【推荐系统】【论文阅读笔记】A Neural Network Approach to Quote Recommendation in Writings
原作者:谭继伟、万晓军、肖建国
引语(quote pr quotation)是在自己的陈述中抄写别人的话。引语是一种常见的语言现象,常用作引语,以更好地阐明意思或支持自己的观点。正确使用引语通常能使陈述更优雅、更有说服力。然而,使用引语的能力通常受到所知引语数量的限制。有时我们很想在某个地方引用一句话支持我们的观点,但只能对合意的引语产生一些模糊的印象,甚至根本不知道相关的引语。尽管网络上有很多引语库(例如BrainyQuote,引语页面),但即使在今天的搜索引擎的帮助下,也很难找到合适的报价。引用推荐是一项任务,根据作者所写的上下文,自动推荐作者在写作时可能需要的引用。图7展示了quote、context和quote recommendation任务。Tan等人首先介绍了支持我们的观点,但只能对合意的引语产生一些模糊的印象,甚至根本不知道相关的引语。尽管网络上有很多引语库(例如BrainyQuote[1],引语页面[2]),但即使在今天的搜索引擎的帮助下,也很难找到合适的报价。引用推荐是一项任务,根据作者所写的上下文,自动推荐作者在写作时可能需要的引用。图7展示了quote、context和quote recommendation任务。Tan等人。[29]首先介绍了引语推荐任务,并对该任务进行了初步的研究。他们提出了一个learning to rank框架,通过使用许多手动设计的特征对候选引语进行排名,来推荐潜引语。本文表明,在给定的上下文环境下猜测哪些引语可以使用是可行的。
Tan等人探索quote recommendation任务的多个特征,并显示上下文-上下文特征最有用。上下文-上下文特征的作用是通过比较训练语料库中的上下文和查询上下文来推荐候选引语。这是一种我们称之为“二阶”特征的特征。相对而言,“一阶”特性,即查询上下文和候选引语之间的直接相关性,对系统的贡献很小。因此,Tan等人]发现很难对引语的含义进行建模或表示。然而,二阶特征的计算代价很高,在实际的推荐系统中是不可接受的。在本文中,我们试图解决上述问题,并以更直接的方式解决引语推荐任务,通过直接建模上下文和引语之间的相关性。
直接建立上下文和引用之间的关联模型的主要困难在于两个方面。首先,引语通常是短文,由一个或几个句子组成,引语不太可能与上下文共享常用词。其次,引用可以通过比喻、隐喻等文学手法,以一种含蓄的方式表达其意义。因此,引语中使用的词可能具有不同于其正常含义的含义。以金哈伯德(Kim Hubbard)的名言为例:“一个好的战线是爱情或战争的一半”,在名言中,“战线”往往更像是“过程”而不是“战役”的意思。所有这些现象使得我们很难理解或表达引用的真正含义,即使使用最先进的自然语言处理技术。
在这项研究中,我们提出了一种基于长短期记忆(LSTM)的神经网络引语推荐方法。我们使用LSTMs学习上下文和引语的分布表示,然后根据所学上下文和引语向量的相关性来完成推荐任务。我们引入一种机制,将有用的引用特性集成到引用嵌入学习框架中,以帮助学习更好地表示引用含义。此外,在所提出的模型中,我们尝试根据不同的上下文和主题,甚至根据不同的作者偏好,学习不同引语中使用的单词的具体嵌入。我们在[29]中使用的基准数据集上进行了实验,并将我们提出的方法与几种最先进的方法进行了比较。
这项工作的主要贡献是:
•我们的工作是首次将神经网络模型应用于引语推荐任务。神经网络模型避免了二阶特征的计算,因而更适合于实际的推荐系统。
•在神经网络模型中,我们利用复杂的LSTM编码器结构来应对学习好的引用语义表示的挑战。我们通过学习的权重向量来利用主题和作者信息,并学习引用词的不同嵌入。实验结果表明,该策略具有较好的学习引用表示的能力。
•在大型真实数据集上的实验结果表明,我们的方法达到了最先进的性能。尽管我们提出的方法只利用了很少的特性,但是它比使用大量手工设计的特性的最新的学习排序方法要好得多。
我们将论文整理如下。第二节介绍了相关工作。在第三节中,我们介绍了报价推荐任务和本文中使用的一些关键概念。在第4节中,我们开始介绍我们提出的方法。在第五节中,我们介绍了引用数据集和实验,以及讨论。最后,在第六节中,我们对本文进行了总结,并介绍了未来的工作。
1.相关工作
引文推荐任务是一项基于内容的推荐任务,与之最为密切相关的工作是面向科技写作的基于内容的引文推荐。对于基于内容的引文推荐任务,一个典型的方向是利用文本内容来辅助推荐。Shaparenko和Joachims[25]讨论了引文上下文和论文内容的相关性,并将语言模型应用于推荐任务。Huang等人 提出将被引用的论文用唯一的id表示为新语言中的新词,并利用翻译模型直接估计在给定的引用上下文中被引用论文的概率。He等 提出了一种上下文感知方法,用于测量引用上下文和文档之间基于上下文的相关性。一些研究试图通过翻译模型或分布式语义表达来弥补被引论文与被引上下文之间的语言差异。Lu等人。[17] 假设引文语境中使用的语言和被引文中使用的语言是不同的,并提出使用翻译模型来弥补这一差距。Tang等人提出了一个联合嵌入模型来学习上下文和引文的低维联合嵌入空间。Huang等人 提出学习单词和被引用文档的分布语义表示,然后利用神经概率模型估计给定引用上下文的论文被引用的概率。他们通过估计每个需要引文的单词的概率来制定任务,并且他们不使用深层神经网络来完成推荐任务。总之,引文推荐方法的思想,如建立引文语境与被引文的相关性模型,利用语境信息,缩小不同“语言”之间的差距,对引文推荐任务也有帮助。这项工作与以往工作的主要区别在于,由于它们与科学论文的不同,我们关注的是引文的特点。此外,我们训练神经网络以达到弥合语言鸿沟和利用关联和上下文信息的目的,从而以最直接的方式处理推荐任务。
引用推荐最直接的方法是测量引用和上下文之间的关系。上下文可以看作段落级文本,引用可以看作句子级文本。一种常用的文本相关性度量方法是用向量表示文本,并根据文本的向量表示来度量文本的相关性。例如经典流行的袋装词文本相似度模型,以及最近出现的句子或段落分布式语义嵌入方法,如段落向量和skipthough向量。嵌入方法试图从一个大的语料库中学习任意长度文本的语义表示,然后以无监督或有监督的方式将学习到的向量应用到特定的任务中。非特异性任务嵌入在多个任务中都能取得良好的效果,但总体上仍然不能很好地表示文本。相反,为了将任意长度词的文本映射到句子或语篇层面的向量中,更多的方法尝试在词的嵌入上学习构词运算符。复合算子可以通过递归网络、卷积网络和循环网络等神经网络在特定任务中学习。学习到的文本表示向量通常能在特定任务上取得更好的效果。在本文中,我们也遵循这一策略,学习在引文推荐任务中的具体引文和上下文表示。
