【集体智慧编程】第三章、发现群组
一、前言
本章中,我们将学习到如下内容:从各种不同的来源中构造算法所需的数据;两种不同的聚类算法;更多有关距离度量(distance metrics)的知识;简单的图形可视化代码,用以观察所生成的群组;最后,我们还会学习如何将异常复杂的数据集投影到二维空间中。
聚类时常被用于数据量很大(data-intensive)的应用中。跟踪消费者购买行为的零售商们,除了利用常规的消费者统计消息外,还可以利用这些信息自动检测出具有相似购买模式的消费者群体。年龄和收入都相仿的人也许会有迥然不同的着装风格,但是通过使用聚类算法,我们就可以找到“时装岛屿”,并据此开发出相应的零售或市场策略。聚类在计量生物学领域里也有大量的运用,我们用它来寻找具有相似行为的基因组,相应的研究结果可以表明,这些基因组中的基因会以同样的方式响应外界的活动,或者表明它们是相同生化通路中的一部分。
二、监督学习和无监督学习
(1)监督学习
利用样本输入和期望输出来学习如何预测的技术被称为监督学习法(supervised learning methods)。常用的监督学习法包括:神经网络、决策树、向量支持机以及贝叶斯过滤。采用这些方法的应用程序,会通过检查一组输入和期望的输出来进行“学习”。当我们想要利用这些方法中的任何一种来提取信息时,我们可以传入一组输入,然后期望应用程序能够根据其此前学到的知识来产生一个输出。
(2)无监督学习
聚类是无监督学习(unsupervised learning)的一个例子。与神经网络或决策树不同,无监督学习算法不是利用带有正确答案的样本数据进行“训练”。它们的目的是要在一组数据中找寻某种结构,而这些数据本身并不是我们要找的答案。在前面提到的时装的例子中,聚类的结果不会告诉零售商每一位顾客可能会买什么,也不会预测新来的顾客适合哪种时尚。聚类算法的目标是采集数据,然后从中找出不同的群组。其他无监督学习的例子还包括非负矩阵因式分解(non-negative matrix factorization)和自组织映射(self-organizing maps)。
三、对订阅源中的单词进行计数
几乎所有的博客都可以在线阅读,或者通过RSS订阅源进行阅读。RSS订阅源是一个包含博客及其所有文章条目信息的简单的XML文档。为了给每个博客中的单词计数,首先第一步就是要解析这些订阅源。所幸的是,有一个非常不错的程序能够完成这项工作,它就是Universal Feed Parser。从python的包或者使用pip安装feedparser包即可。
有了Universal Feed Parser,我们就可以很轻松地从任何RSS或Atom订阅源中得到标题、链接和文章的条目了。下一步,我们来编写一个从订阅源中提取所有单词的函数。新建一个feedvector.py,将下列代码加入。
import feedparser
import re
# 返回一个RSS订阅源的标题和包含单词计数情况的字典
def getwordcounts(url):
# 解析订阅源
d = feedparser.parse(url)
wc = {}
# 循环遍历所有的文章条目
for e in d.entries:
if 'summary' in e:
summary = e.summary
else:
summary = e.description
# 提取一个单词列表
words = getwords(e.title+''+summary)
for word in words:
wc.setdefault(word, 0)
wc[word] += 1
return d.feed.title, wc每个RSS和Atom订阅源都会包含一个标题和一组文章条目。通常,每个文章条目都有一段摘要,或者是包含了条目中实际文本的描述性标签。函数getwordcounts将摘要传给函数getwords,后者会将其中所有的HTML标记剥离掉,并以非字母字符作为分隔符拆分出单词,再将给过以列表的形式加以返回。
def getwords(html):
# 去除所有HTML标记
txt = re.compile(r'<[^>]+>').sub('', html)
# 利用所有非字母字符拆分出单词
words = re.compile(r'[^A-Z^a-z]+').split(txt)
