一文理清楚,准确率,精度,召回率,真正率,假正率,ROC/AUC
一.混淆矩阵
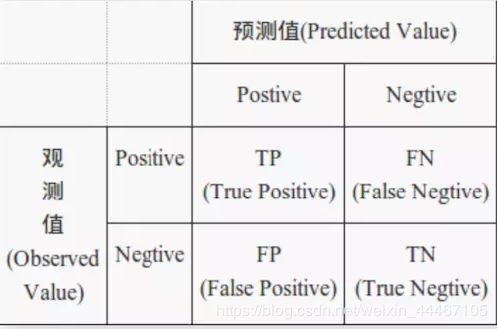
如上图为一个混淆矩阵,
True Positive (真正, TP)被模型预测为正的正样本;
True Negative(真负 , TN)被模型预测为负的负样本 ;
False Positive (假正, FP)被模型预测为正的负样本;
False Negative(假负 , FN)被模型预测为负的正样本;
相对应的,
True Positive Rate(真正率 , TPR)或灵敏度(sensitivity)
TPR = TP /(TP + FN)
正样本预测结果数 / 正样本实际数
True Negative Rate(真负率 , TNR)或特指度(specificity)
TNR = TN /(TN + FP)
负样本预测结果数 / 负样本实际数
False Positive Rate (假正率, FPR)
FPR = FP /(FP + TN)
被预测为正的负样本结果数 /负样本实际数
False Negative Rate(假负率 , FNR)
FNR = FN /(TP + FN)
被预测为负的正样本结果数 / 正样本实际数
二.其它的定义:
准确率:
预测对的样本占样本总数的比例
准确率 = 预测情况与真实情况一致的样本个数 / 样本总数
Accurancy = ( TP + TN ) / ( TP + TN + FP +FN )
精度p:
预测为正样本的里面有多少是真正的正样本
精度 = 预测为正的正样本个数 / 预测为正的样本个数 =TP/(TP+FP)
召回率r:
召回率 = 被预测为正的样本个数 /正样本个数=TP/(TP+FN)
召回率的值等于真正率
F1度量:
对于精度和召回率之间的平衡,我们取两者的调和平均作为F1度量,可以有效的同时考虑到精度和召回率两者。
F1=2/(1/r+1/p)
F1趋向于接近r和p中的较小数,因此一个高的F1度量值确保精度和召回率都比较高。
三.ROC/AUC
ROC中文名为接收者操作特征曲线,显示的是分类器真正率和假正率之间折中的一种图形化方法。在ROC曲线中,Y轴代表着真正率,X轴代表着假正率。
一个好的分类器应该更靠近图的左上角,而一个随机的分类器其曲线为点(0,0)和(0,1)的连线。
ROC曲线下方的面积AUC提供了评价模型平均性能的另一种方法,如果模型是完美的,则AUC=1,即曲线下方面积为1。如果模型是随机猜测的,则AUC=0.5.模型越好,其曲线下方面积应该越大。
产生ROC曲线:
如果大家对二值分类模型熟悉的话,都会知道其输出一般都是预测样本为正例的概率,而事实上,ROC曲线正是通过不断移动分类器的“阈值”来生成曲线上的一组关键点的。
一般输出样本为正例的概率,即输出值为0~1,我们把阈值从0-1之间调整,阈值每调整一次,每次取一个输出的概率,则可以得到一次对应的真正率和假正率,当所有的概率都取过之后,则得到完整的ROC曲线。
参考书籍:
《数据挖掘导论》由人民邮电出版社出版,[美]作者Pang-Ning Tan,Michael Steinbach,Vipin Kumar 合著