个人总结:机器学习与算法工程师方向面试题及答案(持续更新)
机器学习与算法工程师方向面试题及答案
- 1.快速排序
- 2.列表中是否有这个数——二分查找
- 3.拉格朗日对偶性
- 4.k-means原理及复杂度
- 5.逻辑回归和SVM区别
- 6.过拟合问题怎么解决
- 7.PCA降维
- 8.特征工程之特征选择、组合、提取、筛选
- 9.如何解决数据集数据不平衡问题
- 10.深度学习中常见分类模型
- 11.卷积是什么,卷积的原理,卷积核怎么设定
- 12.如何理解svm
- 13.池化的原理,Maxpooling、Averagepooling原理
- 14.dropout原理
- 15.什么是范数,泛函分析
- 16.什么是决策树
- 17.什么是集成学习
- 18.GAN模型
- 19.什么是张量
- 20.介绍一下Python的浅拷贝和深拷贝
- 21.常见目标检测的深度学习模型
- 22.什么是牛顿法
- 23.FFM和FM的区别
- 24.如何判断两个链表是否有交叉
- 25.逻辑回归推导
- 26.Linux 定时任务 执行sh文件
- 27.批量梯度下降与随机梯度下降
- 28.扔硬币,先扔先赢的概率
1.快速排序
/快速排序
void quick_sort(int s[], int l, int r)
{
if (l < r)
{
//Swap(s[l], s[(l + r) / 2]); //将中间的这个数和第一个数交换
int i = l, j = r, x = s[l];
while (i < j)
{
while(i < j && s[j] >= x) // 从右向左找第一个小于x的数
j--;
if(i < j)
s[i++] = s[j]; //先赋值后++
while(i < j && s[i] < x) // 从左向右找第一个大于等于x的数
i++;
if(i < j)
s[j--] = s[i]; //先赋值后--
}
s[i] = x;
//从s[i]划分两个子数组重复递归
quick_sort(s, l, i - 1); // 递归调用
quick_sort(s, i + 1, r);
}
}
来自:
https://www.runoob.com/w3cnote/quick-sort.html
2.列表中是否有这个数——二分查找
def seek(l, tag):
n = len(l)
if n == 1:
return False
count = n // 2
if l[count] == tag:
return True
if l[count] > tag:
return seek(l[:count], tag)
if l[count] < tag:
return seek(l[count:], tag)
来自:https://blog.csdn.net/nanyang1024/article/details/80043376
3.拉格朗日对偶性
某些条件下,把原始的约束问题通过拉格朗日函数转化为无约束问题,如果原始问题求解棘手,在满足KKT的条件下用求解对偶问题来代替求解原始问题,使得问题求解更加容易
来自:
https://www.cnblogs.com/90zeng/p/Lagrange_duality.html
4.k-means原理及复杂度
K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。
k-means算法特点在于:同一聚类的簇内的对象相似度较高;而不同聚类的簇内的对象相似度较小。
k-means 优缺点:
K-Means聚类算法的优点主要集中在:
(1)算法快速、简单;
(2)对大数据集有较高的效率并且是可伸缩性的;
(3)时间复杂度近于线性,而且适合挖掘大规模数据集。K-Means聚类算法的时间复杂度是O(n×k×t) ,其中n代表数据集中对象的数量,t代表着算法迭代的次数,k代表着簇的数目
k-means的缺点:
(1)在 K-means 算法中 K 是事先给定的,这个 K 值的选定是非常难以估计的。很多时候,事先并不知道给定的数据集应该分成多少个类别才最合适。
(2)在 K-means 算法中,首先需要根据初始聚类中心来确定一个初始划分,然后对初始划分进行优化。这个初始聚类中心的选择对聚类结果有较大的影响,一旦初始值选择的不好,可能无法得到有效的聚类结果,这也成为 K-means算法的一个主要问题。
(3)从 K-means 算法框架可以看出,该算法需要不断地进行样本分类调整,不断地计算调整后的新的聚类中心,因此当数据量非常大时,算法的时间开销是非常大的。所以需要对算法的时间复杂度进行分析、改进,提高算法应用范围。
来自:
https://blog.csdn.net/github_39261590/article/details/76910689
5.逻辑回归和SVM区别
5.1 LR和SVM有什么相同点
(1)都是监督分类算法,判别模型;
(2)LR和SVM都可以处理分类问题,且一般都用于处理线性二分类问题(在改进的情况下可以处理多分类问题);
(3)两个方法都可以增加不同的正则化项,如L1、L2等等。所以在很多实验中,两种算法的结果是很接近的。
5.2 LR和SVM有什么不同点
(1)本质上是其loss function不同;
(2)SVM只考虑分类面上的点,而LR考虑所有点(远离的点对边界线的确定也起作用);
(3)在解决非线性问题时,支持向量机采用核函数的机制,而LR通常不采用核函数的方法;
(4)SVM依赖于数据的测度,而LR则不受影响;
(5)SVM自带结构风险最小化,LR则是经验风险最小化;
(6)LR和SVM在实际应用的区别。
来自:
http://imgtec.eetrend.com/d6-imgtec/blog/2018-11/19119.html
6.过拟合问题怎么解决
一般提及到过拟合就是说在训练集上模型表现很好,但是在测试集上效果很差,即模型的泛化能力不行。过拟合是模型训练过程中参数拟合的问题,由于训练数据本身有采样误差,拟合模型参数时这些采样误差都拟合进去就会带来所谓的过拟合问题。
a.简化网络结构,如层数,单层神经元个数
b.early stopping,适当时间内就stopping训练,每个神经元激活函数在不同数值区间的性能是不同的,值较小时为线性区,适当增大后为非线性区,过度增大则为饱合区(梯度消失)。初始化时,神经元一般工作在线性区(拟合能力有限),训练时间增大时,部分值会增大进入非线性区(拟合能力提高),但是训练时间过大时,就会进入饱合区,神经元就“死掉”。所以应该在适当时间内就stopping训练。
c.限制权值,正则化
d.增加噪声:在输入中增加噪声(效果类似正则化);在权值中加入噪声(非零初始化);
来自:
https://blog.csdn.net/liubo187/article/details/77092729
7.PCA降维
PCA的原理就是将原来的样本数据投影到一个新的空间中,相当于我们在矩阵分析里面学习的将一组矩阵映射到另外的坐标系下。通过一个转换坐标,也可以理解成把一组坐标转换到另外一组坐标系下,但是在新的坐标系下,表示原来的原本不需要那么多的变量,只需要原来样本的最大的一个线性无关组的特征值对应的空间的坐标即可。
来自:
https://blog.csdn.net/wangzhiqing3/article/details/12193131
8.特征工程之特征选择、组合、提取、筛选

来自:
https://blog.csdn.net/lilu_leo/article/details/65935048?utm_source=blogxgwz5
9.如何解决数据集数据不平衡问题
(1)采样,分为上采样(小众重复)和下采样(大众部分),大小样本足够多时;
(2)数据合成,大小样本不足时;
(3)加权,设置合理的权重,实际应用中一般让各个分类间的加权损失值近似相等;
(4)一分类,看做一分类(One Class Learning)或异常检测(Novelty Detection)问题。
如何选择:
(1)在正负样本都非常之少的情况下,应该采用数据合成的方式;
(2)在负样本足够多,正样本非常之少且比例及其悬殊的情况下,应该考虑一分类方法;
(3)在正负样本都足够多且比例不是特别悬殊的情况下,应该考虑采样或者加权的方法。
(4)采样和加权在数学上是等价的,但实际应用中效果却有差别。尤其是采样了诸如Random Forest等分类方法,训练过程会对训练集进行随机采样。在这种情况下,如果计算资源允许上采样往往要比加权好一些。
(5)另外,虽然上采样和下采样都可以使数据集变得平衡,并且在数据足够多的情况下等价,但两者也是有区别的。实际应用中,我的经验是如果计算资源足够且小众类样本足够多的情况下使用上采样,否则使用下采样,因为上采样会增加训练集的大小进而增加训练时间,同时小的训练集非常容易产生过拟合。
(6)对于下采样,如果计算资源相对较多且有良好的并行环境,应该选择Ensemble方法。
来自:https://www.jianshu.com/p/be343414dd24
10.深度学习中常见分类模型
LeNet、AlexNet、VGG、GoogleNet、ResNet 是属于图像分类的CNN
(1)LeNet,1998,最早用于数字识别,输入图片为32321,卷积核大小为55,下采样步长为2,卷积时对原图像无填充; (2)AlexNet,2012,多层小卷积层叠加替换单层大卷积层,输入图片为227227*3,使用了约6千万个参数,AlexNet使用了ReLU激活函数,训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合,Alexnet有一个特殊的计算层,LRN层,做的事是对当前层的输出结果做平滑处理。
(2)AlexNet,2012,多层小卷积层叠加替换单层大卷积层,输入图片为227227*3,使用了约6千万个参数,AlexNet使用了ReLU激活函数,训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合,Alexnet有一个特殊的计算层,LRN层,做的事是对当前层的输出结果做平滑处理。
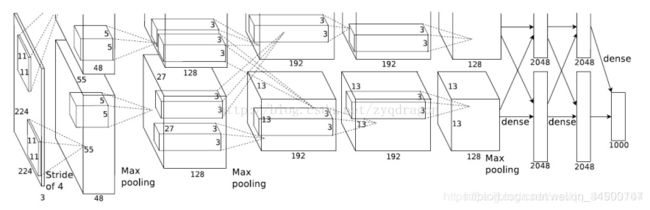