# 转化成小写形式
return [word.lower() for word in words if word != '']为了开始下一步工作,我们现在需要一个订阅源的列表。这里我手动将一些博客的RSS订阅地址放在了一个叫feedlist.txt 的文件中,每一行对应一个URL。如果我们拥有自己的博客,或者有一些博客是我们特别喜欢的,同时很想看看它们和某些热门博客的对比情况如何,那么我们也可以将这些博客的URL加入到文件中。

将下列代码加入到feedvector.py 文件的末尾
apcount = {}
wordcounts = {}
feedlist=[line for line in file('feedlist.txt')]
for feedurl in feedlist:
title, wc = getwordcounts(feedurl)
wordcounts[title] = wc
for word, count in wc.items():
apcount.setdefault(word, 0)
if count>1:
apcount[word] += 1下一步,我们来建立一个单词列表,将其实际用于针对每个博客的单词计数。因为像“the”这样的单词几乎到处都是,而像“film-flam”这样的单词则有可能只出现在个别博客中,所以通过只选择介于某个百分比范围内的单词,我们可以减少需要考查的单词总量。在本例中,我们可以将10%定为下届,将50%定为上界,不过加入你发现有过多常见或鲜见的单词出现,不妨尝试一下不同的边界值。
wordlist = []
for w,bc in apcount.items():
frac = float(bc)/len(feedlist)
if frac > 0.1 and frac < 0.5:
wordlist.append(w)最后,我们利用上述单词列表和博客列表来建立一个文本文件,其中包含一个大的矩阵,记录着针对每个博客的所有单词的统计情况:
out = file('blogdata.txt', 'w')
out.write('Blog')
for word in wordlist:
out.write('\t%s' % word)
out.write('\n')
for blog, wc in wordcounts.items():
out.write(blog)
for word in wordlist:
if word in wc:
out.write('\t%d' % wc[word])
else:
out.write('\t0')
out.write('\n')这一过程最终将会生成一个名为blogdata.txt 的输出文件。如下所示:

验证一下,是否包含一个以制表符分割的表格,其中的每一列对应一个单词,每一行对应一个博客。本章中出现的函数都将统一采用这一文件格式,日后我们还可以据此来构造新的数据集,我们甚至还可以将一个电子表格另存为如此格式的文本文件,并沿用本章中的算法对其实施聚类。
四、分级聚类
分级聚类通过连续不断地将最为相似的群组两两合并,来构造出一个群组的层级结构。其中的每个群组都是从单一元素开始的,在本章的例子中,这个单一元素就是博客。在每次迭代的过程中,分级聚类算法会计算每两个群组间的距离,并将距离最近的两个群组合并成一个新的群组。这一过程会一直重复下去,直到只剩一个群组为止。如下图所示:

在上图中,元素的相似程度是通过它们的相对位置来体现的---两个元素距离越近,它们就越相似。开始时,群组还只有一个元素。在第二步中,我们可以看到A和B,这两个紧靠在一起的元素,已经合并成了一个新的群组,新群组所在的位置位于这两个元素的中间。在第三步中,新群组又与C进行了合并。因为D和E现在是距离最近的两个元素,所以它们共同构成了一个新的群组。最后一步将剩下的两个群组合并到了一起。
通常,待分级聚类完成之后,我们可以采用一种图形化的方式来展现所得的结果,这种图被称为树状图,图中显示了按层级排列的节点。上述例子中的树状图如下图所示:

树状图是分级聚类的一种可视化形式
