京东商品的爬取
这里写自定义目录标题
- 前言
- 代码
- 下面来说下整体代码思路吧和每个自定义的功能和自己做的小处理
- 流程图
前言
这学期学了python爬虫,所以用python写了一个爬取京东商品关注信息的程序,由于这是我的第一篇CSDN,所以可能格式都不是很好看,希望见谅。
代码
下面就直接上代码好了
其中selenium对应的安装参考这里说的很详细了
selenium对应三大浏览器(谷歌、火狐、IE)驱动安装.
requests 和 BeatifulSoup需要用管理员权限进入cmd使用pip install XXXX来安装
其它直接在pycharm里面直接导入就可以了
//encoding = 'utf-8'
import requests
from lxml import etree
import csv
from bs4 import BeautifulSoup
from selenium import webdriver
import re
def getHTMLText(goods):
url = 'https://search.jd.com/Search?keyword='+ goods+ '&enc=utf-8'
head={'authority': 'search.jd.com',
'method': 'GET',
'path': '/s_new.php?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E6%89%8B%E6%9C%BA&cid2=653&cid3=655&page=4&s=84&scrolling=y&log_id=1529828108.22071&tpl=3_M&show_items=7651927,7367120,7056868,7419252,6001239,5934182,4554969,3893501,7421462,6577495,26480543553,7345757,4483120,6176077,6932795,7336429,5963066,5283387,25722468892,7425622,4768461',
'scheme': 'https',
'referer': 'https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E6%89%8B%E6%9C%BA&cid2=653&cid3=655&page=3&s=58&click=0',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36',
'x-requested-with': 'XMLHttpRequest',
'Cookie':'qrsc=3; pinId=RAGa4xMoVrs; xtest=1210.cf6b6759; ipLocation=%u5E7F%u4E1C; _jrda=5; TrackID=1aUdbc9HHS2MdEzabuYEyED1iDJaLWwBAfGBfyIHJZCLWKfWaB_KHKIMX9Vj9_2wUakxuSLAO9AFtB2U0SsAD-mXIh5rIfuDiSHSNhZcsJvg; shshshfpa=17943c91-d534-104f-a035-6e1719740bb6-1525571955; shshshfpb=2f200f7c5265e4af999b95b20d90e6618559f7251020a80ea1aee61500; cn=0; 3AB9D23F7A4B3C9B=QFOFIDQSIC7TZDQ7U4RPNYNFQN7S26SFCQQGTC3YU5UZQJZUBNPEXMX7O3R7SIRBTTJ72AXC4S3IJ46ESBLTNHD37U; ipLoc-djd=19-1607-3638-3638.608841570; __jdu=930036140; user-key=31a7628c-a9b2-44b0-8147-f10a9e597d6f; areaId=19; __jdv=122270672|direct|-|none|-|1529893590075; PCSYCityID=25; mt_xid=V2_52007VwsQU1xaVVoaSClUA2YLEAdbWk5YSk9MQAA0BBZOVQ0ADwNLGlUAZwQXVQpaAlkvShhcDHsCFU5eXENaGkIZWg5nAyJQbVhiWR9BGlUNZwoWYl1dVF0%3D; __jdc=122270672; shshshfp=72ec41b59960ea9a26956307465948f6; rkv=V0700; __jda=122270672.930036140.-.1529979524.1529984840.85; __jdb=122270672.1.930036140|85.1529984840; shshshsID=f797fbad20f4e576e9c30d1c381ecbb1_1_1529984840145'
}
try:
r =requests.get(url,headers = head ,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def searchGoods(brand):