处理文本关联性的另一种方法不是学习每个文本的显式表示,而是直接建模一对文本的关系。大多数典型的作品使用卷积神经网络来获得匹配分数。这些方法可以应用于释义识别和语义文本相似度等成对问题。主要缺点是,对于像quote推荐这样的任务,成对匹配方法必须分别枚举和计算所有可能的对。
2. 问题表述
在本节中,我们将介绍本文中使用的一些概念。
引用q是一个词的序列q={t1,t2,……,t|q|}。在quote recommendation任务中,除了单词序列外,quote还与作者和主题的人工注释标记相关联。
在包含引语的连贯语句中,引语前的单词命名为left context,引号后的单词命名为right context。因为引文的上下文是左上下文和右上下文的连接。请求上下文(Query context)是用户提供的上下文,用于推荐系统相应地推荐引文。
候选引语是可能与查询上下文相关的引号。在这项研究中,数据集中的所有引用都被视为候选引用。整套候选引语构成一个引语集。
黄金引语是一个最适合查询上下文的候选引用,。在本研究中,一个查询上下文的黄金引文是与实际文献中的查询上下文一起出现的实际引文。因为两个完全相同的上下文几乎不可能用两个不同引文出现,所以我们假设每个查询上下文都有一个且只有一个黄金引文。
引文建议:给定一组查询上下文C以及一组候选引文Q,对于每个查询上下文c∈C,系统需要返回一个Q中的排名引号列表。
3.模型
3.1预备知识
3.1.1 RNN
循环神经网络(RNN)是一种试图利用输入数据的序列信息的神经网络结构。处理序列数据的能力对于文本处理非常重要。RNN的思想是对序列中的每个元素执行相同的任务,输出取决于前面的计算。图1左边是最基础的RNN,右边是它的展开形式。展开的表单显示完整输入序列的网络。在图1中,xt是时间步骤t的输入,st是时间步骤t的隐藏状态。隐藏状态的作用类似于网络的“内存”。st是根据以前的隐藏状态和当前步骤的输入,如:st=f(Uxt+Wst-1)。U和W是合并当前输入xt和隐藏状态st影响的矩阵。函数f是非线性函数,例如tanh或sigmoid。ot是步骤t的输出,ot可以计算为:ot=f(Vst)。由于递归结构,RNN可以处理任意长度的输入,而隐藏状态使得RNN能够捕获输入序列的依赖关系。

3.1.2 LSTM
尽管RNN可以接受任意长度的输入序列,但是如果输入序列太长,它通常无法捕获依赖关系,太长的输入序列也会导致梯度消失和爆炸问题。长-短期记忆(LSTM)是一种递归神经网络,它能较好地解决长期依赖性和梯度消失的捕获困难。LSTMs已经成功地应用于许多任务,并取得了最新的成果。LSTM是一种用LSTM单元代替RNN中递归单元的RNN。LSTM的核心思想是在递归神经单元中引入门来控制数据流。门是以乘法方式应用的层,因此,如果门为1,则可以保留来自门层的值;如果门为0,则可以将该值归零。特别是,使用三个门来控制是否忘记当前单元值(忘记门f)、是否应该读取其输入(输入门i)以及是否输出新单元值(输出门o)。一个LSTM单元如图2所示。在本文中,我们使用了记忆单元的定义,如:
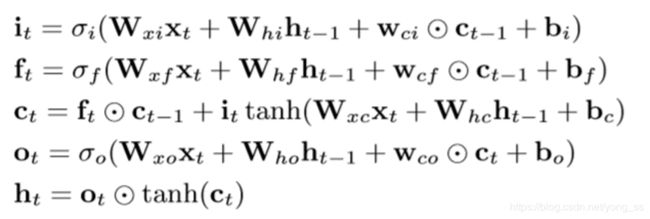

其中σo是logistic sigmoid函数,i、f、o和c分别表示输入门、遗忘门、输出门和单元。所有向量的大小与隐藏向量h的大小相同。.W是权重矩阵,其下标表示不同的门,例如Whf表示隐藏忘记门矩阵。b是偏置矢量,在图2中省略。