树状图不仅可以利用连线来表达每个聚类的构成情况,而且还可以利用距离来体现构成聚类的各元素间相隔的远近。在图中,聚类AB与A和B之间的距离要比聚类DE与D和E之间的距离更加接近。这种图形绘制方式能够帮助我们有效地确定一个聚类中各元素间的相似程度,并以此来指示聚类的紧密程度。
本节我们将示范如何对博客数据集进行聚类,以构造博客的层级结构;如果构造成功,我们将实现将主题对博客进行分组。首先,我们需要一个方法来加载数据文件。请新建一个名为clusters.py的文件,将下列函数加入其中:
def readfile(filename):
lines = [line for line in file(filename)]
# 第一行是列标题
colnames = lines[0].strip().split('\t')[1:]
rownames = []
data = []
for line in lines[1:]:
p = line.strip().split('\t')
# 每行的第一列是行名
rownames.append(p[0])
# 剩余部分就是该行对应的数据
data.append([float(x) for x in p[1:]])
return rownames, colnames, data上述函数将数据集中的头一行数据读入了一个代表列名的列表,并将最左边一列读入了一个代表行名的列表,最后它又将剩下的所有数据都放入了一个大列表,其中的每一项对应于数据集中的一行数据。数据集中任一单元格内的计数值,都可以由一个行号和列号来唯一定位,此行号和列号同时还对应于列表rownames和colnames中的索引。
下一步我们来定义紧密度。我们曾在第二章讨论过这个问题,那一章中我们以欧几里德距离和皮尔逊相关度为例对两位影评者的相似程度进行了评论。在本章的例子中,一些博客比其他博客包含更多的文章条目,或者文章条目的长度比其他博客的更长,这样会导致这些博客在总体上比其他博客包含更多的词汇。皮尔逊相关度可以纠正这一问题,因为它判断的其实是两组数据与某条直线的拟合程度。此处,皮尔逊相关度的计算代码将接受两个数字列表作为参数,并返回这两个列表的相关度分值:
def pearson(v1, v2):
# 简单求和
sum1 = sum(v1)
sum2 = sum(v2)
# 求平方和
sum1Sq = sum([pow(v, 2) for v in v1])
sum2Sq = sum([pow(v, 2) for v in v2])
# 求乘积之和
pSum = sum([v1[i]*v2[i] for i in range(len(v1))])
# 计算 r (Pearson score)
num = pSum-(sum1*sum2/len(v1))
den = sqrt((sum1Sq-pow(sum1, 2)/len(v1))*(sum2Sq-pow(sum2, 2)/len(v1)))
if den == 0:
return 0
return 1.0-num/den请记住皮尔逊相关度的计算结构在两者完全匹配的情况下为1.0, 而在两者毫无关系的情况下则为0.0。上述代码的最后一行,返回的是以1.0 减去皮尔逊相关度之后的结果,这样做的目的是为了让相似度越大的两个元素之间的距离变得更小。
分级聚类算法中的每一个聚类,可以是树种的枝节点,也可以是与数据集中实际数据行相对应的叶节点(在本例中,即为一个博客)。每一个聚类还包含了指示其位置的信息,这一信息可以是来自叶节点的行数据,也可以是来自枝节点的经合并后的数据。我们可以新建一个bicluster类,将所有这些属性存放其中,并以此来描述这棵层级树。在cluster.py中新建一个类,以代表“聚类”这一类型
class bicluster:
def __init__(self, vec, left=None, right=None, distance=0.0, id=None):
self.left = left
self.right = right
self.vec = vec
self.id = id
self.distance = distance分级聚类算法以一组对应于原始数据项的聚类开始。函数的主循环部分会尝试每一组可能的配对并计算它们的相关度,以此来找出最佳配对。最佳配对的两个聚类会被合并成一个新的聚类。新生成的聚类中所包含的数据,等于将两个旧聚类的数据求均值之后得到的结果。这一过程会一直重复下去,直到只剩下一个聚类为止。由于整个计算过程可能会非常耗时,所以不妨将每个配对的相关度计算结果保存起来,因为这样的计算会反复发生,直到配对中的某一项被合并到另一个聚类中为止。