(3)VGGNet,2014,模型结构提升网络性能,用的参数更是多达1亿八千万个(当然其中主要是因为后两者使用了较大的FC层),图像转化学习问题上效果好。
为了减少信息的过度丢失,在加入Pool层减少feature maps size的同时同比例扩大它的channels数目。VGG网络达到一定深度后就陷入了性能饱和的困境,即网络越深,越容易出现梯度消失,导致模型训练难度变大,出现“退化”现象(退化:当模型的深度增加时,输出的错误率反而提高)。
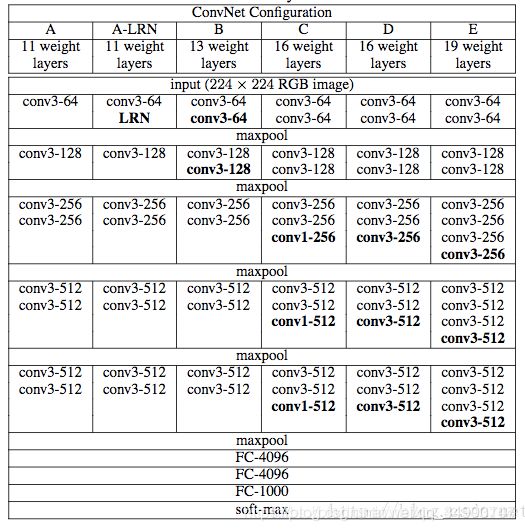
(4)GoogleNet,2014,残差网络和GoogleNet网络是解决网络深度增加的同时能使得模型的分类性能随着增加的网络,模型的默认输入尺寸时299x299,Google家的Inception系列模型提出的初衷主要为了解决CNN分类模型的两个问题,其一是如何使得网络深度增加的同时能使得模型的分类性能随着增加,而非像简单的VGG网络那样达到一定深度后就陷入了性能饱和的困境(Resnet针对的也是此一问题);其二则是如何在保证分类网络分类准确率提升或保持不降的同时使得模型的计算开销与内存开销充分地降低。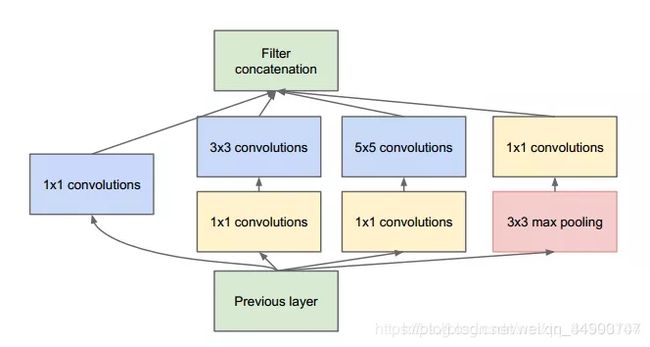
(5)ResNet,2015,残差网络,为了解决训练“退化”问题,残差模块在输入和输出之间建立了一个直接连接,这样新增的层仅仅需要在原来的输入层基础上学习新的特征,即学习残差,会比较容易。
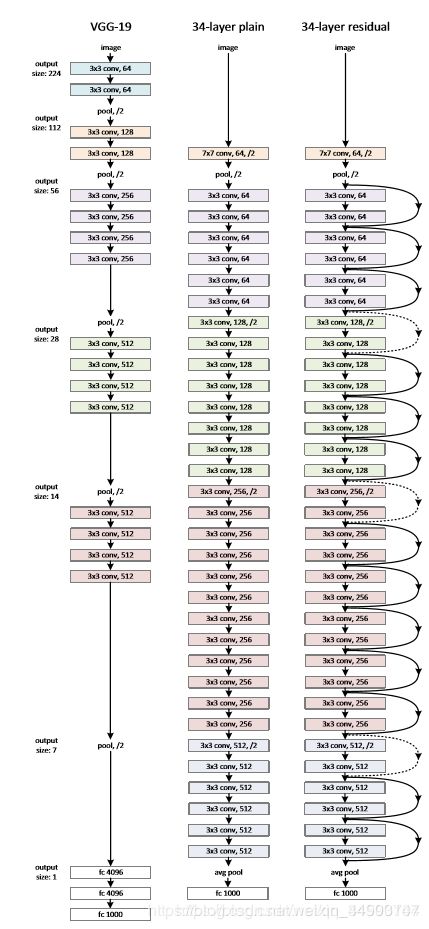
来自:
https://blog.csdn.net/qq_34590704/article/details/89601008
11.卷积是什么,卷积的原理,卷积核怎么设定
(1)卷积的定义及原理
简单定义:卷积是分析数学中一种重要的运算。
设:f(x),g(x)是R1上的两个可积函数,作积分:
![]()
可以证明,关于几乎所有的实数x,上述积分是存在的。这样,随着x的不同取值,这个积分就定义了一个新函数h(x),称为函数f与g的卷积,记为h(x)=(fg)(x)。
定义:
卷积是两个变量在某范围内相乘后求和的结果。如果卷积的变量是序列x(n)和h(n),则卷积的结果
![]()
其中星号表示卷积。当时序n=0时,序列h(-i)是h(i)的时序i取反的结果;时序取反使得h(i)以纵轴为中心翻转180度,所以这种相乘后求和的计算法称为卷积和,简称卷积。另外,n是使h(-i)位移的量,不同的n对应不同的卷积结果。
如果卷积的变量是函数x(t)和h(t),则卷积的计算变为
![]()
其中p是积分变量,积分也是求和,t是使函数h(-p)位移的量,星号*表示卷积。
来自:
https://baike.baidu.com/item/%E5%8D%B7%E7%A7%AF/9411006?fr=kg_qa
通俗理解卷积:https://www.matongxue.com/madocs/32.html
(2)卷积核的设定
在达到相同感受野的情况下,卷积核越小,所需要的参数和计算量越小。
具体来说。卷积核大小必须大于1才有提升感受野的作用,1排除了。而大小为偶数的卷积核即使对称地加padding也不能保证输入feature map尺寸和输出feature map尺寸不变(画个图算一下就可以发现),2排除了。所以一般都用3作为卷积核大小。
来自:
https://www.sohu.com/a/241208957_787107
