1. 写在前面
前面相继写了Python数据分析快速入门系列之Numpy快速入门, Pandas快速入门, 为什么我们需要快速入门, 这其实这其实涉及到学习方式的问题(在人工智能时代,如何快速学习一项技能?),今天是快速入门第三篇爬虫快速入门, 这是第一次学习Python爬虫,虽然不知道后面能不能用的到,但是还是学学吧,万一以后能用到呢? 至少知道点爬虫的原理啥的,借助这个偶然的机会吧,就用了一天的时间学习了一下,希望通过今天,可以做到Python的基本入门。并且把今天的成果记录一下。
下面分为几个方面展开:
- Python爬虫的基本知识(包括什么是网络爬虫,爬虫能干什么, 网络爬虫的定义)
- 开发爬虫的步骤
- 了解XPath定位, JSON对象解析
- 如何使用lxml库,进行XPath的提取
- 如何在Python中使用Selenium库来帮助你模拟浏览器,获取完整的HTML
- 最后做几个实战小程序脚本
2. Python爬虫的基本知识:
- 什么是网络爬虫: 简单的说,爬虫就是一段程序或者说一个脚本
- 爬虫能干什么: 自动的批量采集我们需要的资源
所以总结一下网络爬虫的的定义: 网络爬虫是一段脚本或者一个程序,这个程序或者脚本能够模拟浏览器自动的浏览网页, 自动的批量的采集我们需要的资源
3. 开发爬虫的流程:
- 目标数据(网站地址, 页面)
- 分析数据加载流程(重点)
先看一下下面这个图,把握一下请求,响应等内部的逻辑。

首先是给出目标数据所在的url, 然后浏览器根据url向相应的服务器发出请求, 服务器做出响应把结果返回给浏览器,浏览器做出解析,得到数据返回给用户。
(如果自己写爬虫的爬虫的话,解析这一块也需要自己来写,因为服务器返回给浏览器的是网页源码,我们得想办法取出我们想要的数据,然后进行下载。)
- 下载数据
- 清洗,处理数据
- 数据持久化(写入文件)
上面这就是开发爬虫的一个基本流程, 第二步最重要,上面只是列出了逻辑,下面还有一些具体的细节
- 比如我们发出请求的时候我们有两种方式post和get方式, 使用的Python中的requests包访问的页面。
- 再比如,服务器返回给浏览器的数据是HTML页面或者是JSON数据,如果是JSON数据,就需要我们通过json包解析成Python
- 那么如果是HTML页面的话,我们如何提取到我们想要的数据呢,这时候需要定位,XPath定位可以帮助我们定位位置,而只有位置还不行,得提取相应的标签,这时候还会用到一个Python解析库lxml进行解析数据,这样才能找到我们目标数据,第二种方式就是直接可以使用正则表达式直接匹配提取目标数据。
- 还有一个问题就是如果我们用Requests获取HTML之后,发现想要的XPath并不存在,因为可能HTML还没有加载完,因此这时候还需要一个工具进行网页的加载模拟,直到加载完整个HTML,这个工具就是Python的Selenium库。
上面这些都是可能会遇到的问题,所以下面会一一先进行具体细节的简要介绍,然后通过几个实战简单的看看。
3.1 Requests 访问页面
Requests 是 Python HTTP 的客户端库,编写爬虫的时候都会用到,编写起来也很简单。它有两种访问方式:Get 和 Post。这两者最直观的区别就是:Get 把参数包含在 url 中,而 Post 通过 request body 来传递参数。
假设我们想访问豆瓣
r = requests.get(‘http://www.douban.com’)
这里的“r”就是 Get 请求后的访问结果,然后我们可以使用 r.text 或 r.content 来获取 HTML 的正文。
r = requests.post(‘http://www.douban.com’, data={‘key’:‘value’})
这里 data 就是传递的表单参数,data 的数据类型是个字典的结构,采用 key 和 value 的方式进行存储。
3.2 XPath定位
XPath 是 XML 的路径语言,实际上是通过元素和属性进行导航,帮我们定位位置。它有几种常用的路径表达方式。下面是写简单的例子:
- xpath(‘node’) 选取了 node 节点的所有子节点;
- xpath(’/div’) 从根节点上选取 div 节点;
- xpath(’//div’) 选取所有的 div 节点;
- xpath(’./div’) 选取当前节点下的 div 节点;
- xpath(’…’) 回到上一个节点;
- xpath(’//@id’) 选取所有的 id 属性;
- xpath(’//book[@id]’) 选取所有拥有名为 id 的属性的 book 元素;
- xpath(’//book[@id=“abc”]’) 选取所有 book 元素,且这些 book 元素拥有 id= "abc"的属性;
- xpath(’//book/title | //book/price’) 选取 book 元素的所有 title 和 price 元素。
使用 XPath 定位,你会用到 Python 的一个解析库 lxml。这个库的解析效率非常高,使用起来也很简便,只需要调用 HTML 解析命令即可,然后再对 HTML 进行 XPath 函数的调用。
"""比如我们想要定位到 HTML 中的所有列表项目,可以采用下面这段代码。"""
from lxml import etree
html = etree.HTML(html)
result = html.xpath('//li')
3.3 JSON对象解析
JSON 是一种轻量级的交互方式,在 Python 中有 JSON 库,可以让我们将 Python 对象和 JSON 对象进行转换
import json
jsondata = '{"a":1, "b":2, "c":3, "d":4, "e":5}';
input = json.loads(jsondata)
print(input)
4. 小项目实战
下面给出几个小项目的实战,能够快速上手Python爬虫, 项目和介绍如下:
- 如何使用JSON数据自动下载王祖贤的海报(这里面会用到JSON数据的解析)
- 如何使用XPath自动下载王祖贤的海报(这里应用XPath和lxml等)
- 使用Python去爬取一部小说(这里会用到正则表达式)
- 使用爬虫去爬取一个表格数据(这里会用到bs4)
4.1 如何使用JSON数据自动下载王祖贤的海报
需求: 假设我想去豆瓣自动下载王祖贤的海报,我们先梳理一下日常操作的步骤,毕竟爬虫也是模拟我们的浏览:
- 打开网页
- 输入关键词“王祖贤”
- 在搜索结果中选择图片
- 下载图片
- 保存到文件中
针对上面的五部, 我们来看看爬虫应该怎么写才能进行上面的模拟:
- 我们先锁定目标数据: 王祖贤的图片
- 有了数据,我们得有一个统一资源定位符:url,也就是我们要访问服务器的哪? 即先给出url(这里你需要注意的是,如果爬取的页面是动态页面,就需要关注 XHR 数据。因为动态页面的原理就是通过原生的 XHR 数据对象发出 HTTP 请求,得到服务器返回的数据后,再进行处理),这里的url直接是: (https://www.douban.com/j/search_photo?q= 王祖贤 &limit=20&start=0) 这是个XHR数据请求
- 通过requests发出请求,得到响应,并解析这个响应得到HTML页面(这里我们获取到的是JSON格式的对象,因为是通过原生的XHR数据对象发出的HTTP请求),JSON数据长下面这样:

从这个 JSON 对象中,我们能看到,王祖贤的图片一共有 22471 张,其中一次只返回了 20 张,还有更多的数据可以请求。数据被放到了 images 对象里,它是个数组的结构,每个数组的元素是个字典的类型,分别告诉了 src、author、url、id、title、width 和 height 字段,这些字段代表的含义分别是原图片的地址、作者、发布地址、图片 ID、标题、图片宽度、图片高度等信息。
有了JSON信息,就可以很容易的把图片下载下来了。
- 下载数据,并保存文件
下面根据上面的描述进行操作
"""导入包"""
import requests
import json
"""下载图片函数"""
def downloadpic(src, id):
"""
src -- 图片的位置
id -- 表示图片的序号, 为图片命名使用
"""
downloadpath = './webspider/posters/'
if not os.path.exists(downloadpath):
os.mkdir(downloadpath)
dir = downloadpath + str(id) + '.jpg'
try:
pic = requests.get(src, timeout=10)
fp = open(dir, 'wb')
fp.write(pic.content)
fp.close()
except requests.exceptions.ConnectionError:
print('图片无法下载')
"""基于JSON对象自动下载明星图片的Python爬虫"""
def photowebspider(photonums=10, query='王祖贤'):
"""
photonums -- 需要的图片数量
query -- 表示明星名
"""
headers = {
'Cookie':'OCSSID=4df0bjva6j7ejussu8al3eqo03',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
' (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
for i in range(0, 22471, 20):
url = 'https://www.douban.com/j/search_photo?q= %s &limit=20&start= %s' %(query, str(i))
html = requests.get(url, headers=headers).text
response = json.loads(html, encoding='utf-8')
for image in response['images']:
print(image['src'])
downloadpic(image['src'], image['id'])
photonums -= 1
if photonums == 0:
return
"""测试爬虫"""
photowebspider(20, '胡歌')
4.2 如何使用XPath自动下载王祖贤的海报(这里应用XPath和lxml等)
如果你遇到 JSON 的数据格式,那么恭喜你,数据结构很清爽,通过 Python 的 JSON 库就可以解析。但有时候,网页会用 JS 请求数据,那么只有 JS 都加载完之后,我们才能获取完整的 HTML 文件。XPath 可以不受加载的限制,帮我们定位想要的元素。
比如,我们想从豆瓣电影上下载王祖贤的电影封面, 同样的先梳理人工操作流程
- 打开网页movie.douban.com
- 输入关键词 “王祖贤”
- 下载图片页中的所有电影封面
同样,针对上面的步骤,梳理一下应该通过XPath和lxml进行下载图片
- 编写下载图片的函数, 这个函数负责给定地址之后,下载一张图片存入文件
- 关于海报爬虫函数的编写思路:
- 给定资源所在网页的网址url
- 通过Selenium库中的WebDriver来模拟浏览器的访问, 获取到完整的HTML(注意:这里需要安装响应浏览器的WebDriver,我安装的谷歌的,具体安装方法见最后的那个链接)
- 然后对HTML中的XPath地址进行提取, 得到海报的真实地址和电影的名称
- 然后调用下载函数进行下载
注意: 需要自己先去目标数据所在的地方调用XPathHelper插件谷歌浏览器插件xpath helper 的安装和使用 进行海报和电影名称XPath的获取, 下面开始实践:
"""导入包"""
import os
import requests
from lxml import etree
from selenium import webdriver
"""编写下载单张海报的函数"""
def downloadposter(src, id):
"""
src -- 图片的地址
id -- 图片的标题
"""
downloadpath = './webspider/posters/'
if not os.path.exists(downloadpath):
os.mkdir(downloadpath)
dir = downloadpath + str(id) + '.webp'
try:
pic = requests.get(src, timeout=30)
fp = open(dir, 'wb')
fp.write(pic.content)
fp.close()
except requests.exceptions.ConnectionError:
print("图片无法下载")
"""下载海报函数"""
def posterwebspider(postersnums=10, query='王祖贤'):
"""
postersnums -- 海报数
query -- 人
"""
for i in range(0, 150, 15):
url = 'https://search.douban.com/movie/subject_search?search_text= %s &cat=1002&start=%s' %(query, str(i))
driver = webdriver.Chrome('C:/Users/ZhongqiangWu/AppData/Local/Google/Chrome/Application/chromedriver')
driver.get(url)
html = etree.HTML(driver.page_source)
src_xpath = "//div[@class='item-root']/a[@class='cover-link']/img[@class='cover']/@src"
title_xpath = "//div[@class='item-root']/div[@class='detail']/div[@class='title']/a[@class='title-text']"
srcs = html.xpath(src_xpath)
titles = html.xpath(title_xpath)
for src, title in zip(srcs, titles):
print('\t'.join([str(src), str(title.text)]))
downloadposter(src, title.text)
postersnums -= 1
if postersnums == 0:
return
"""测试爬虫"""
posterwebspider(20, '宫崎骏')
4.3 使用Python去爬取一部小说(这里会用到正则表达式)
比如,我想去一个小说网站利用Python自动下载一部小说,应该怎么办呢?
- 建立一个url,也就是目标小说所在的网页
- 使用request.get().text获取到相应的HTML
- 从这个HTML上面获取到响应的章节链接(这里使用正则表达式匹配)
- 根据每一个链接,去下载小说内容
- 把小说的内容存入.txt文件
"""导入包"""
import re
import os
import requests
"""下载每一章的函数"""
def downloadnovel(title, chapter_url, chapter_title):
"""
title -- 小说名
chapter_url -- 每一章的地址
chapter_titlehar -- 每一章的名字
"""
filename = './webspider/'+ '%s.txt' %(title)
fp = open(filename, 'a')
chapter_request = requests.get(chapter_url)
chapter_request.encoding = 'gbk'
chapter_html = chapter_request.text
chapter_content = re.findall(r'(.*?)
'
, chapter_html
, re
.S
)[0]
chapter_content
= chapter_content
.replace
(' ', '')
chapter_content
= chapter_content
.replace
('
', '')
chapter_content
= chapter_content
.replace
('\n', '')
chapter_content
= "".join
([s
for s
in chapter_content
.splitlines
(True) if s
.strip
()])
fp
.write
(chapter_title
)
fp
.write
('\n')
fp
.write
(chapter_content
)
fp
.write
('\n\n')
"""下载小说爬虫"""
def novelwebspider(chapternum
):
headers
= {
'Cookie':'OCSSID=4df0bjva6j7ejussu8al3eqo03',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
' (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
url
= "http://www.zzjdkj.cn/book/0/944/"
response
= requests
.get
(url
, headers
=headers
)
"""
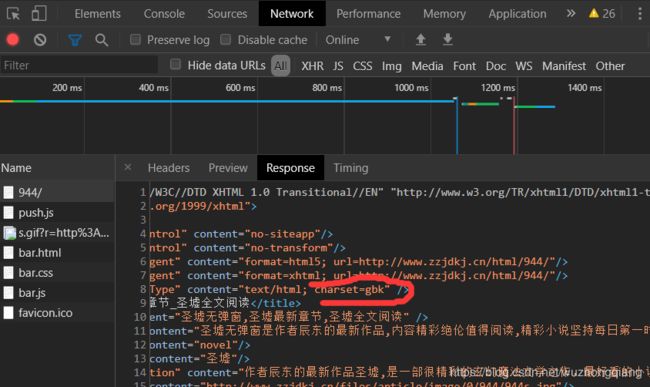
这里的编码先说一个问题,首先,先输出一下编码方式,如果这里的编码方式使用的ISO-8859-1, 直接转成utf-8依然会出现乱码
此时,应该用开发者工具去查看原网页的HTML页面中的heard里面的编码。这个网页采用的gbk。
不会查看? F12->network->刷新-> 点开第一个 -> 看head部分的编码
"""
response
.encoding
= 'gbk'
html
= response
.text
dl
= re
.findall
(r
'.*?
', html
, re
.S
)[0]
chapter_info_list
= re
.findall
(r
'href="(.*?)">(.*?)<', dl
)
title
= re
.findall
(r
'', html
)[0]
downloadpath
= './webspider/'
if not os
.path
.exists
(downloadpath
):
os
.mkdir
(downloadpath
)
dir = downloadpath
+ '%s.txt' %(title
)
fp
= open(dir, 'w', encoding
='gbk')
for chapter_info
in chapter_info_list
:
chapter_url
, chapter_title
= chapter_info
chapter_url
= 'http://www.zzjdkj.cn/book/0/944/%s' %chapter_url
print(chapter_url
, chapter_title
)
downloadnovel
(title
, chapter_url
, chapter_title
)
chapternum
-= 1
if chapternum
== 0:
return
"""测试爬虫"""
chapternum
= input('您需要下载个多少章节的内容: ')
novelwebspider
(int(chapternum
))
看看编码的查看方式:
4.4 使用爬虫去爬取一个表格数据(这里用到bs4)
去https://baike.so.com/doc/24368318-25185095.html 网站去爬取中国百强城市排行榜名单, 简单分析一下步骤
- 根据网址获取网页
- 根据返回的网页想办法提取出表格(上面用了JSON,XPath,正则,看看表格应该用啥能提取出来:bs4)
爬虫—bs4语法
"""导入包"""
import requests
import bs4
from bs4 import BeautifulSoup
import pandas as pd
url = 'https://baike.so.com/doc/24368318-25185095.html '
headers = {
'Cookie':'OCSSID=4df0bjva6j7ejussu8al3eqo03',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
'(KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
response = requests.get(url, headers=headers)
response.encoding = response.apparent_encoding
html = response.text
data =[]
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
data.append([tds[0].string, tds[1].string, tds[2].string])
new_data = pd.DataFrame(data[1:], columns=['排名', '城市', '综合分值'])
new_data
5. 总结
花费了一天的时间进行Python爬虫的基本入门, 了解了XPath定位, JSON对象解析如何使用lxml库,进行XPath的提取
如何在Python中使用Selenium库来帮助你模拟浏览器,获取完整的HTML等知识, 并且学会了正则表达式的皮毛和bs4的皮毛, 下面在整个过程中参考的博客
- Python使用xpath爬取数据返回空列表解决方案积累
- 爬虫—bs4语法
- Python 去除字符串中的空行
- Python+requests 爬取网站遇到中文乱码怎么办?
- Python 用 ChromeDriver 实现登录和签到
- 学会Python正则表达式,就看这20个例子