将hcluster算法加入clusters.py 文件中:
def hcluster(rows, distance=pearson):
distances={}
currentclustid=1
# 最开始的聚类就是数据集中的行
clust=[bicluster(rows[i], id=i) for i in range(len(rows))]
while len(clust) > 1:
lowestpair = (0,1)
closest = distance(clust[0].vec, clust[1].vec)
# 遍历每一个配对,寻找最小距离
for i in range(len(clust)):
for j in range(i+1, len(clust)):
# 用distances来缓存距离的计算值
if (clust[i].id, clust[j].id) not in distances:
distances[(clust[i].id, clust[j].id)] = distance(clust[i].vec, clust[j].vec)
d = distances[(clust[i].id, clust[j].id)]
if d < closest:
closest = d
lowestpair = (i, j)
# 计算两个聚类的平均值
mergevec=[
(clust[lowestpair[0]].vec[i]+clust[lowestpair[1]].vec[i])/2.0
for i in range(len(clust[0].vec))]
# 建立新的聚类
newcluster = bicluster(mergevec, left=clust[lowestpair[0]],
right=clust[lowestpair[1]],
distance=closest, id=currentclustid)
# 不在原始集合中的聚类,其id为负数
currentclustid -= 1
del clust[lowestpair[1]]
del clust[lowestpair[0]]
clust.append(newcluster)
return clust[0]因为每个聚类都指向构造该聚类时被合并的另两个聚类,所以我们可以递归搜索由该函数最终返回的聚类,以重建所有的聚类及叶节点。运行分级聚类算法:
blognames, words, data = readfile('blogdata.txt')
clust = hcluster(data)执行过程也许会花费一些时间。将距离值保存起来可以极大地加快执行速度,但是对于算法而言,计算每一对博客的相关度仍然是必要的。为了加快这一过程,我们可借助外部库来计算距离值。为了检视执行的结果,我们可以编写一个简单的函数,递归遍历聚类树,并将其以类似文件系统层级结果的形式打印出来。将printclust函数添加到clusters.py 中:
def printclust(clust, labels=None, n=0):
# 利用缩进去来建立层级布局
for i in range(n):
print ' ',
if clust.id < 0:
# 负数标记代表这是一个分支
print '-'
else:
# 正数标记代表这是一个叶节点
if labels==None:
print clust.id
else:
print labels[clust.id]
# 现在开始打印右侧分支和左侧分支
if clust.left != None:
printclust(clust.left, labels=labels, n=n+1)
if clust.right != None:
printclust(clust.right, labels=labels, n=n+1)这样的输出结果看起来不是非常的美观,并且对于读取博客列表这样的大数据集而言,这样做法会比较困难,不过它确实为我们提供了一个有关聚类算法是否工作良好的大体感觉。在下一节,我们将会看到如何建立一个图形版本的聚类树,这棵树更容易阅读,而且能够按比例缩放,从而可以显示出每个聚类的整体布局。