3.2 框架
给定查询上下文c,我们的引文推荐系统的目的是返回查询上下文c和所有候选引文qi∈Q之间的关联度得分rc=[r(cq1),r(cq2),……,r(cq|Q|)],然后根据rc对Q中的引号进行排序。输入是上下文和候选引号的单词序列,以及人工注释的作者和引号的主题标记。在我们的框架中,我们首先通过一个引文编码器将每个引文qi转换为一个引文嵌入向量vqi,然后通过一个上下文编码器将上下文c转换为一个上下文嵌入向量vc。然后相关性得分可以计算为rc=VQvcT,其中VQ=[vq;……vq|Q|]。
在训练过程中,根据查询上下文和黄金引文对的训练数据,学习好上下文编码器和引文编码器。然后,通过生成上下文和引文向量并计算相关性得分,将学习到的编码器用于引文推荐任务。候选引文是根据相关性得分进行排名,作为最终推荐名单。我们框架的主要区别在于,我们使用一个复杂的引号编码器来集成引号的主题和作者信息,并且引号编码器可以学习不同引号中使用的单词的特定嵌入。在接下来的部分中,我们将首先介绍上下文编码器,然后介绍引文编码器,最后描述学习目标和算法。
3.3上下文编码器
上下文编码器的目标是将段落级上下文(一个可变长度的单词序列)映射到一个固定维的表示向量中。由于能够表示长序列的单词并在许多任务中成功使用,我们使用LSTM作为编码器。上下文编码器的体系结构如图3所示。
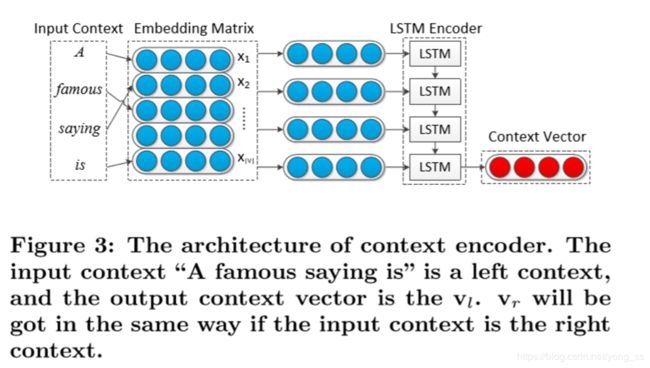
以往的工作和实验表明,LSTM虽然具有较好的处理长距离依赖关系的能力,但如果输入序列太长,其性能仍会下降。在我们的工作中,我们没有将上下文作为一个整体来处理,而是分别对左上下文和右上下文进行编码,从而得到左上下文向量vl和右上下文向量vr。那么vc=vl+vr。我们通过对左上下文和右上下文使用共享的LSTM编码器来实现这一点,这样既可以避免输入序列过长的风险,又不会引入新的参数。如图3所示,上下文编码器的输入是上下文单词序列。通过字嵌入矩阵X或称为查找表将输入字映射到字嵌入向量xi。
X∈R(|V |×d),其中| V |是词汇大小,d是单词嵌入的维度。然后按顺序将字向量输入LSTM。LSTM反复接收输入并更改其隐藏状态。在LSTM接收到所有输入序列后,我们将最终的隐藏状态作为上下文向量。接下来,我们将介绍输入上下文表示和单词嵌入矩阵。
3.3.1文本矩阵
在我们的框架中,我们尝试将每个引文或上下文编码为分布式语义表示,或者更具体地说,是一个d维向量。这个目标是通过LSTM编码器实现的。LSTM编码器的输入是一个单词序列,其中每个单词t都来自词汇表V。T由|T|×|V|维矩阵表示、 矩阵T的每一行对应一个单词。T的行跟随T的单词序列。每个单词由一个| V |维one-shot向量表示。
3.3.2嵌入矩阵
将原始的一个one-hot向量通过查找|v|×d维表X映射到分布向量中,X是单词嵌入矩阵,X的行i是字Ti的d维分布向量xi。单词嵌入矩阵X可以使用CBOW和Skip gram等单词嵌入模型进行预训练,也可以在神经网络框架中学习
3.4引文编码
在本小节中,我们将介绍引文编码器。我们使用不同于上下文编码器的引文编码器。究其原因,不仅引文和语境来自不同的作者,而且语录通常使用不同的表达方式。在我们的引文推荐框架中,一个好的引文表示模型是关键。为了解决引文表示的困难,我们利用因引文的外部特性并使用更复杂的体系结构。quote编码器的体系结构如图4所示。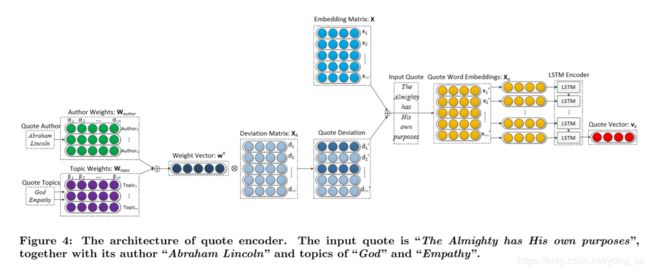