soup = BeautifulSoup(brand,'html.parser')
data1 = soup.find('ul',{"class":"J_valueList v-fixed"})
datali =data1.find_all('li')
Goods_href=[]
Goods_name=[]
for li in datali:
Goods_name.append(li.a.attrs['title'])
Goods_href.append(li.a.attrs['href'])
count = 0
for j in range(len(Goods_href)):
print("<<<{}.".format(count+1),"品牌 :"+Goods_name[j])
count = count+1
judge = 1
while(judge):
Goods_num = input("请输入品牌对应序号:")
if Goods_num.isdigit():
judge = 0
else:
print("您的输入有误,请输入数字:")
continue
a = int(Goods_num)
if a>count:
print("输入序号过大,请重新输入:")
judge = 1
elif a<1:
print("输入序号过小,请重新输入:")
judge = 1
print("选择的品牌是: "+Goods_name[int(Goods_num)-1])
brand_url = "https://search.jd.com/"+Goods_href[int(Goods_num)-1]
return brand_url
def orderBy(brand_url):
judge = 1
while(judge):
kind = input("按照:综合 / 销量 / 评论数 / 新品 / 价格 进行排序(默认综合)")
strinfo =re.compile('uc=0#J_searchWrap')#在对网页的url进行分析的时候发现
uc=0#J_searchWrap可以删减,如果点击不同的话对应的知识psort的值不同
if kind == '综合':
judge = 0
if kind == '销量':
b = strinfo.sub('psort=3',brand_url)
judge = 0
elif kind =='评论数':
b = strinfo.sub('psort=4',brand_url)
judge = 0
elif kind =='新品':
b = strinfo.sub('psort=5',brand_url)
judge = 0
elif kind =='价格':
b = strinfo.sub('psort=2',brand_url)
judge = 0
else :
print("输入有误,请重新输入:")
return b
def focus_good(new_brand_url):
head={'authority': 'search.jd.com',
'method': 'GET',
'path': '/s_new.php?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E6%89%8B%E6%9C%BA&cid2=653&cid3=655&page=4&s=84&scrolling=y&log_id=1529828108.22071&tpl=3_M&show_items=7651927,7367120,7056868,7419252,6001239,5934182,4554969,3893501,7421462,6577495,26480543553,7345757,4483120,6176077,6932795,7336429,5963066,5283387,25722468892,7425622,4768461',
'scheme': 'https',
'referer': 'https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E6%89%8B%E6%9C%BA&cid2=653&cid3=655&page=3&s=58&click=0',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36',
'x-requested-with': 'XMLHttpRequest',
'Cookie':'qrsc=3; pinId=RAGa4xMoVrs; xtest=1210.cf6b6759; ipLocation=%u5E7F%u4E1C; _jrda=5; TrackID=1aUdbc9HHS2MdEzabuYEyED1iDJaLWwBAfGBfyIHJZCLWKfWaB_KHKIMX9Vj9_2wUakxuSLAO9AFtB2U0SsAD-mXIh5rIfuDiSHSNhZcsJvg; shshshfpa=17943c91-d534-104f-a035-6e1719740bb6-1525571955; shshshfpb=2f200f7c5265e4af999b95b20d90e6618559f7251020a80ea1aee61500; cn=0; 3AB9D23F7A4B3C9B=QFOFIDQSIC7TZDQ7U4RPNYNFQN7S26SFCQQGTC3YU5UZQJZUBNPEXMX7O3R7SIRBTTJ72AXC4S3IJ46ESBLTNHD37U; ipLoc-djd=19-1607-3638-3638.608841570; __jdu=930036140; user-key=31a7628c-a9b2-44b0-8147-f10a9e597d6f; areaId=19; __jdv=122270672|direct|-|none|-|1529893590075; PCSYCityID=25; mt_xid=V2_52007VwsQU1xaVVoaSClUA2YLEAdbWk5YSk9MQAA0BBZOVQ0ADwNLGlUAZwQXVQpaAlkvShhcDHsCFU5eXENaGkIZWg5nAyJQbVhiWR9BGlUNZwoWYl1dVF0%3D; __jdc=122270672; shshshfp=72ec41b59960ea9a26956307465948f6; rkv=V0700; __jda=122270672.930036140.-.1529979524.1529984840.85; __jdb=122270672.1.930036140|85.1529984840; shshshsID=f797fbad20f4e576e9c30d1c381ecbb1_1_1529984840145'
}
r = requests.get(new_brand_url,headers = head)
r.encoding = 'utf-8'
html1 = etree.HTML(r.text)
datas = html1.xpath('//li[contains(@class,"gl-item")]')
count = 1
goods_href =[]
for data in datas:
p_price = data.xpath('div/div[@class="p-price"]/strong/i/text()')
# p_comment = data.xpath('div/div[5]/strong/a/text()')
p_name = data.xpath('div/div[@class="p-name p-name-type-2"]/a/em')
p_href = data.xpath('div/div[@class="p-name p-name-type-2"]/a/@href')
print(count,[p_name[0].xpath('string(.)'),p_price[0]])
goods_href.append(p_href)
count = count+1
judge = 1
while(judge):
focus_num = input("您关注的商品序号是:")
if focus_num.isdigit():
judge = 0
else:
print("您的输入有误,请输入数字:")
continue
a = int(focus_num)
if a>count-1:
print("输入序号过大,请重新输入:")
judge = 1
elif a<1:
print("输入序号过小,请重新输入:")
judge = 1
focus_good_url = goods_href[int(focus_num)-1]
# print(focus_good_url)
return focus_good_url
def open_Firefox(num):
location = 'D:/firefox-48.0b9.win64.sdk/firefox-sdk/bin/firefox.exe'
driver = webdriver.Firefox(firefox_binary=location)
driver.get(num)
focus_url = driver.current_url
focus_title = driver.title[:-16]
YesorNo3 = input("是否将此商品加入关注列表?(yes or no)")
if YesorNo3 == 'yes':
print("商品已成功加入关注列表")
with open('JD_goods.csv','a',newline="",encoding='utf-8') as f:
write1 = csv.writer(f)
write1.writerow([focus_title])
write1.writerow([focus_url])
write1.writerow(["---------------------------"])
if __name__=='__main__':
judge = 1
while(judge):
YesorNo = input("是否需要打开关注商品信息:(yes or no)")
if YesorNo == 'yes' or YesorNo == 'YES':
with open('JD_goods.csv','r',encoding='utf-8') as cv:
cv_read = cv.read()
print(cv_read)
