Python网络爬虫步骤是什么?新手小白必看 !
python网络爬虫步骤:首先准备所需库,编写爬虫调度程序;然后编写url管理器,并编写网页下载器;接着编写网页解析器;最后编写网页输出器即可。

本教程操作环境:windows7系统、python3.9版,DELL G3电脑。
文末领取全套Python爬虫学习资源
python网络爬虫步骤
(1)准备所需库
我们需要准备一款名为BeautifulSoup(网页解析)的开源库,用于对下载的网页进行解析,我们是用的是PyCharm编译环境所以可以直接下载该开源库。
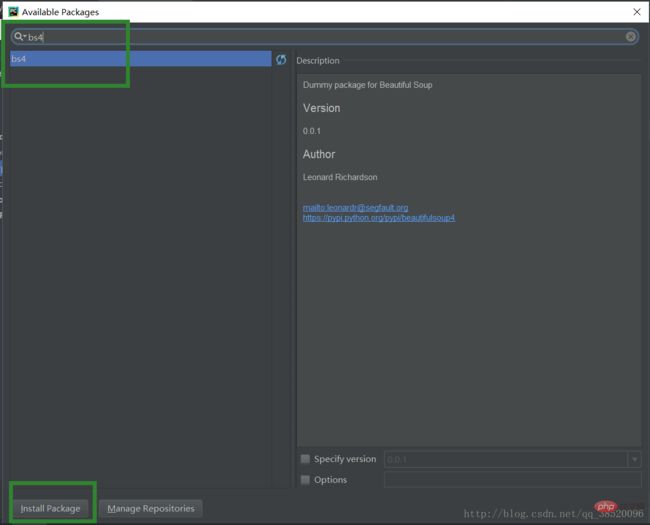
步骤如下:
选择File->Settings

打开Project:PythonProject下的Project interpreter

点击加号添加新的库

输入bs4选择bs4点击Install Packge进行下载
(2)编写爬虫调度程序
这里的bike_spider是项目名称引入的四个类分别对应下面的四段代码url管理器,url下载器,url解析器,url输出器。
# 爬虫调度程序
from bike_spider import url_manager, html_downloader, html_parser, html_outputer
# 爬虫初始化
class SpiderMain(object):
def __init__(self):
self.urls = url_manager.UrlManager()
self.downloader = html_downloader.HtmlDownloader()
self.parser = html_parser.HtmlParser()
self.outputer = html_outputer.HtmlOutputer()
def craw(self, my_root_url):
count = 1
self.urls.add_new_url(my_root_url)
while self.urls.has_new_url():
try:
new_url = self.urls.get_new_url()
print("craw %d : %s" % (count, new_url))
# 下载网页
html_cont = self.downloader.download(new_url)
# 解析网页
new_urls, new_data = self.parser.parse(new_url, html_cont)
self.urls.add_new_urls(new_urls)
# 网页输出器收集数据
self.outputer.collect_data(new_data)
if count == 10:
break
count += 1
except:
print("craw failed")
self.outputer.output_html()
if __name__ == "__main__":
root_url = "http://baike.baidu.com/item/Python/407313"
obj_spider = SpiderMain()
obj_spider.craw(root_url)
(3)编写url管理器
我们把已经爬取过的url和未爬取的url分开存放以便我们不会重复爬取某些已经爬取过的网页。
# url管理器
class UrlManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set()
def add_new_url(self, url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
def add_new_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.new_urls.add(url)
def get_new_url(self):
# pop方法会帮我们获取一个url并且移除它
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
def has_new_url(self):
return len(self.new_urls) != 0
(4)编写网页下载器
通过网络请求来下载页面
# 网页下载器
import urllib.request
class HtmlDownloader(object):
def download(self, url):
if url is None:
return None
response = urllib.request.urlopen(url)
# code不为200则请求失败
if response.getcode() != 200:
return None
return response.read()
(5)编写网页解析器
对网页进行解析时我们需要知道我们要查询的内容都有哪些特征,我们可以打开一个网页点击右键审查元素来了解我们所查内容的共同之处。
# 网页解析器
import re
from bs4 import BeautifulSoup
from urllib.parse import urljoin
class HtmlParser(object):
def parse(self, page_url, html_cont):
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont, "html.parser", from_encoding="utf-8")
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
def _get_new_data(self, page_url, soup):
res_data = {"url": page_url}
# 获取标题
title_node = soup.find("dd", class_="lemmaWgt-lemmaTitle-title").find("h1")
res_data["title"] = title_node.get_text()
summary_node = soup.find("p", class_="lemma-summary")
res_data["summary"] = summary_node.get_text()
return res_data
def _get_new_urls(self, page_url, soup):
new_urls = set()
# 查找出所有符合下列条件的url
links = soup.find_all("a", href=re.compile(r"/item/"))
for link in links:
new_url = link['href']
# 获取到的url不完整,学要拼接
new_full_url = urljoin(page_url, new_url)
new_urls.add(new_full_url)
return new_urls
(6)编写网页输出器
输出的格式有很多种,我们选择以html的形式输出,这样我们可以的到一个html页面。
# 网页输出器
class HtmlOutputer(object):
def __init__(self):
self.datas = []
def collect_data(self, data):
if data is None:
return
self.datas.append(data)
# 我们以html表格形式进行输出
def output_html(self):
fout = open("output.html", "w", encoding='utf-8')
fout.write("")
fout.write("")
fout.write("")
# 以表格输出
fout.write("")
for data in self.datas:
# 一行
fout.write("")
# 每个单元行的内容
fout.write("%s " % data["url"])
fout.write("%s " % data["title"])
fout.write("%s " % data["summary"])
fout.write(" ")
fout.write("
")
fout.write("")
fout.write("")
# 输出完毕后一定要关闭输出器
fout.close()
以上就是今天的全部内容分享,觉得有用的话欢迎点赞收藏哦!
Python经验分享
学好 Python 不论是用于就业还是做副业赚钱都不错,而且学好Python还能契合未来发展趋势——人工智能、机器学习、深度学习等。
小编是一名Python开发工程师,自己整理了一套最新的Python系统学习教程,包括从基础的python脚本到web开发、爬虫、数据分析、数据可视化、机器学习等。如果你也喜欢编程,想通过学习Python转行、做副业或者提升工作效率,这份【最新全套Python学习资料】 一定对你有用!
对于0基础小白入门:
如果你是零基础小白,想快速入门Python可以考虑培训
- 学习时间相对较短,学习内容更全面更集中
- 可以找到适合自己的学习方案
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习、Python量化交易等学习教程。带你从零基础系统性的学好Python!
最新全套【Python入门到进阶资料 & 实战源码 &安装工具】(安全链接,放心点击)
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


我已经上传至CSDN官方,如果需要可以扫描下方官方二维码免费获取【保证100%免费】

*今天的分享就到这里,喜欢且对你有所帮助的话,记得点赞关注哦~下回见 !