qemu rcu实现
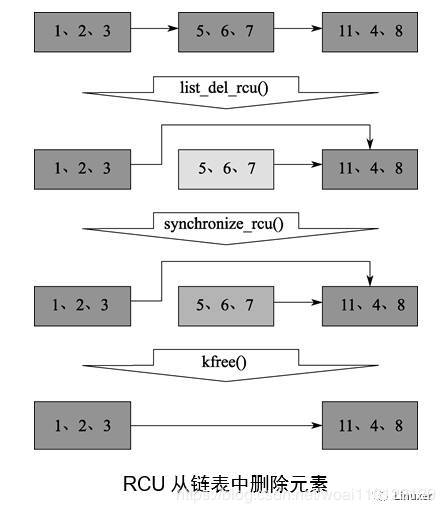
关于rcu的概念请参考谢宝友老师的深入理解RCU之三:概念
这里简单解释下,这里的例子为一个rcu从链表删除的例子, 在synchronize_rcu之前有一些读者会持有到5,6,7元素节点。synchronize_rcu之后保证没有读者持有5,6,7节点,所以可以进行对该节点释放。 这就是rcu要做的事情。在synchronize_rcu之前都可读者可能看到链表的不同副本,一种是从123,指向11,4,8, 一种是从567指向11,4,8。 对于第二种读者,我们不能在他们持有5,6,7的时候将5,6,7释放,所以synchronize_rcu就是等待这些读者读取完成,再进行节点释放(注意只需要等看得见5,6,7节点的读者完成)。
按照上面的情况我们举个例子
thread_reader1 {
rcu_read_lock();
{
遍历链表执行操作
}
rcu_read_unlock();
}
thread_reader2 {
rcu_read_lock();
{
遍历链表执行操作
}
rcu_read_unlock();
}
thread_writer {
reu_delete(rcu_list, node);
synchronize_rcu();
free(node);
}
另外rcu读者可以嵌套。
知道了用法和语义,我们来看看qemu的实现
这里先说明下qemu ruc设计的整体思路.
首先rcu有一个全局变量
unsigned long rcu_gp_ctr = 0;
当synchronize_rcu进入的时候更新该值,导致后面进入读临界区的rcu读端都会看到这个新值,而之前进入rcu读临界区的读者拿到的该值与新的新的rcu_gp_ctr值不同。
这样就可以区分新读者还是老读者。
在rcu宽限期内旧读者持有rcu保护的数据,所以我们需要等待旧读者都退出可以完成rcu写端的其余操作(比如释放从链表上摘取的节点)
另外当qemu的synchronize_rcu没有采用自悬的方式去等待,而是通过QemuEvent rcu_gp_event 变量休眠,当旧读者退出临界区的时候通知synchronize_rcu去检查状态,
当所有旧读者都退出临界区,synchronize_rcu返回.
rcu如何 同步rcu_gp_ctr状态?
struct rcu_reader_data {
/* Data used by both reader and synchronize_rcu() */
unsigned long ctr;
bool waiting;
/* Data used by reader only */
unsigned depth;
/* Data used for registry, protected by rcu_registry_lock */
QLIST_ENTRY(rcu_reader_data) node;
};
使用rcu_reader_data 来同步更新rcu_gp_ctr.
rcu_reader_data为threadlocal类型变量,
另外rcu有一个全局链表registry,所有rcu线程创建的时候都会将自己线程
的rcu_reader_data注册到registry链表上,这样其他线程也可以看到任何rcu线程的rcu_reader_data。
static ThreadList registry = QLIST_HEAD_INITIALIZER(registry);
在rcu线程初始化的时候
void rcu_register_thread(void)
{
assert(QEMU_THREAD_LOCAL_GET_PTR(rcu_reader)->ctr == 0);
qemu_mutex_lock(&rcu_registry_lock);
QLIST_INSERT_HEAD(®istry, QEMU_THREAD_LOCAL_GET_PTR(rcu_reader), node);
qemu_mutex_unlock(&rcu_registry_lock);
}
所以这里rcu_registry_lock就是保护registry链表的。
好了我们来看看rcu_read_lock的实现
static inline void rcu_read_lock(void)
{
struct rcu_reader_data *p_rcu_reader = QEMU_THREAD_LOCAL_GET_PTR(rcu_reader);
unsigned ctr;
if (p_rcu_reader->depth++ > 0) {
return;
}
ctr = atomic_read(&rcu_gp_ctr);
atomic_set(&p_rcu_reader->ctr, ctr);
/* Write p_rcu_reader->ctr before reading RCU-protected pointers. */
smp_mb_placeholder();
}
其实就是同步全局变量rcu_gp_ctr的值到thread local变量rcu_reader.ctr值,另外p_rcu_reader->depth用于实现rcu读者嵌套语义。 rcu_reader.ctr只有在rcu读者第一次进入的时候更新。 由于该函数为内联函数,为了防止编译器乱序和cpu乱序 添加一个内存屏障。
解锁过程如下
static inline void rcu_read_unlock(void)
{
struct rcu_reader_data *p_rcu_reader = QEMU_THREAD_LOCAL_GET_PTR(rcu_reader);
assert(p_rcu_reader->depth != 0);
if (--p_rcu_reader->depth > 0) {
return;
}
/* Ensure that the critical section is seen to precede the
* store to p_rcu_reader->ctr. Together with the following
* smp_mb_placeholder(), this ensures writes to p_rcu_reader->ctr
* are sequentially consistent.
*/
atomic_store_release(&p_rcu_reader->ctr, 0);
/* Write p_rcu_reader->ctr before reading p_rcu_reader->waiting. */
smp_mb_placeholder();
if (unlikely(atomic_read(&p_rcu_reader->waiting))) {
atomic_set(&p_rcu_reader->waiting, false);
qemu_event_set(&rcu_gp_event);
}
}
解锁代码就是把 thread local变量rcu_reader->ctr设置为0,表示已经退出读临界区。
如果rcu_reader->waiting为真为当前有rcu写者(synchronize_rcu)在等待该读者退出临界区,所以通过 qemu_event_set(&rcu_gp_event)通知写者(synchronize_rcu)有读者退出,使写者(synchronize_rcu)唤醒,后面我们会看到rcu写者((synchronize_rcu))在waiting上睡眠的情况。
另外 smp_mb_placeholder()这个内存屏障用于保证设置rcu_reader->ctr为0在读取rcu_reader->waiting之前完成,这是防止写者锁死,后面分析synchronize_rcu我们会看到原因。
void synchronize_rcu(void)
{
qemu_mutex_lock(&rcu_sync_lock);
/* Write RCU-protected pointers before reading p_rcu_reader->ctr.
* Pairs with smp_mb_placeholder() in rcu_read_lock().
*/
smp_mb_global();
qemu_mutex_lock(&rcu_registry_lock);
if (!QLIST_EMPTY(®istry)) {
/* In either case, the atomic_mb_set below blocks stores that free
* old RCU-protected pointers.
*/
if (sizeof(rcu_gp_ctr) < 8) {
/* For architectures with 32-bit longs, a two-subphases algorithm
* ensures we do not encounter overflow bugs.
*
* Switch parity: 0 -> 1, 1 -> 0.
*/
atomic_mb_set(&rcu_gp_ctr, rcu_gp_ctr ^ RCU_GP_CTR);
wait_for_readers();
atomic_mb_set(&rcu_gp_ctr, rcu_gp_ctr ^ RCU_GP_CTR);
} else {
/* Increment current grace period. */
atomic_mb_set(&rcu_gp_ctr, rcu_gp_ctr + RCU_GP_CTR);
}
wait_for_readers();
}
qemu_mutex_unlock(&rcu_registry_lock);
qemu_mutex_unlock(&rcu_sync_lock);
}
这里主要是更新rcu_gp_ctr值, 然后调wait_for_readers()函数等待旧的读者完成.
rcu_sync_lock 用于防止多个写者进入 synchronize_rcu
另外在32位处理器和64位采用不同方式更新rcu_gp_ctr。
static void wait_for_readers(void)
{
ThreadList qsreaders = QLIST_HEAD_INITIALIZER(qsreaders);
struct rcu_reader_data *index, *tmp;
for (;;) {
/* We want to be notified of changes made to rcu_gp_ongoing
* while we walk the list.
*/
qemu_event_reset(&rcu_gp_event);
/* Instead of using atomic_mb_set for index->waiting, and
* atomic_mb_read for index->ctr, memory barriers are placed
* manually since writes to different threads are independent.
* qemu_event_reset has acquire semantics, so no memory barrier
* is needed here.
*/
QLIST_FOREACH(index, ®istry, node) {
atomic_set(&index->waiting, true);
}
/* Here, order the stores to index->waiting before the loads of
* index->ctr. Pairs with smp_mb_placeholder() in rcu_read_unlock(),
* ensuring that the loads of index->ctr are sequentially consistent.
*/
smp_mb_global();
QLIST_FOREACH_SAFE(index, ®istry, node, tmp) {
if (!rcu_gp_ongoing(&index->ctr)) {
QLIST_REMOVE(index, node);
QLIST_INSERT_HEAD(&qsreaders, index, node);
/* No need for mb_set here, worst of all we
* get some extra futex wakeups.
*/
atomic_set(&index->waiting, false);
}
}
if (QLIST_EMPTY(®istry)) {
break;
}
/* Wait for one thread to report a quiescent state and try again.
* Release rcu_registry_lock, so rcu_(un)register_thread() doesn't
* wait too much time.
*
* rcu_register_thread() may add nodes to ®istry; it will not
* wake up synchronize_rcu, but that is okay because at least another
* thread must exit its RCU read-side critical section before
* synchronize_rcu is done. The next iteration of the loop will
* move the new thread's rcu_reader from ®istry to &qsreaders,
* because rcu_gp_ongoing() will return false.
*
* rcu_unregister_thread() may remove nodes from &qsreaders instead
* of ®istry if it runs during qemu_event_wait. That's okay;
* the node then will not be added back to ®istry by QLIST_SWAP
* below. The invariant is that the node is part of one list when
* rcu_registry_lock is released.
*/
qemu_mutex_unlock(&rcu_registry_lock);
qemu_event_wait(&rcu_gp_event);
qemu_mutex_lock(&rcu_registry_lock);
}
/* put back the reader list in the registry */
QLIST_SWAP(®istry, &qsreaders, node);
}
static inline int rcu_gp_ongoing(unsigned long *ctr)
{
unsigned long v;
v = atomic_read(ctr);
return v && (v != rcu_gp_ctr);
}
smp_mb_global()是为了让其他线程看到rcu_gp_event的值,这样新进入的读者就不被认为是新读者
wait_for_readers中rcu_gp_ongoing函数用于区分是否为旧读者
rcu_gp_ongoing中判断rcu线程的rcu_reader->ctr有三种情况
- 值为0 表示该线程不在rcu读者临界区内
- 与rcu_gp_ctr相同表示为一个新读者
- 是一个rcu_gp_ctr旧值,表示为一个旧的读者
这里对于1,2情况我们的synchronize_rcu都不需要等待, 所以把他们从registry链表取走, 放入qsreaders 链表, 如果registry为空,
表示所有旧读者都已经执行完成, 则synchronize_rcu结束
否则的话把每个旧的读者的rcu_reader->waiting 变量都设置为真.则该读者在退出rcu临界区的时候需要通知synchronize_rcu线程,因为synchronize_rcu线程在
rcu_gp_event上面.
所以要保证
读者线程设置rcu_reader->ctr=0要在 读取rcu_reader->waiting之前完成
写者线程要先读取读者线程的rcu_reader->ctr再设置rcu_reader->waiting
如果不这样可能导致rcu_sync永久休眠。
最后qemu的rcu不像内核中的rcu,qemu中的rcu在读者临界区会发生休眠(这在用户空间是不可避免的,内核采用禁止抢占而不被调度出去)。所以qemu的rcu性能远不及内核中的rcu.
所以qemu中的synchronize_rcu只在一个线程中调用,这就是call_rcu_thread,
另外读者有没有注意到rcu_read_lock()和rcu_read_unlock并没有任何参数,也就是说这是一个全局锁,对于内核中旧读者最多为cpu个数-1个,并且读者不允许休眠和调度,所以很快就会结束, 而在qemu中这是不现实的,所以qemu退化成只在一个线程中调用synchronize_rcu.
qemu的rcu提供的两个api
#define call_rcu(head, func, field) \
call_rcu1(({ \
char __attribute__((unused)) \
offset_must_be_zero[-offsetof(typeof(*(head)), field)], \
func_type_invalid = (func) - (void (*)(typeof(head)))(func); \
&(head)->field; \
}), \
(RCUCBFunc *)(func))
#define g_free_rcu(obj, field) \
call_rcu1(({ \
char __attribute__((unused)) \
offset_must_be_zero[-offsetof(typeof(*(obj)), field)]; \
&(obj)->field; \
}), \
(RCUCBFunc *)g_free);