judge = 0
elif YesorNo == 'no' or YesorNo == 'NO':
judge = 0
else:
print("输入有误,请重新输入:")
goods_name =input("请输入需要查询的商品种类:")
data = getHTMLText(goods_name)
YesorNo2 = input("是否需要根据商品品牌进行排列:(yes or no)")
if YesorNo2 == 'yes':
brand_url = searchGoods(data)
else :
brand_url = searchGoods(data)
new_brand_url = orderBy(brand_url)
focus_good_url = focus_good(new_brand_url)
str1 = str(focus_good_url)
new_url = "https:"+str1[2:-2]
# print(new_url)
open_Firefox(new_url)下面来说下整体代码思路吧和每个自定义的功能和自己做的小处理
自定义函数有:
-
getHTMLText
-
searchGoods
-
orderBy
-
focus_good
-
open_Firefox
-
思路
1.首先我们直接百度搜索JD.com就可以进入到京东商城的首页,然后我们在搜索框输入鞋子并敲击回车时候发现网页的url变成了
https://search.jd.com/Search?keyword=鞋子&enc=utf-8&pvid=4941906284aa4d49885aa15cb0df2d18
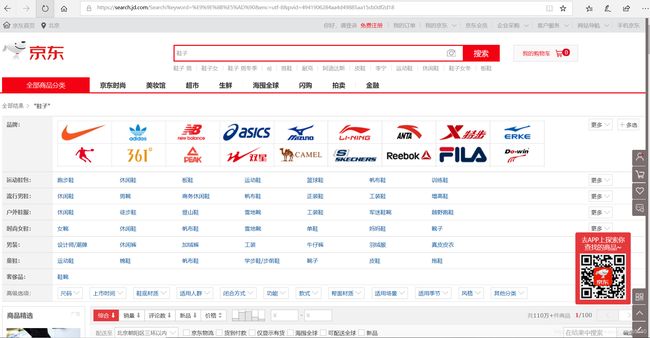
通过对url的分析发现有用的url就只有:https://search.jd.com/Search?keyword=鞋子&enc=utf-8
而keyword的值将决定你搜索的商品种类是什么,输入中文或者英文都可以简单的识别。所以我定义了第一个getHTMLText函数并在其中用字符串的拼接url = 'https://search.jd.com/Search?keyword=’+ goods+ '&enc=utf-8’来获得搜索商品种类的url
2.第二个函数(searchGoods)则是获取所有商品的品牌信息
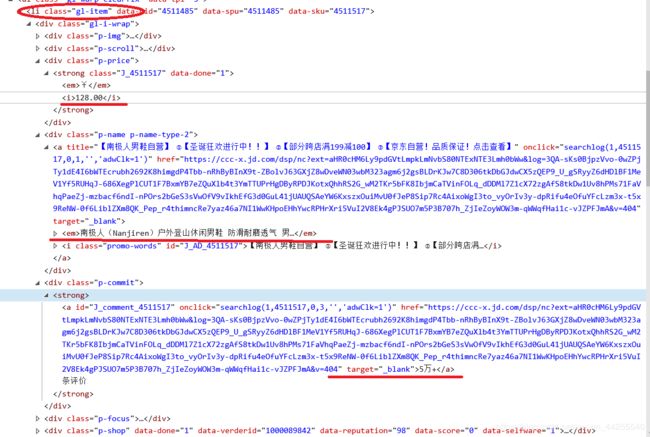
可以发现商品所有的信息都在一个class=gl-item中,然后用xpath定位到每个需要的内容。
这部分对应的另外一个函数是(focus_good)获取关注商品的信息,大部分功能与(searchGoods)类似,只是将关注商品的信息储存下来。
3.第三个函数是(orderBy),是将商品按照销量、评论或是价格等进行排列.最开始的时候没有发现url的规律,于是想用selenium模拟浏览器去点击按钮来实现,后来发现&psort=这个值可以控制排列顺序。比如当我选择鞋子并按照评论数 来排列的话,地址是‘https://search.jd.com/Search?keyword=鞋子&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&psort=4&click=0’ ,接着我们分析如果按综合页面的地址是‘https://search.jd.com/Search?keyword=鞋子&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&click=0’ ,可以发现前一个地址比后一个地址只多了psort=4,然后我们去掉了&click=0以后网页并没有变化,所以我想的是直接用字符串替换把&psort=X替换&click=0。结果是可以运行的,但是如果用selenium来启动的时候并不能跳转,结果发现是uc=0#J_searchWrap替代了&click=0的位置,于是在代码中直接将click改为uc=0#J_searchWrap再运行就没有问题了。
4.做到这一步的时候我们已经可以按照想要的品牌种类和排列顺序获取到一个网页了,接着我想如果用selenium启动的时候添加一个鼠标监听事件,比如我在这个网页上面点击一个商品的时候,我希望给我返回的是这个页面的信息。而selenium好像提供的鼠标事件只能模拟提前输入好的点击事件,并不能获取用户自主点击事件的信息。但是我在用python的鼠标点击事件的时候,pythoncom库一直报错,一直没有找到解决的办法,所以后面就放弃了这一步。改为了获取每个商品的信息,并编号,然后通过输入对应序号来直接启动Firefox打开这个商品的网页。然后我做了一个模拟关注商品的一个东西,通过csv来实现,这时你可以选择是否将该商品添加入关注列表。如果选择‘是’的话就将这个商品的信息通过with open('JD_goods.csv','a',newline="",encoding='utf-8') as f:来写入一个csv文件中,newline=“”是为了不让它写入一行就空一行,write1.writerow([focus_title])写入每一行的内容,writerow中的如果不将内容用【】括起来,csv中的内容会每个字符间都以逗号分隔。