12.如何理解svm
支持向量机(Support Vector Machine, SVM)是一类按监督学习(supervised learning)方式对数据进行二元分类的广义线性分类器(generalized linear classifier),也就是一种解决分类问题的线性可分性原理或方法
来自:
https://baike.baidu.com/item/%E6%94%AF%E6%8C%81%E5%90%91%E9%87%8F%E6%9C%BA/9683835?fromtitle=SVM&fromid=4385807&fr=aladdin
13.池化的原理,Maxpooling、Averagepooling原理
通过池化对特征进行提取并且缩小数据
下图是maxpooling 也就是最大池化,举例以一个22的卷积核,步长为2,来遍历整个矩阵,每经过一个22的区域就将这块区域中的最大值提取出来存放。具体如下图所示
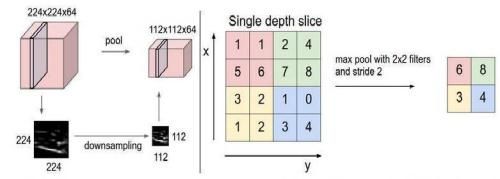
同理avgpooling也就是平均池化层就是将2*2的区域的所有值加起来取得均值存放。
来自:
https://www.cnblogs.com/DOMLX/p/9579108.html
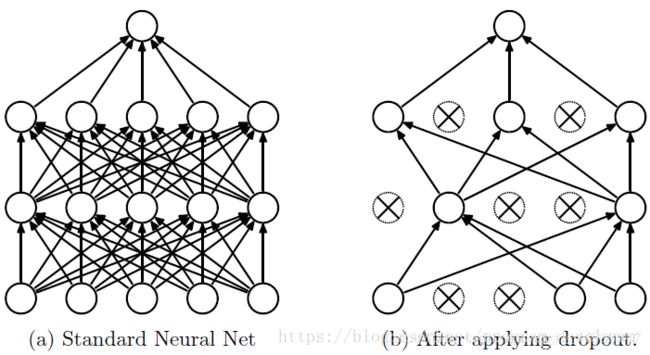
14.dropout原理
训练深度神经网络的时候,总是会遇到两大缺点:(1)容易过拟合;(2)费时。Dropout可以比较有效的缓解过拟合的发生,在一定程度上达到正则化(约束规范,使得模型有更好的泛化能力)的效果。
简单理解:神经元在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征,如下图所示
来自:
https://blog.csdn.net/program_developer/article/details/80737724
15.什么是范数,泛函分析
范数,是具有“长度”概念的函数。在线性代数、泛函分析及相关的数学领域,范数是一个函数,是矢量空间内的所有矢量赋予非零的正长度或大小。在泛函分析中,它定义在赋范线性空间中,并满足一定的条件,即①非负性;②齐次性;③三角不等式。它常常被用来度量某个向量空间(或矩阵)中的每个向量的长度或大小。
泛函分析(Functional Analysis)是现代数学的一个分支,隶属于分析学,其研究的主要对象是函数构成的空间。泛函分析是由对函数的变换(如傅立叶变换等)的性质的研究和对微分方程以及积分方程的研究发展而来的。使用泛函作为表述源自变分法,代表作用于函数的函数。它综合运用函数论,几何学,现代数学的观点来研究无限维向量空间上的泛函,算子和极限理论。它可以看作无限维向量空间的解析几何及数学分析。泛函分析在数学物理方程,概率论,计算数学等分科中都有应用,也是研究具有无限个自由度的物理系统的数学工具。
来自:
https://baike.baidu.com/item/%E8%8C%83%E6%95%B0/10856788
https://baike.baidu.com/item/%E6%B3%9B%E5%87%BD%E5%88%86%E6%9E%90/4151
16.什么是决策树
(decision tree) 是一种分类与回归方法,主要用于分类,决策树模型呈现树形结构,是基于输入特征对实例进行分类的模型。我认为决策树其实是定义在特征空间与类空间上的条件概率分布!
使用决策树算法的主要步骤又是什么呢? 可以分为三部分: 1特征的选取 2 决策树的生成 3 决策树的修剪
当前决策树的主要流行的三个算法是 ID3算法 C4.5算法和 CART算法(classification and regression tree)分类与回归树
来自:
https://blog.csdn.net/moxiaoxuan123/article/details/81411396
17.什么是集成学习
在机器学习的有监督学习算法中,我们的目标是学习出一个稳定的且在各个方面表现都较好的模型,但实际情况往往不这么理想,有时我们只能得到多个有偏好的模型(弱监督模型,在某些方面表现的比较好)。集成学习就是组合这里的多个弱监督模型以期得到一个更好更全面的强监督模型,集成学习潜在的思想是即便某一个弱分类器得到了错误的预测,其他的弱分类器也可以将错误纠正回来。
集成方法是将几种机器学习技术组合成一个预测模型的元算法,以达到减小方差(bagging)、偏差(boosting)或改进预测(stacking)的效果。
集成学习在各个规模的数据集上都有很好的策略。
数据集大:划分成多个小数据集,学习多个模型进行组合
数据集小:利用Bootstrap方法进行抽样,得到多个数据集,分别训练多个模型再进行组合
来自:
https://www.cnblogs.com/zongfa/p/9304353.html
18.GAN模型
Generative Adversarial Network,生成式对抗网络,模型通过学习一些数据,然后生成类似的数据。
GAN 有两个网络,一个是 generator,一个是 discriminator,从二人零和博弈中受启发,通过两个网络互相对抗来达到最好的生成效果。流程如下

19.什么是张量
张量概念是矢量概念的推广,矢量是一阶张量。张量是一个可用来表示在一些矢量、标量和其他张量之间的线性关系的多线性函数。
张量(Tensor)是一个定义在一些向量空间和一些对偶空间的笛卡儿积上的多重线性映射,其坐标是|n|维空间内,有|n|个分量的一种量, 其中每个分量都是坐标的函数, 而在坐标变换时,这些分量也依照某些规则作线性变换。
在同构的意义下,第零阶张量 (r = 0) 为标量 (Scalar),第一阶张量 (r = 1) 为向量 (Vector), 第二阶张量 (r = 2) 则成为矩阵 (Matrix)。
20.介绍一下Python的浅拷贝和深拷贝
浅拷贝,copy只拷贝原始对象,没有拷贝对象的子对象,如果子对象变化,拷贝后的对象也变化
深拷贝,deepcopy完全拷贝对象,包括其子对象,生成完全独立于原始对象的对象,子对象变化对深拷贝后的对象无影响。
可参考:
https://blog.csdn.net/zhubaoJay/article/details/90897028
21.常见目标检测的深度学习模型
目标检测常见算法主要分为两类:
One stage: SSD, YOLO V1, YOLO V2, YOLO V3; (精度较低,速度较快)
Two stage: Fast RCNN, Faster RCNN;(精度较高,速度较慢)
Multi stage:RCNN;(精度较低,速度极慢)
来自:
https://blog.csdn.net/u012797056/article/details/84895884
22.什么是牛顿法
牛顿迭代法(Newton’s method)又称为牛顿-拉夫逊(拉弗森)方法(Newton-Raphson method),它是牛顿在17世纪提出的一种在实数域和复数域上近似求解方程的方法。
来自:
https://baike.baidu.com/item/%E7%89%9B%E9%A1%BF%E8%BF%AD%E4%BB%A3%E6%B3%95/10887580?fromtitle=%E7%89%9B%E9%A1%BF%E6%B3%95&fromid=1384129&fr=aladdin
23.FFM和FM的区别
商用推荐场景中的CTR预估工作易面临大规模稀疏数据的挑战。因子分解机( Factorization Machine, 简称FM )模型的引入正对于此,其通过对参数矩阵的低秩分解,来解决高维训练的低效问题。这里,首先示例性地介绍数据稀疏和特征组合的相关内容,然后引出FM模型及其拓展形式FFM。
FFM模型在FM模型的基础上引入了场(field)的概念,即:具有相同性质或类型的特征属于同一个场。一般地,由同一个categorical特征经过One-hot编码所生成的特征都可被视为属于同一个field。
来自:
https://www.e-learn.cn/content/qita/780562
24.如何判断两个链表是否有交叉
应该分两种情况考虑,第一:这两个链表本身都没有环。 第二:这两个链表本身都有环,详情查看地址。
来自:
https://blog.csdn.net/seanyxie/article/details/6247071
25.逻辑回归推导
参考:
https://zhuanlan.zhihu.com/p/44591359
26.Linux 定时任务 执行sh文件
参考:
https://www.cnblogs.com/zhangwufei/p/8982224.html
27.批量梯度下降与随机梯度下降
批量梯度下降法是最原始的形式,它是指在每一次迭代时使用所有样本来进行梯度的更新。
随机梯度下降法不同于批量梯度下降,随机梯度下降是每次迭代使用一个样本来对参数进行更新。使得训练速度加快。
小批量梯度下降,是对批量梯度下降以及随机梯度下降的一个折中办法。其思想是:每次迭代 使用 ** batch_size** 个样本来对参数进行更新。
来自:
https://www.cnblogs.com/bnuvincent/p/11183206.html
28.扔硬币,先扔先赢的概率
参考:
https://blog.csdn.net/openfun/article/details/102777663