3.4.1体系结构
引文最直接的编码器是使用与图3中的上下文编码器相同的架构。引文和上下文共享一个通用的单词嵌入矩阵,尽管它们有不同的LSTM参数。我们将在稍后的实验中证明这个模型的性能不好。这表明,由于引文的特性,引文编码并不容易。引语往往以非平凡的方式来表达其意义,引语中使用的词语可能与它们的典型意义不同。一种直观的改进方法是为引号指定不同的单词嵌入矩阵。这使得对引文中所用单词的不同含义进行建模更加容易。然而,学习一个好的引用词嵌入矩阵仍然不容易。原因是,不同作者或不同主题的引文中的词语可能仍有很大差异。由于缺乏大量的引文语料库,很难学习好的引文嵌入方法。
在本研究中,我们提出一个更复杂的模型来解决上述问题。模型如图4所示。右边部分是典型的LSTM编码器,由“输入引文”分隔,使用引文单词嵌入矩阵和LSTM编码器将引文编码成向量表示。左半部分说明如何获得引文单词嵌入矩阵。关键是学习引文中单词的偏差嵌入矩阵Xd,通过将典型的嵌入矩阵X和引文偏差嵌入矩阵Xd合并得到引号q的最终引文单词嵌入矩阵Xq,如下所示:
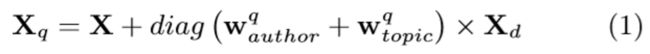
其中diag是根据向量构造对角矩阵的函数。图4中的“⊕”表示元素相加,“⊗”表示向量v与矩阵M之间的运算diag(v)×M。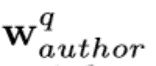 是作者权重向量,
是作者权重向量, 是q的主题权重向量。这两种权重向量分别来自作者权重矩阵
是q的主题权重向量。这两种权重向量分别来自作者权重矩阵![]() 和主题权重矩阵
和主题权重矩阵![]() ,而这两个矩阵是引入以用来反映该引文中用词的作者偏好以及主题偏好,这将在3.4.3中介绍。
,而这两个矩阵是引入以用来反映该引文中用词的作者偏好以及主题偏好,这将在3.4.3中介绍。
3.4.2偏差嵌入矩阵
偏差矩阵Xd允许模型学习引文中单词的不同单词嵌入,即学习单词表示在引文环境中的含义。但是,如果同一个单词的引文来自不同的作者或是谈论不同的话题,那么在不同的引语中使用的同一个单词的含义可能仍然不同。因此,偏差矩阵不能直接加入到典型的嵌入矩阵中,形成引文嵌入矩阵。相反,我们为每个引文学习一个权重向量W=![]() +
+![]() ,以控制哪些单词以及偏差应在多大程度上添加到典型的单词嵌入矩阵X中。
,以控制哪些单词以及偏差应在多大程度上添加到典型的单词嵌入矩阵X中。
3.4.3权重向量
|V|维权重向量w表示引文中每个单词的相应权重。w试图根据引语的特点,反映不同引语中词语的微妙用法。其基本思想是,该模型一般对引文学习一个偏差矩阵,从而使偏差矩阵反映出引文中词的潜在意义。然而,在不同的引语中使用的同一个词在意义上可能仍然不同。因此我们学习了两种不同的权重矩阵:作者偏好权重矩阵和主题偏好权重矩阵
![]() 包含所有不同作者的
包含所有不同作者的![]() ,Wtopic包含所有不同主题的Wtopic。给定一个引用q,首先根据其作者得到其权重向量
,Wtopic包含所有不同主题的Wtopic。给定一个引用q,首先根据其作者得到其权重向量 ,然后根据其主题求和得到的全部主题向量得到
