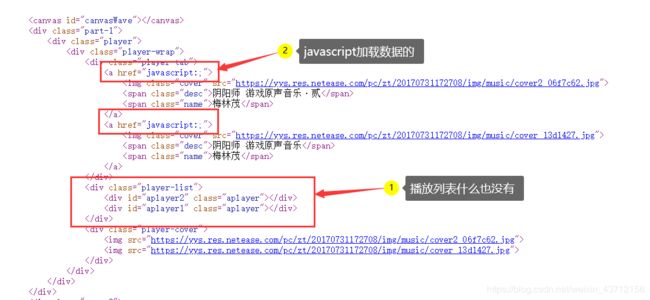
首先打开网页链接,先审查元素1,经过一番查找,在网页中代码中并没有找到BGM的链接,再检察源代码,发现1源代码中播放列表是空的,而且2两个播放标签的href都不是链接,是javascript,所以我们断定这些BGM都是从json文件中加载的。
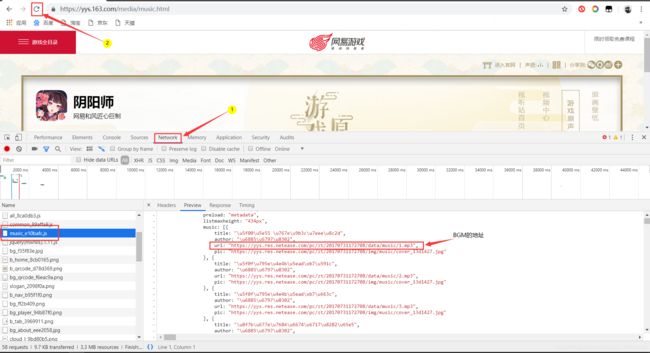
我们再次打开开发者工具(同审查元素,按F12进入),点击Network,然后刷新网页,会发现多了很多文件出来,我们在music_e10bafc.js文件中找到了BGM的地址,标题、还有作者等信息
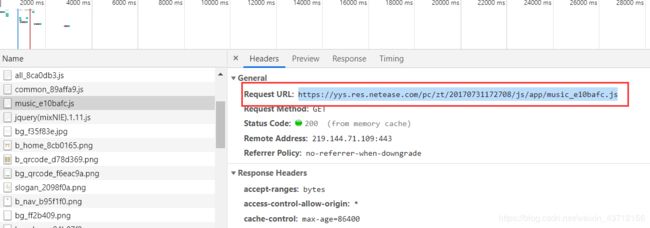
那么我们需要的数据都是存放在music_e10bafc.js的文件中的,我们需要从这个文件中拿出我们需要的数据,在Headers中,我们可以得到该文件的请求地址:https://yys.res.netease.com/pc/zt/20170731172708/js/app/music_e10bafc.js,请求方式为GET
分析完之后就可以开始了
教程开始
1 请求json文件并获取数据
在对网页进行分析过后,我们需要请求的是json文件而不是html文件,所以请求地址应对应json文件的地址,因为该文件较为复杂,解析json文件会使代码运行成本增加,所以我们直接用正则表达式来获取我们需要的数据
正则
title:"\u6de1\u96ea"
title:"(.*?)"
这样就可以获得 \u6de1\u96ea
zip()函数
zip()是Python的一个内置函数,它接受一系列可迭代的对象作为参数,将对象中对应的元素打包成一个个tuple(元组),然后返回由这些tuples组成的list(列表)。若传入参数的长度不等,则返回list的长度和参数中长度最短的对象相同。也就是说,该函数返回一个以元组为元素的列表,其中第 i 个元组包含每个参数序列的第 i 个元素。
def url_get():
# url 是 music_e10bafc.js 的请求地址
url = 'https://yys.res.netease.com/pc/zt/20170731172708/js/app/music_e10bafc.js'
response = requests.get(url).text # 获得该文件的文本
title_list = re.findall('title:"(.*?)"', response) # 标题
author_list = re.findall('author:"(.*?)"', response) # 作者
url_list = re.findall('url:"(.*?)"', response) # 链接
return zip(title_list, author_list, url_list)
2 保存文件
通过url_get()函数,向我们返回了一个以元组为元素的列表,我们可以循环取出数据,调用保存文件的函数保存文件
content = url_get()
for title, author, link in content:
music_get(title, author, link) # 保存文件的函数
music_get(title, author, link)函数用来保存文件,该函数有三个参数title、author和link分别是标题,作者和链接,标题和作者用来给文件命名。
def music_get(title, author, link):
'''
功能:保存mp3文件
:param title: MP3标题
:param author: MP3作者
:param link: MP3的链接
:return: None
'''
music = requests.get(link)
name = title.encode().decode('unicode_escape') + '-' + author.encode().decode('unicode_escape')
if music.status_code == 200:
open(f'{name}.mp3', 'wb').write(music.content)
print(f'{name} 下载成功')
else:
print(f'{name} 下载失败')
注意,一定要看
title.encode().decode('unicode_escape')是为了将unicode编码的\u6de1\u96ea转换为中文显示
name = title.encode().decode('unicode_escape') + '-' + author.encode().decode('unicode_escape')
结语
本次爬虫代码稍微有了一点难度,相比于前两次有所不同。首先,数据来源不同,本次爬虫的数据并不是直接来自于网页,而是打开网页后才从json文件中加载到网页上的,这种异步加载的方式的处理相对来说较为复杂,对json文件的解析,本次教程并没有使用其他方法,而是直接通过正则表达式来获取数据的,相比于解析网页或解析js文件,减小了程序运行的开销。其次,json文件中的中文使用了unicode的编码方式,需要将’\u6de1\u96ea’转换为中文显示,这也使本次爬虫有了些许困难。
非常感谢大家的观看,如果对于本期教程有任何疑问,欢迎留言,如果觉地我的文章不错,也欢迎点赞收藏。
往期回顾:
《超简单,Python爬取阴阳师式神视频》
《超简单,Python爬取阴阳师原画壁纸》
完整源码
# _*_ coding: utf-8 _*_
# 开发团队:独狼科技
# 开发人员:No Moon No Sun
# 开发时间:2020/4/16 11:02
# 文件名称:yys_music.py
# 开发工具:PyCharm
import os
import re
import requests
def url_get():
# url 是 music_e10bafc.js 的请求地址
url = 'https://yys.res.netease.com/pc/zt/20170731172708/js/app/music_e10bafc.js'
response = requests.get(url).text # 获得该文件的文本
title_list = re.findall('title:"(.*?)"', response) # 标题
author_list = re.findall('author:"(.*?)"', response) # 作者
url_list = re.findall('url:"(.*?)"', response) # 链接
return zip(title_list, author_list, url_list) # zip() 函数的使用
def music_get(title, author, link):
'''
功能:保存mp3文件
:param title: MP3标题
:param author: MP3作者
:param link: MP3的链接
:return: None
'''
music = requests.get(link)
# 编码转换,使用unicode方式解码,转换为中文
name = title.encode().decode('unicode_escape') + '-' + author.encode().decode('unicode_escape')
if music.status_code == 200:
open(f'{name}.mp3', 'wb').write(music.content)
print(f'{name} 下载成功')
else:
print(f'{name} 下载失败')
if __name__ == '__main__':
if not os.path.exists('./游戏原声'):
os.mkdir('./游戏原声')
os.chdir('./游戏原声')
content = url_get()
for title, author, link in content:
music_get(title, author, link) #调用保存文件的函数
以chrome浏览器为例:在网页空白处右键、检查就可以审查元素了。 ↩︎