表驱动法是一种编程模式——从表里面查找信息而不适用逻辑语句。事实上,凡是能通过逻辑语句来选择的事物,都可以通过查表来选择。对简单的情况而言,使用逻辑语句更为容易和直白。但随着逻辑链的越来越复杂,查表法也愈发显得更具吸引力
使用表驱动法的两个问题
在使用表驱动法的时候,必须要解决两个问题。首先,你必须要回答怎样从表中查询条目的问题。你可以用一些数据来直接访问表。比如说,如果你希望把数据按月进行分类,那么创建一个月份表是非常直接了当的。
例子:灵活的消息格式
你可以用表来描述那种有太多变化,多得无法用代码表示的逻辑。
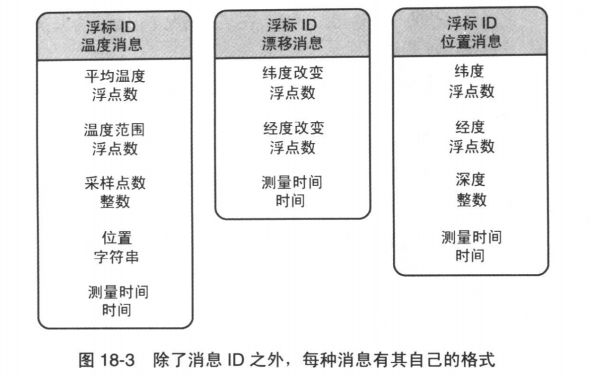
假设你编写一个子程序,打印存储在一份文件中的消息。通常该文件中会存储大约500条消息,而每份文件会存有大约20多种不同的消息。这些消息源自于一些浮标(buoy),提供有关水温,浮标位置等信息。
方法一 基于逻辑的方法
如果你采用基于逻辑的方法,那么你可能会读取每一条消息,检查其ID,然后调用一个阅读,解释以及打印一种消息的子程序。如果你有20种消息,那么就需要20个子程序。你还要写出不知道多少底层子程序去支持它们——例如,你可能需要一个PrintBuoyTemperatureMessage()子程序来打印浮标温度消息。用面向对象的方法也好不到哪里去:你通常会用一种抽象的消息对象,并为每种消息类别派生出一个子类
方法二面向对象的方法
如果你采用某种面向对象的方法,那么问题的逻辑将被隐藏在对象继承结构里,但是基本结构还是同样复杂:
while more messages to read
Read a message header
Decode to message ID from the message header
If the message header is type 1 then
Instantiate a type 1 message object
Else if the message header is type 2 then
Instantiate a type 2 message object
...
Else if the message header is type 19 then
Instantiate a type 19 message object
Else if the message header is type 20 then
Instantiate a type 20 message object
无论是直接写逻辑,还是把它包含在特定的类里面,这20种消息中每一种都要有自己的消息打印子程序。
Print "Buoy Temperature Message"
Read a floating-point value
Print "Temperature Range"
Print the floating-point value
Read a ineger value
Print "Number of Samples"
Print the ineger value
Read a character string
Print "Location"
Print the character string
Read a time of day
Print "Time of Measurement"
Print the time of day
表驱动法
表驱动法要比之前几种方式都经济。其中的消息阅读子程序由一个循环组成,该循环负责读入每一个消息头,对其ID解码,在Message数组种查询其消息描述,然后每次都调用同一个子程序来解释该消息。用了表驱动法之后,你可以用一张表来描述每种消息的格式,而不是再把它们硬编码进程序逻辑里。这样会降低初期编码的难度,生产更少的代码,并且无须修改代码就可以轻松地进行维护
enum FiledType{
FiledType_FloatingPoint,
FiledType_Interger,
FiledType_String,
FiledType_TimeOfDay,
FiledType_Boolean,
FiledType_BitField,
FiledType_last = FiledType_BitField
}
不用再为20种消息中的每一种硬编码打印子程序,你可以只创建少数几个子程序,分别打印每一种基本数据类型——浮点,整型,字符串等。你可以把每种消息的内容描述放在一张表里,然后再根据该表种的描述来分别解释每一个信息。
Message Begin
NumFileds 5
MessageName "Buoy Temperature Message"
Field 1, FloatingPoint, "Average Temperature"
Field 2, FloatingPoint, "Temperature Range"
Message End
这张表既可以硬编码再程序里,也可以再程序启动时或者随后从文件种读取。
一旦把消息定义读入程序,那么你就能把所有的信息嵌入再数据里面,而不必再程序的逻辑里面了。数据要比逻辑更为灵活。当消息格式改变的时候,修改数据是很容易的,如果必须要新增一种消息类型,那么只须往数据表里再添加一项元素即可。
下面就是表驱动法种最上层循环的伪代码
While more message to read
Read a message header
Decode the message ID from the message header
Look up the message description in the message-description table
Read the message filelds and print them based on the message description
End While
与基于逻辑方法的伪代码不同,这里的伪代码并没用做任何简化,因为它的逻辑实在是太简单了。在这一层下面的逻辑里面,你会发现一个子程序就可以解释消息描述表里面的消息描述,读入消息数据并且打印消息。这个子程序比任何一个基于逻辑的消息打印子程序都要通用,它不算太复杂,而且它只是1个子程序,而不是20个。
While more fields to print
Get the field type from the message description
case (fileld type)
of( floating type )
read a floating-point value
print the field label
print the floating-point value
of( integer )
read a integer value
print the field label
print the integer value
of( character string )
read a character string
print the field label
print the character string
of( time of day )
read a time of day
print the field label
print the time of day
of( boolean )
read a single flag
print the field label
print the single flag
of( bit field )
read a bit field
print the field label
print the bit field
End Case
End While
诚然,这个有着6种情况的子程序要比只负责打印浮点温度消息的子程序长一些。但它是你要使用的唯一的打印子程序。你不必为了其他那19种消息再写19个子程序。这个子程序可以处理6种字段类型,负责处理所有的消息类型。
这个子程序也显示出了实现这类表查询操作的最复杂的一种方法,因为它用到了一个case语句。另外一种方法是创建一个抽象的AbstractFileld类,然后为每一种字段类型派生一个子类。这样你就能无须使用case语句
class AbstractField{
public:
virtual void ReadAndPrint( string ,FileStatus &) = 0;
}
class FloatingPointField : pulblic AbstractField{
public:
virtual void ReadAndPrint( string, FileStatus &){
...
}
}
class IntegerField...
class StringField...
这段代码片段为每个类声明了一个成员函数,它具有一个字符串参数和一个FileStatus参数
下一步是声明一个数组以存放这一组对象。该数组就是查询表,如下
AbstractField* field[ Field_Last]
建立对象表的最后一部是把具体对象的名称赋给这个Field数组
field[ Field_FloatingPoint ] = new FloatingPointField() field[ Field_Integer] = new Field_Integer() field[ Field_String] = new Field_String() field[ Field_TimeOfDay ] = new Field_TimeOfDay() field[ Field_Boolean ] = new Field_Boolean() field[ Field_BitField ] = new Field_BitField()
这段代码片段假定,位于赋值语句右边的FloatingPointField等标识符类型为AbstractField的对象的名称。把这些对象赋值给数组中的数组元素意味着,为了调用正确的ReadAndPrint()子程序,你只需要引用一个数组元素而不用直接使用某个具体类型的对象
fieldIdx = 1
while( (fieldIdx < = numFieldsInMessage) && (fileStatus == OK) ){
fieldType = fieldDescription [ fieldIdx ].FieldType
fieldName = fieldDescription [ fieldIdx ].FieldName
field[ fieldType].ReadAndPrint (fieldName, fileStatus)
}
你可以在任何一种面向对象语言中使用这种方法。与写长篇if语句,case语句或者大量的子程序相比,这种方法更不容易出错,更容易维护并且效率更好。
使用继承和多态的设计并不一定就是好的设计。在前面“面向对象的方法一节里用的那种生搬硬套的面向对象设计,所需要的代码量和一个生硬的功能设计一样多——甚至更多。那种方法使解决方案变得更复杂,而不是变得更简单。再这个例子里面,核心的设计理念既不是面向对象也不是面向功能——而是使用一个深思熟虑的查找表。