,然后根据其主题求和得到的全部主题向量得到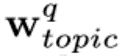 。然后根据方程(1)计算Xq。
。然后根据方程(1)计算Xq。
这样,模型可以根据作者、主题和上下文,为每个引文学习不同的单词嵌入矩阵。这样做的好处有两个:一是可以学习一个不同的嵌入矩阵来更好地模拟单词的意义;二是新的嵌入矩阵不能自由设置,依赖于主题和作者。权值矩阵有助于避免过度拟合,利用传统神经网络框架中不易加入的外部信息。该模型假设在引文中使用的一个词可能有不同的含义,但这些不同的含义有一些共同点,并且在偏离程度上有所不同。假设并不完美,但实验结果表明了该策略的积极影响。尽管该模型为每个引文学习不同的单词嵌入矩阵,但由于操作可以公式化为矩阵乘法,因此该体系结构没有引入昂贵的计算。
有一个直观的观察,虽然在引语中使用的词可能有不同于其典型意义的含义,但在一个引语中的大多数词仍然保留原来的含义。因此,我们在权值矩阵中加入l1范数的稀疏约束,以减少字数的变化。
3.5模型训练
在这一部分中,我们介绍了我们框架的学习目标和学习算法。
损失函数:给定一个查询上下文向量vc和候选引用向量VQ,关联度得分rc可以计算为rc=VQvcT。我们在rc上应用softmax函数,得到查询上下文c在所有候选报价上的概率分布向量pc,如下所示:

其中上标(i)表示向量的第i个元素。然后用分类交叉熵定义c的损失Lc:
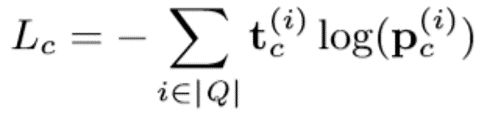
如果Q中的第i个引号是c的黄金引文,![]() =1,否则
=1,否则![]() =0。
=0。
损失函数L是C中所有查询上下文的分类交叉熵损失的总和,以及参数正则化:
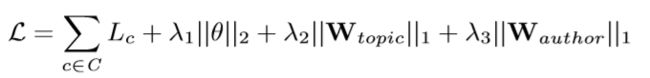
其中θ是要学习的所有参数的集合,包括上下文编码器和引号编码器的LSTM参数(上下文编码器和引号编码器有它们各自的W∗∗、b∗和W∗∗参数,但我们在此不加以区分):θ={Wxi,Whi,Wxf,Whf,Wxc,Whc,Wxo,Who,bi,bf,bc,bo,wci,wcf,wco,Wtopic,Wauthor,Xd}.
最优算法:在该模型中,我们使用AdaGrad算法来优化损失函数,该算法已被证明是一种非常有效的算法,并广泛应用于神经网络。AdaGrad算法通过除以累积梯度平方根来调整学习速率,从而适应不同参数下不同步骤的学习速率。使用步长η,AdaGrad在时间步长t计算特征i的学习率为:

其中,gt,i 表示在时间步骤t处特征i的梯度,并且是避免除以0的小值。
避免过度拟合:由于神经网络结构深、参数多,使得神经网络具有很好的拟合能力,也容易产生过拟合问题。在本文中,由于现有的训练数据还不是很大,所以过拟合问题是一个有待解决的问题。我们介绍了三种避免过度拟合的技术,即正则化、dropout和预先训练单词嵌入。正则化是通过在损失函数中加入参数的l2范数正则化来实现的。dropout通过将LSTM编码器的部分输入随机设置为0来完成。
典型的单词嵌入矩阵X既可以在模型中学习,也可以使用预先训练的矩阵。我们使用一个预训练的单词嵌入矩阵并保持它的固定,因为我们发现如果在模型中学习嵌入矩阵,它很容易被过度拟合。如果嵌入矩阵是在相对较小的数据集中学习的,那么它很容易被过度拟合。经验是,对于为给定任务调整单词嵌入,对于十万的任务应该有要求数据集的最小大小。