调用上述函数:
printclust(clust, labels=blognames)输出如下图所示:

因为我这里博客列表中的博客数量太少,所以画出来的树不是很明显。可以在一开始的feedlist 中多添加些博客的url。
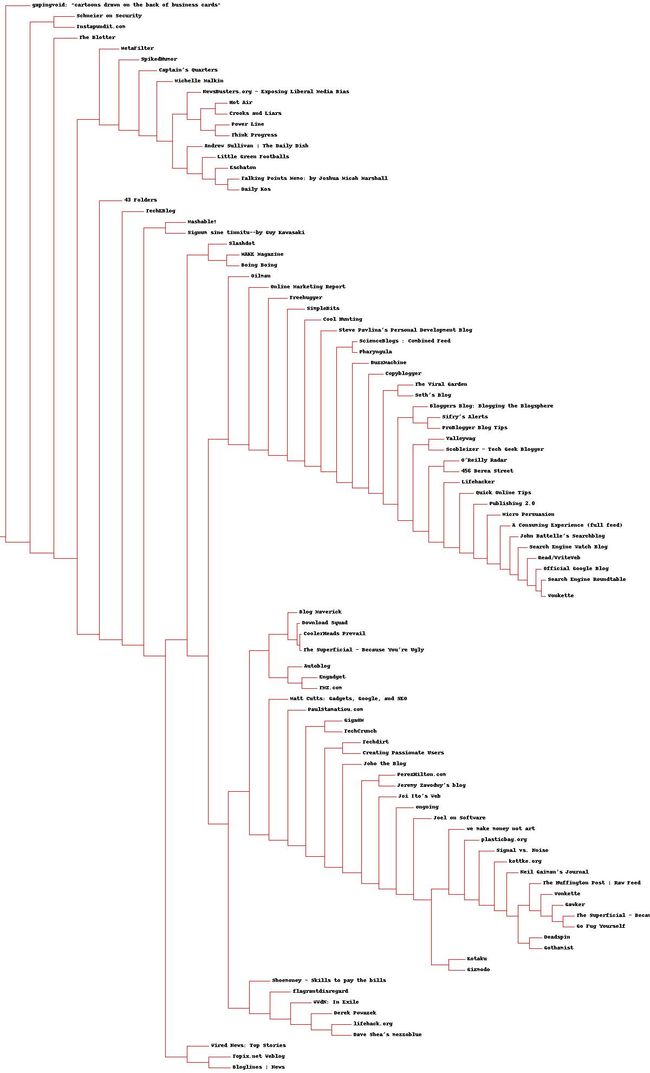
五、绘制树状图
使用本书给的blogdata.txt来绘制树状图,代码如下:
def getheight(clust):
# 这是一个叶节点吗?若是,则高度为1
if clust.left==None and clust.right==None:
return 1
# 否则,高度为每个分支的高度之和
return getheight(clust.left)+getheight(clust.right)
def getdepth(clust):
# 一个叶节点的距离是0.0
if clust.left==None and clust.right==None:
return 0
# 一个枝节点的距离等于左右两侧分支中距离较大者
# 加上该枝节点自身的距离
return max(getdepth(clust.left), getdepth(clust.right))+clust.distance
def drawdendrogram(clust, labels, jpeg='clusters.jpg'):
# 高度和宽度
h = getheight(clust)*20
w = 1200
depth = getdepth(clust)
# 由于宽度是固定的,因此我们需要对距离值做相应的调整
scaling = float(w-150)/depth
# 新建一个白色背景的图片
img = Image.new('RGB', (w, h), (255, 255, 255))
draw = ImageDraw.Draw(img)
draw.line((0, h/2, 10, h/2), fill=(255, 0, 0))
# 画第一个节点
drawnode(draw, clust, 10, (h/2), scaling, labels)
img.save(jpeg, 'JPEG')
def drawnode(draw, clust, x, y, scaling, labels):
if clust.id<0:
h1 = getheight(clust.left)*20
h2 = getheight(clust.right)*20
top = y-(h1+h2)/2
bottom = y+(h1+h2)/2
# 线的长度
l1 = clust.distance*scaling
# 聚类到其子节点的垂直线
draw.line((x, top+h1/2, x, bottom-h2/2), fill=(255, 0, 0))
# 连接左侧节点的水平线
draw.line((x, top+h1/2, x+l1, top+h1/2), fill=(255, 0, 0))
# 连接右侧节点的水平线
draw.line((x, bottom-h2/2, x+l1, bottom-h2/2), fill=(255, 0, 0))
# 调用函数绘制左右节点
drawnode(draw, clust.left, x+l1, top+h1/2, scaling, labels)
drawnode(draw, clust.right, x+l1, bottom-h2/2, scaling, labels)
else:
# 如果这是一个叶节点,则绘制节点的标签
draw.text((x+5, y-7), labels[clust.id], (0, 0, 0))
blognames, words, data = readfile('blogdata.txt')
clust = hcluster(data)
# printclust(clust, labels=blognames)
drawdendrogram(clust, blognames, jpeg='blogclust.jpg')画出来的图如下所示: