虚拟机CentOS 7.5.1804下无外网Hadoop HA集群安装
网上有很多Hadoop HA集群安装的资料,我当时安装也是参考了官方文档和这些资料才安装成功的。由于使用的环境和软件版本可能有所不同,且因工作环境网络所限无法连接外网,加之记录一下自己的安装过程,不枉花费时间来研究Hadoop环境的搭建,故作此文章。
一、集群架构表
| IP地址 |
主机名 |
角色 |
端口 |
| 192.168.52.2 |
namenode |
NameNode,JournalNode,ZKFC, ResourceManager,MapReduce历史服务器 |
hdfs-site(http://namenode:50070) yarn-site(http://namenode:8088) |
| 192.168.52.3 |
datanode1 |
NameNode,JournalNode,ZKFC,DataNode,ZooKepper |
hdfs-site(http://datanode1:50070) |
| 192.168.52.4 |
datanode2 |
ResourceManager,JournalNode,DataNode,ZooKepper |
yarn-site(http://namenode:8088) |
| 192.168.52.5 |
datanode3 |
DataNode,ZooKepper |
注:ZKFC只依赖Zookeeper的机制,并不依赖本地ZooKeeper是否安装 ,所以无须在namenode上安装ZooKeeper。
之所以这么布局也是因为安装时候无意间发现这个情况,本来我是想让4台机器都作为Zookeeper服务器节点的。
二、操作系统环境及软件版本(都是当时的最新版本)
我安装的是1台虚拟机,克隆了3个,具体安装过程在此不加赘述。
1、CentOS 7.5.1804 ,最小化安装
2、Hadoop 2.9.2
3、JDK8(最开始装的JDK11,屡试不行,去官网查版本支持,发现不支持JAVA 11,于是下的JDK8)
4、ZooKeeper-3.4.13
5、ntpdate或者CentOS 7默认的chrony时间同步,二选一
6、psmisc(很重要,fuser指令所需的包,后面会详细说明)
cat /etc/redhat-release![]()
hadoop -version
java -version
alternatives --config java (配置java多版本环境)
yum install psmisc
三、安装过程
1、配置主机名
1.1 分别在4台服务器上用root账户执行:
hostnamectl set-hostname namenode
hostnamectl set-hostname datanode1
hostnamectl set-hostname datanode2
hostnamectl set-hostname datanode31.2 在4台服务器上用root用户执行(亦可在namenode上修改,然后scp复制到其他主机上):
vi /etc/hosts然后在文本末尾插入如下4行信息
192.168.52.2 namenode
192.168.52.3 datanode1
192.168.52.4 datanode2
192.168.52.5 datanode3
192.168.52.1 win #这行最好也加上,方便本机windows与4台虚拟机的相互访问
2、关闭SELINUX
因为CentOS的所有访问权限都是有SELinux来管理的,为了简化安装过程避免权限导致的问题,先将其关闭,以后根据需要再进行重新管理。
执行如下指令关闭:
setenforce 0 #临时设置SELINUX状态
vi /etc/selinux/config # 编辑 config 文件将 SELINUX=enforcing 修改为 SELINUX=disabled(重启生效)查看执行结果:
getenforce #查看当前SELINUX状态,permissive或disabled代表SELINUX处于关闭状态
3、关闭防火墙
同样是为了简化安装,避免防火墙策略带来的影响。
先查看防火墙状态:
[hadoop@namenode hadoop]$ systemctl status firewalld
● firewalld.service - firewalld - dynamic firewall daemon Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled) #disabled表示非开机启动
Active: inactive (dead) #inactive表示当前未激活,active表示已激活
Docs: man:firewalld(1)4、新建hadoop账户
由于Hadoop 集群中的各节点默认会使用当前的账号SSH免密码登录其它节点,所以需要在每个节点中创建一个相同的供 Hadoop 集群专用的账户,本例中使用的账户为 hadoop 。
useradd hadoop #创建账户 passwd hadoop #设置密码
5、配置ssh互信(root、hadoop)
5.1 开启 sshd 秘钥认证
编辑每一台服务器的 /etc/ssh/sshd_config 文件,去掉下面这3行前的 “#” 注释。
执行:
vi /etc/ssh/sshd_config删除行首"#",取消注释:
# RSAAuthentication yes
# PubkeyAuthentication yes
# AuthorizedKeysFile .ssh/authorized_keys然后重启sshd服务:
systemctl restart sshd
5.2 配置root账户的ssh互信
5.2.1 生成公钥和私钥
在4台服务器上执行,一直按回车默认即可:
ssh-keygen -t rsa执行完后会在hadoop用户的家目录(/home/hadoop)中生成一个.ssh文件夹,里面有两个文件,其中id_rsa是私钥,id_rsa.pub是公钥。
在namenode服务器上以下执行:
5.2.2 将4台服务器公钥文件的内容追加输入到authorized_keys文件
(1) 先将namenode的公钥内容插入到authorized_keys文件
cat /home/root/.ssh/id_rsa.pub >> /home/root/.ssh/authorized_keys(2) 通过ssh输入密码再将三台datanode的公钥内容插入到authorized_keys文件
ssh hadoop@datanode1 cat /home/root/.ssh/id_rsa.pub >> /home/root/.ssh/authorized_keys
ssh hadoop@datanode2 cat /home/root/.ssh/id_rsa.pub >> /home/root/.ssh/authorized_keys
ssh hadoop@datanode3 cat /home/root/.ssh/id_rsa.pub >> /home/root/.ssh/authorized_keys5.2.3 ssh连接namenode自己,以在/home/root/.ssh/known_hosts生成自己的那条记录
ssh hadoop cat /home/root/.ssh/id_rsa.pub >> /home/root/.ssh/authorized_keys5.2.4 将authorized_keys和known_hosts通过scp复制到三台datanode服务器上
scp /home/root/.ssh/authorized_keys datanode1:/home/root/.ssh/
scp /home/root/.ssh/authorized_keys datanode2:/home/root/.ssh/
scp /home/root/.ssh/authorized_keys datanode3:/home/root/.ssh/
scp /home/root/.ssh/known_hosts datanode1:/home/root/.ssh/
scp /home/root/.ssh/known_hosts datanode2:/home/root/.ssh/
scp /home/root/.ssh/known_hosts datanode3:/home/root/.ssh/5.2.5 修改ssh目录和authorized_keys的权限
chmod -R 700 /home/root/.ssh chmod 600 /home/root/.ssh/authorized_keys5.2.6 测试一下,不需要输入密码就能登录则成功,注意下命令行中的主机名哦
ssh root@datanode1 ssh root@datanode2 ssh root@datanode35.3 同理,配置hadoop账户的ssh互信
用hadoopz账户登录,生成公、私钥:
ssh-keygen -t rsa其他步骤按照5.2的顺序来,只要把root替换成hadoop就可以了。
6、 用root用户给hadoop用户授予sudo权限
执行如下指令:
visudo在文末添加如下内容,目的是为了授予hadoop用户组所有权限,可使用sudo指令执行一些只有root用户才能执行的指令。
%hadoop ALL=(ALL) ALL7、安装JDK
从下面网站下载Oracle JDK8的tar.gz包,第一个网站可以下载8u202版本,第二个可以下载8u192版本,Oracle官方说了2019年1月以后将不支持Java 8的公开版更新。
http://jdk.java.net/8/
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
ftp、rz或通过虚拟机共享文件夹上传到服务器,找到安装包所在目录,解压安装即可,
tar -zxf java8.tar.gz -C 要解压到的文件路径 #想要看安装过程输出信息的可以加个v参数,即-zxvf8、配置时间同步,避免服务器间时间不一致带来的影响
注意:ntp配置后,要延迟一阵才开始时间同步,所以用ntpstat -p指令查看是否配置成功时,不要以为输出的结果不对就是没配置正确,最好等一段时间再看。
9、安装ZooKeeper
这个也没什么说的,下载,解压,配置。在ZooKeeper服务器比如datanode1上安装配置好后,然后scp整个ZooKeeper目录即可。
下载地址:
https://www.apache.org/dyn/closer.cgi/zookeeper/
到ZooKeeper服务器上,解压指令:
tar -zxf zookeeper.tar.gz -C 要解压到的文件路径配置:
到ZooKeeper的安装目录下的conf子目录下新建zoo.cfg:
cp zoo_sample.cfg zoo.cfg配置zoo.cfg:
vi zoo.cfg把原来的dataDir那行注释掉,新加如下两行:
dataDir=/hadoop/software/zookeeper-3.4.13/data
dataLogDir=/hadoop/software/zookeeper-3.4.13/logs
server.1=datanode1:2888:3888
server.2=datanode2:2888:3888
server.3=datanode3:2888:3888新建两个目录——data目录和logs目录,对应zoo.cfg中的配置,并在data目录下新建myid文件,内容对应zoo.cfg中的server单词后的数字,如果是复制的文件别忘了改哦!
![]()
至此ZooKeeper就配好了,是不是很简单?别忘了启动Zookeeper!
在datanode1、datanode2、datanode3三台Zookeeper服务器上启动Zookeeper Server.
zkServer.sh start10、安装、配置Hadoop
安装hadoop难点无非就是配置问题,在遇到问题时确保配置正确,结合log文件查找原因。
注意:下面所有指令都是以hadoop用户登录执行的:
10.1 安装Hadoop
下载地址:
http://hadoop.apache.org/
下载好tar.gz包,解压(建议不要下source源码版本的,需要各种包和docker包,很烦),注意四台服务器上都要安装哦!
tar -zxf hadoop.tar.gz -C hadoop的安装目录10.2 配置hadoop的环境变量和全局环境变量
可以分别配置/etc/profile和/home/hadoop/.bash_profile,这样权限方面更安全一点,但我嫌麻烦,索性都配到/etc/profile里了。
vi /etc/profile在文末加入如下内容:
# Configure JAVA
export JAVA_HOME=/software/jdk1.8.0_202
export JAVA_BIN=$JAVA_HOME/bin
export JAVA_LIB=$JAVA_HOME/lib
export CLASSPATH=.:$JAVA_LIB/tools.jar:$JAVA_LIB/dt.jar
# Configure Hadoop
export HADOOP_HOME=/hadoop/hadoop-2.9.2
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
# Configure Zookeeper
export ZOOKEEPER_HOME=/hadoop/software/zookeeper-3.4.13
# Configure PATH export PATH=$PATH:$HOME/.local/bin:$HOME/bin:$JAVA_BIN:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin进入到配置文件所在目录:
cd /hadoop/hadoop-2.9.2/etc/hadoop10.3 在配置hdfs时用到的配置文件是hadoop-env.sh、core-site.xml和hdfs-site.xml,具体配置如下:
10.3.1 配置hadoop-env.sh
将其中的export JAVA_HOME行替换为JAVA_HOME的绝对路径:
export JAVA_HOME=/software/jdk1.8.0_202根据自己的实际环境配置。注意,我开始觉得没必要修改,因为JAVA_HOME全局变量已经在/etc/profile中声明了,且测试shell脚本echo出的变量值也对,运行Hadoop却报错,看样必须要设置成绝对路径。
10.3.2 配置core-site.xml,在
fs.defaultFS
hdfs://mycluster
io.file.buffer.size
131072
hadoop.tmp.dir
file:/hadoop/hadoop-2.9.2/tmp_ha
ha.zookeeper.quorum
namenode:2181,datanode1:2181
10.3.3 配置hdfs-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.ha.automatic-failover.enabled
true
yarn.resourcemanager.cluster-id
rmCluster
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
namenode
yarn.resourcemanager.hostname.rm2
datanode2
yarn.resourcemanager.zk-address
datanode1:2181,datanode2:2181,datanode3:2181
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
至此,hdfs HA就配置完了。
10.4 在配置yarn ResourceManager时用到的配置文件是yarn-env.sh、yarn-site.xml
10.4.1 配置yarn-env.sh
将其中的export JAVA_HOME行替换为JAVA_HOME的绝对路径:
export JAVA_HOME=/software/jdk1.8.0_202 10.4.2 配置yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.ha.automatic-failover.enabled
true
yarn.resourcemanager.cluster-id
rmCluster
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
namenode
yarn.resourcemanager.hostname.rm2
datanode2
yarn.resourcemanager.zk-address
datanode1:2181,datanode2:2181,datanode3:2181
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
至此,yarn HA就配置完了。
10.5 复制配置到其他3台服务器
10.5.1 为了省事,可以先配好一台服务器,比如namenode,然后再用scp指令复制hadoop配置文件到其他机器上。
在其余三台服务器上分别用hadoop用户执行:
scp -r namenode:/hadoop/hadoop-2.9.2/etc/hadoop /hadoop/hadoop-2.9.2/etc/hadoop也可以反过来,只在namenode服务器上执行:
scp -r /hadoop/hadoop-2.9.2/etc/hadoop datanode1:/hadoop/hadoop-2.9.2/etc/hadoop
scp -r /hadoop/hadoop-2.9.2/etc/hadoop datanode1:/hadoop/hadoop-2.9.2/etc/hadoop
scp -r /hadoop/hadoop-2.9.2/etc/hadoop datanode1:/hadoop/hadoop-2.9.2/etc/hadoop 10.5.2 建议依据服务器在集群中的角色做个性化配置
如果只是安装个Hadoop HA集群玩玩,可以按10.5.1那么做;可如果想深入了解Hadoop的配置参数,建议结合官方文档,对不同角色的服务器做个性化配置,少配一些不必要的参数。
11、启动Hadoop HA集群
(1)(仅安装好后第一次启动时,)在任意ZooKeeper节点上执行:
hdfs zkfc -formatZK(2)启动ZKFC (ZookeeperFailoverController是用来监控NameNode状态,协助实现主备NameNode切换的,所以仅仅在主备NameNode节点上启动就行)
在namenode、datanode1上分别执行:
hadoop-daemon.sh start zkfc用jps指令查看执行结果:
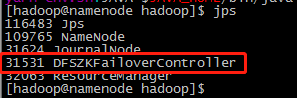
(3)启动用于主备NameNode之间同步元数据信息的共享存储系统JournalNode。在集群中各个节点上执行。
两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JournalNodes中的变更信息,并且一直监控Edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了。
按如上所说,只在NameNode上启动JournalNode即可,可是JournalNode机制有额外的限制,需要N-1/2个节点且至少有3个节点,因此必须要在其他服务器上加一个JournalNode节点。
分别在namenode、datanode1、datanode2三台JournalNode服务器上执行:
hadoop-daemon.sh start journalnode用jps指令查看执行结果:
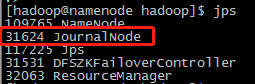
(4)(仅安装好后第一次启动时,)格式化并启动主NameNode
在namenode上执行:
hdfs namenode -format启动NameNode
hadoop-daemon.sh start namenode用jps指令查看执行结果:

(5)(仅安装好后第一次启动时,)在备NameNode上同步主NameNode的元数据信息
在datanode1上执行:
hdfs namenode -bootstrapStandby如果安装过程中出现问题,多次执行会有报错,需要关掉服务或杀死进程,清空报错提示的目录。
(6)启动备NameNode
在datanode1上执行:
hadoop-daemon.sh start namenode用jps指令查看执行结果:

(7)主NameNode上启动DataNode
在namenode上,启动所有datanode
hadoop-daemons.sh start datanode所有节点启动完成后,验证主备切换。
在浏览器中打开
http://namenode:50070/dfshealth.html#tab-overview
http://datanode1:50070/dfshealth.html#tab-overview
查看状态


然后,在主NameNode(主机名namenode)上执行:
ps -ef|grep namenode-namenode #正常只要ps -ef|grep namenode即可,因为我的主机名也叫namenode,所以需要改动一下
找到进程号后,
kill -9 刚刚找到的进程号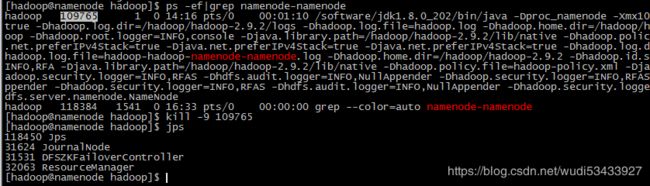
然后查看
http://datanode1:50070/dfshealth.html#tab-overview
无需查看namenode的网页,想也知道进程被杀了根本打不开。
发现datanode1的状态由standby变为active,则验证成功。

最后,不放心的话可以在namenode上启动NameNode。可以看到,状态由active变为standby。
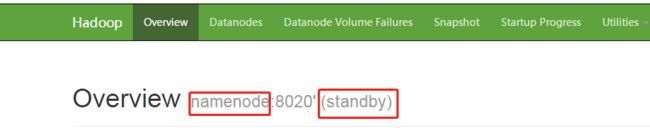
至此,hdfs HA就验证完了。
注:
1)这里也可以用hdfs haadmin指令查看NameNode状态
hdfs haadmin -getServiceState nn2 #nn1、nn2为上面定义的NameNode节点名
hdfs haadmin -getServiceState nn1 #报错正常,因为进程被kill了,还没启动
2)在验证时也可以通过hdfs haadmin指令来进行主备切换,但这样并不能验证HA主备切换真的配置成功了。我最开始配置错误,这样操作仍然可以验证成功,可kill进程就无法验证成功了,证明配置存在问题。
hdfs haadmin -failover nn1 nn2(8)在主ResourceManager(namenode)、备(datanode2)上启动Yarn
yarn-daemon.sh start resourcemanager打开
http://namenode:8088/cluster/cluster
http://datanode2:8088/cluster/cluster
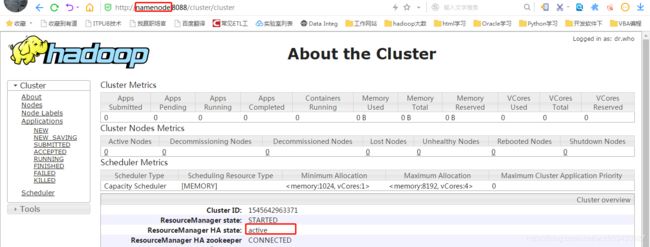

关掉resourcemanager服务,或者kill掉该进程后,验证主备切换。
yarn-daemon.sh stop resourcemanager
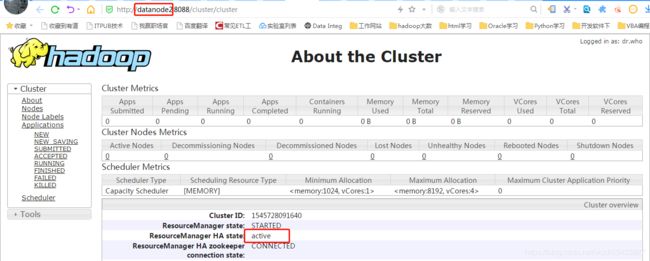
此时,主ResourceManager网页无法访问。再次在namenode上启动ResourceManager服务:
yarn-daemon.sh start resourcemanager可以看到

至此,Yarn HA就验证完了。
今后启动Hadoop集群只需要两步:
<1>先启动Zookeeper服务器
zkServer.sh start<2>再启动Hadoop
start-all.sh12、遇到的问题
(1)好多年没关注Linux版本变更了,只是偶尔用到一些常用指令,在安装CentOS 7时,发现好多指令都不能用了,比如SysV服务变成了systemd服务,导致chkconfig、service指令某些功能不能用了,系统建议用原生的systemctl指令。不禁感慨现在知识迭代太快了。
(2)因为工作地点网络环境所限,需要做额外工作。刚开始想配reposever连到阿里云或者教育网作为yum源,屡试不行,应该是杀毒软件和网络策略限制了,网络不通。我记得以前直接用iso文件作为yum源就行,我4台服务器,只需要一台做yum源,其他3台用它当yum源,于是就按这个思路配置yum源。这样,整个集群就是纯内网Hadoop集群了。
(3)在配置ntp同步时,我打算用namenode作为集群ntp服务器,其他三台datanode同步其时间,而namenode的时间由本机windows同步过去。其实可以用VMware Workstation自带的时间同步。可我就是想试试windows ntp服务,于是又研究了一下,安装了个njinx和ntp,最终实现同步。
但在验证时验证过早,总以为配置有问题,因为几年前装过ntp服务,大致知道怎么配,可怎么也找不到哪儿配置错了。最后偶然发现ntpstat -p居然同步了,证明配置没问题,搜了下资料才发现ntp第一次同步会有一定的延迟。
(4)在配置hdfs HA时,将ssh验证那块的私钥当成公钥了,以为是ssh互信呢,给改成authorized_keys了,后来看log才找到原因。
(5)改完ssh后,发现kill进程主备切换还是失败,查看log和hadoop java源码才发现调用的是fuser指令,而CentOS 7最小化安装默认是不安装fuser对应的软件包的。于是:
yum install psmisc安装好后,再次验证,果然成功了!你说这有多坑吧,所以建议想省心的还是完整安装操作系统吧,省着少这包那包的。
总结,架构整体挺简单,但因涉及到的方面比较多,再加上环境原因,导致在配yum源、ntp时间同步和验证hdfs HA时多花了些时间。在hadoop配置方面,多看看官方文档,挺简单的,但也不能尽信之,因为这个文档好像很久没更新了,连支持的jdk都是7,听说java是3个版本一个大版本,所以jdk 6、7、8应该差异不大。