Python---选择正确的内置函数和标准库实例(附代码)
1:选择正确的内置函数
Python有一个大型标准库,但只有一个内置函数的小型库,这些函数总是可用的,不需要导入。它们每一个都值得我们仔细研究,尤其是在其中一些函数的情况下,可以用什么替代更好
1.1 使用enumerate()而不是range()进行迭代
假设有一个元素列表,需要遍历列表,同时访问索引和值。
有一个名为FizzBuzz的经典编码面试问题可以通过迭代索引和值来解决。在FizzBuzz中,首先获得一个整数列表,任务是执行以下操作:
(1)用“fizz”替换所有可被3整除的整数
(2)用“buzz”替换所有可被5整除的整数
(3)将所有可被3和5整除的整数替换为“fizzbuzz”
# 普通用法,使用range()解决此问题
numbers = [45, 22, 14, 65, 97, 72]
for i in range(len(numbers)):
if numbers[i] % 3 == 0 and numbers[i] % 5 == 0:
numbers[i] = 'fizzbuzz'
elif numbers[i] % 3 == 0:
numbers[i] = 'fizz'
elif numbers[i] % 5 == 0:
numbers[i] = 'buzz'
numbers
运行结果:
![]()
Range允许通过索引访问数字元素,并且对于某些特殊情况也是一个很有用的工具。但在这种情况下,我们希望同时获取每个元素的索引和值,更优雅的解决方案使用enumerate():
numbers = [45, 22, 14, 65, 97, 72]
for i,num in enumerate(numbers):
if num % 3 == 0 and num % 5 == 0:
numbers[i] = 'fizzbuzz'
elif num % 3 == 0:
numbers[i] = 'fizz'
elif num % 5 == 0:
numbers[i] = 'buzz'
numbers
运行结果:
![]()
此外,使用内置函数enumerate():
对于每个元素,enumerate()返回一个计数器和元素值。计数器默认为0,也是元素的索引。不想在0开始你的计数?只需使用可选的start参数来设置偏移量
numbers = [45, 22, 14, 65, 97, 72]
for i,num in enumerate(numbers,start = 50):
print(i,num)
运行结果:
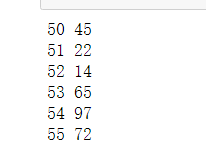
可以看到,通过使用start参数,访问所有相同的元素,从第一个索引开始,但现在我们的计数从指定的整数值开始。
1.2 使用递推式构造列表而不是map()和filter()
首先看看如何构造对map()的调用以及等效的递推构造列表:
numbers= [3, 2, 5, 1, 10, 7]
def square(x):
return x*x
print(list(map(square,numbers)))
print([square(x) for x in numbers])
运行结果:

使用map()和列表推导的两种方法都返回相同的值,但列表推导更容易阅读和理解
numbers= [3, 2, 5, 1, 10, 7]
def is_old(x):
return bool(x % 2)
print(list(map(is_old,numbers))) # bool()和bool(0) 返回False,其他为True
print(list(filter(is_old,numbers)))
print([x for x in numbers if is_old(x)])
print([square(x) for x in numbers if is_old(x)]) # 结合使用
运行结果:

就像在map中看到的那样,filter和列表推导方法返回相同的值,但列表推导更容易理解。
1.3 使用f-Strings格式化字符串
Python有很多不同的方法来处理字符串格式化,有时候不知道使用哪个,f-strings支持使用字符串格式化迷你语言,以及强大的字符串插值。这些功能允许添加变量甚至有效的Python表达式,并在添加到字符串之前在运行时对它们进行评估。
def get_name_and_decades(name, age):
return f"My name is {name} and I'm {age} years old."
print(get_name_and_decades("Maria", 31))
运行结果:
![]()
1.4 使用sorted()对复杂列表进行排序
大量的编码面试问题需要进行某种排序,并且有多种有效的方法可以进行排序。除非需要实现自己的排序算法,否则通常最好使用sorted()。 已经看到排序的最简单用法,例如按升序或降序排序数字或字符串列表:
默认情况下,sorted()已按升序对输入进行排序,而reverse关键字参数则按降序排序
sorted([6,5,3,7,2,4,1])
# 输出结果:[1, 2, 3, 4, 5, 6, 7]
sorted(['cat', 'dog', 'cheetah', 'rhino', 'bear'], reverse=True)
# 输出结果:['rhino', 'dog', 'cheetah', 'cat', 'bear']
值得了解的是可选关键字key,它允许在排序之前指定将在每个元素上调用的函数。添加函数允许自定义排序规则,如果要对更复杂的数据类型进行排序,这些规则特别有用。
animals = [{'type': 'penguin', 'name': 'Stephanie', 'age': 8},
{'type': 'elephant', 'name': 'Devon', 'age': 3},
{'type': 'puma', 'name': 'Moe', 'age': 5},]
sorted(animals, key=lambda animal: animal['age'])
运行结果:

通过传入一个返回每个元素年龄的lambda函数,可以按每个字典的单个值对字典列表进行排序。在这种情况下,字典现在按年龄按升序排序。
1.5 有效利用数据结构
选择正确的数据结构会对性能产生重大影响。除了理论数据结构之外,Python还在其标准数据结构实现中内置了强大而方便的功能
- 1:使用set存储唯一值
如果需要从现有数据集中删除重复元素。新的开发人员有时会在列表应该使用集合时执行此操作,这会强制执行所有元素的唯一性。
import random
all_words = "all the words in the world".split()
def get_random_word(all_words):
return random.choice(all_words)
get_random_word(all_words)
随机选择的结果:
![]()
应该重复调用get_random_word()以获取1000个随机单词,然后返回包含每个唯一单词的数据结构。以下是两种常见的次优方法和一种好的方法。
# 糟糕的方法
def get_unique_words():
words = []
for i in range(1000):
word = get_random_word()
if word not in words:
words.append(word)
return words
这种方法很糟糕,因为必须将每个新单词与列表中已有的每个单词进行比较。意味着随着单词数量的增加,查找次数呈二次方式增长。换句话说,时间复杂度在O(N^2)的量级上增长。
换一种更好的方法:
def get_unique_words():
words = set()
for i in range(1000):
words.add(get_random_word())
return words
那么为什么使用与第二种方法不同的集合呢? 它们是不同的,因为集合存储元素的方式允许接近恒定时间检查值是否在集合中,而不像需要线性时间查找的列表。查找时间的差异意味着添加到集合的时间复杂度以O(N)的速率增长,这在大多数情况下比第二种方法的O(N^2)好得多。
- 2:使用生成器节省内存
前面提到,列表推导是方便的工具,但有时会导致不必要的内存使用。
比如:找到前1000个正方形的总和,从1开始
res = sum([i * i for i in range(1,1001)])
print(res) # 输出结果:333833500
很快将结果输出,但是,这里发生了什么? 它正在列出要求的每个完美的方块,并将它们全部加起来。 具有1000个完美正方形的列表在计算机术语中可能不会很大,但是1亿或10亿是相当多的信息,并且很容易占用计算机的可用内存资源。 有一种解决内存问题的快捷方法:只需用括号替换方括号。
sum((i * i for i in range(1, 1001)))
# 输出结果:333833500
生成器表达式并不真正的创建数字列表,而是返回一个生成器对象,此对象在每次计算出一个条目后,把这个条目"产生"(yield)出来。生成器表达式使用了"惰性计算"或称作"延时求值"的机制。 序列过长,并且每次只需要获取一个元素时,应该考虑生成器表达式而不是列表解析。
因此,当sum通过重复调用. next ()来迭代生成器对象时,生成器检查i 等于多少,计算i * i,在内部递增i,并将正确的值返回到sum。该设计允许生成器用于大量数据序列,因为一次只有一个元素存在于内存中
- 3:使用.get()和.setdefault()在字典中定义默认值
最常见的编程任务之一涉及添加,修改或检索可能在字典中或可能不在字典中的项。Python字典具有优雅的功能,可以使这些任务简洁明了。
# 假设,我们要找出cowboy字典中的name字段对应的值
# 如果存在,则返回相应的值。否则,它返回默认值。
cowboy = {'age': 32, 'horse': 'mustang', 'hat_size': 'large'}
if 'name' in cowboy:
name = cowboy['name']
else:
name = 'The Man with No Name'
name
运行结果:
![]()
虽然上述方法可以清楚地检查key确实有效,但如果使用.get(),它可以很容易地用一行代替
Python 字典(Dictionary) get() 函数返回指定键的值,如果值不在字典中返回默认值
name = cowboy.get('name','The Man with No Name')
name
输出结果:
![]()
2 利用Python的标准库
2.1 使用collections.defaultdict()处理缺少的字典键
假设有一群学生,你需要记录他们在家庭作业上的成绩。输入值是具有格式(student_name,grade)的元组列表,但是希望轻松查找单个学生的所有成绩而无需迭代列表。
student_grades = {}
grades = [('elliot', 91),
('neelam', 98),
('bianca', 81),
('elliot', 88),]
for name,grade in grades:
if name not in student_grades:
student_grades[name] = []
student_grades[name].append(grade)
student_grades
输出结果:

其实还有一个更简洁的方法,可以使用defaultdict,它扩展了标准的dict功能,允许你设置一个默认值,如果key不存在,它将按默认值操作:
from collections import defaultdict
student_grades = defaultdict(list)
for name,grade in grades:
student_grades[name].append(grade)
student_grades
![]()
2.2 使用collections.Counter计算Hashable对象
假如有一长串没有标点符号或大写字母的单词,想要计算每个单词出现的次数,可以使用字典或defaultdict增加计数,但collections.Counter提供了一种更清晰,更方便的方法。Counter是dict的子类,它使用0作为任何缺失元素的默认值,并且更容易计算对象的出现次数:
# 当你将单词列表传递给Counter时,它会存储每个单词以及该单词在列表中出现的次数
from collections import Counter
words = "if there was there was but if there was not there was not".split()
counts = Counter(words)
counts
运行结果:
![]()
如果需要找出两个最常见的词是什么,只需使用.most_common()
counts.most_common(2)
输出结果:

2.3 使用字符串常量访问公共字符串组
检查字母是否都是大写字母
import string
def is_upper(word):
for letter in word:
if letter not in string.ascii_uppercase:
return False
return True
print(is_upper('Thanks Sir'))
print(is_upper('LOL'))
运行结果:

2.4 使用Itertools生成排列和组合¶
对于排列,元素的顺序很重要,因此(“sam”、“devon”)表示与(“devon”、“sam”)不同的配对,这意味着它们都将包含在列表中。
import itertools
friends = ['BeiJing', 'ShangHai', 'ChongQing', 'GuangZhou']
list(itertools.permutations(friends, r=2))
运行结果:

itertools.combinations()生成组合。这些也是输入值的可能分组,但现在值的顺序无关紧要。因为(‘sam’、‘devon’)和(‘devon’、‘sam’)代表同一对,所以输出列表中只会包含它们中的一个。
list(itertools.combinations(friends, r=2))
运行结果:
