Cocos2dx_3.x新的渲染流程
目录(?)[-]
- 第一渲染流程从2x到3x的变化
- 第二RenderCommand的类型
- 第三如何在Cocos2d-x中自己设置渲染功能
最近几天,我都在学习如何在Cocos2d-x3.2中使用OpenGL来实现对图形的渲染。在网上也看到了很多好的文章,我在它们的基础上做了这次的我个人认为比较完整的总结。当你了解了Cocos2d-x3.2中对图形渲染的流程,你就会觉得要学会写自己的shader才是最重要的。
第一,渲染流程从2.x到3.x的变化。
在2.x中,渲染过程是通过递归渲染树(Rendering tree)这种图关系来渲染关系图。递归调用visit()函数,并且在visit()函数中调用该节点的draw函数渲染各个节点,此时draw函数的作用是直接调用OpenGL代码进行图形的渲染。由于visit()和draw函数都是虚函数,所以要注意执行时的多态。那么我们来看看2.x版本中CCSprite的draw函数,如代码1。
代码1:
那么我们也看看3.x中Sprite的draw函数,如代码2。
代码2:
从代码1和代码2的对比中,我们很容易就发现2.x版本中的draw函数直接调用OpengGL代码进行图形渲染,而3.x版本中draw的作用是把RenderCommand添加到CommandQueue中,至于这样做的好处是,实际的渲染API进入其中一个与显卡直接交流的有独立线程的RenderQueue。
从Cocos2d-x3.0开始,Cocos2d-x引入了新的渲染流程,它不像2.x版本直接在每一个node中的draw函数中直接调用OpenGL代码进行图形渲染,而是通过各种RenderCommand封装起来,然后添加到一个CommandQueue队列里面去,而现在draw函数的作用就是在此函数中设置好相对应的RenderCommand参数,然后把此RenderCommand添加到CommandQueue中。最后在每一帧结束时调用renderer函数进行渲染,在renderer函数中会根据ID对RenderCommand进行排序,然后才进行渲染。
下面我们来看看图1、图2,这两个图形象地表现了Cocos2d-x3.x下RenderCommand的封装与传递与及RenderCommand的排序。
图1:

图2:

上面所说的各个方面都有点零碎,下面就对渲染的整个流程来一个从头到尾的梳理吧。下面是针对3.2版本的,对于2.x版本的梳理不做梳理,因为我用的是3.2版本。
首先,我们Cocos2d-x的执行是通过Application::run()来开始的,如代码3,此代码目录中在xx\cocos2d\cocos\platform\对应平台的目录下,这是与多平台实现有关的类,关于如何实现多平台的编译,你可以参考《cocos2d-x3.2源码分析(一)类FileUtils--实现把资源放在Resources文件目录下达到多平台的引用 》中我对平台编译的分析。以防篇幅过长,只截取了重要部分,如需详解,可以直接查看源码。
代码3:
代码4:
代码5:
代码6:
void Node::visit(Renderer* renderer, const Mat4 &parentTransform, uint32_t parentFlags)
{
// quick return if not visible. children won't be drawn.
if (!_visible)
{
return;
}
uint32_t flags = processParentFlags(parentTransform, parentFlags);
// IMPORTANT:
// To ease the migration to v3.0, we still support the Mat4 stack,
// but it is deprecated and your code should not rely on it
Director* director = Director::getInstance();
director->pushMatrix(MATRIX_STACK_TYPE::MATRIX_STACK_MODELVIEW);
director->loadMatrix(MATRIX_STACK_TYPE::MATRIX_STACK_MODELVIEW, _modelViewTransform);
int i = 0;
if(!_children.empty())
{
sortAllChildren();
// draw children zOrder < 0
for( ; i < _children.size(); i++ )
{
auto node = _children.at(i);
if ( node && node->_localZOrder < 0 )
node->visit(renderer, _modelViewTransform, flags);
else
break;
}
// self draw
this->draw(renderer, _modelViewTransform, flags);
for(auto it=_children.cbegin()+i; it != _children.cend(); ++it)
(*it)->visit(renderer, _modelViewTransform, flags);
}
else
{
this->draw(renderer, _modelViewTransform, flags);
}
director->popMatrix(MATRIX_STACK_TYPE::MATRIX_STACK_MODELVIEW);
// FIX ME: Why need to set _orderOfArrival to 0??
// Please refer to https://github.com/cocos2d/cocos2d-x/pull/6920
// reset for next frame
// _orderOfArrival = 0;
} 代码7:
代码8:
void DrawNode::draw(Renderer *renderer, const Mat4 &transform, uint32_t flags)
{
_customCommand.init(_globalZOrder);
_customCommand.func = CC_CALLBACK_0(DrawNode::onDraw, this, transform, flags);
renderer->addCommand(&_customCommand);
}
void Sprite::draw(Renderer *renderer, const Mat4 &transform, uint32_t flags)
{
// Don't do calculate the culling if the transform was not updated
_insideBounds = (flags & FLAGS_TRANSFORM_DIRTY) ? renderer->checkVisibility(transform, _contentSize) : _insideBounds;
if(_insideBounds)
{
_quadCommand.init(_globalZOrder, _texture->getName(), getGLProgramState(), _blendFunc, &_quad, 1, transform);
renderer->addCommand(&_quadCommand);
#if CC_SPRITE_DEBUG_DRAW
_customDebugDrawCommand.init(_globalZOrder);
_customDebugDrawCommand.func = CC_CALLBACK_0(Sprite::drawDebugData, this);
renderer->addCommand(&_customDebugDrawCommand);
#endif //CC_SPRITE_DEBUG_DRAW
}
} 从代码8中,我们可以看到在draw()函数 向RenderQueue中添加RenderCommand,当然有的类的draw()不是向RenderQueue中添加RenderCommand,而是直接使用OpenGL的API直接进行渲染,或者做一些其他的事情。
那么当draw()都递归调用完了,我们来看看最后进行渲染的Renderer::render() 函数,如代码9。
代码9:
代码10:
GROUP_COMMAND,MESH_COMMAND五种,这些类型的讲解在下一节。
从代码10中,好像没有与OpenGL相关的代码,有点囧。其实这OpenGL的API调用是在Renderer::drawBatched
Quads()、BatchCommand::execute()中。在代码10中,我们也看到在QUAD_COMMAND类型中调用了drawBatchedQuads(),如代码11。在CUSTOM_COMMAND中调用了CustomCommand::execute(),如代码12。在BATCH_COMMAND中调用了BatchCommand::execute(),如代码13。在MESH_COMMAND类型中调用了MeshCommand::preBatchDraw()和MeshCommand::batchDraw()。至于GROUP_COMMAND类型,就递归它组里的成员。
代码11:
void Renderer::drawBatchedQuads()
{
//TODO we can improve the draw performance by insert material switching command before hand.
int quadsToDraw = 0;
int startQuad = 0;
//Upload buffer to VBO
if(_numQuads <= 0 || _batchedQuadCommands.empty())
{
return;
}
if (Configuration::getInstance()->supportsShareableVAO())
{
//Set VBO data
glBindBuffer(GL_ARRAY_BUFFER, _buffersVBO[0]);
// option 1: subdata
// glBufferSubData(GL_ARRAY_BUFFER, sizeof(_quads[0])*start, sizeof(_quads[0]) * n , &_quads[start] );
// option 2: data
// glBufferData(GL_ARRAY_BUFFER, sizeof(quads_[0]) * (n-start), &quads_[start], GL_DYNAMIC_DRAW);
// option 3: orphaning + glMapBuffer
glBufferData(GL_ARRAY_BUFFER, sizeof(_quads[0]) * (_numQuads), nullptr, GL_DYNAMIC_DRAW);
void *buf = glMapBuffer(GL_ARRAY_BUFFER, GL_WRITE_ONLY);
memcpy(buf, _quads, sizeof(_quads[0])* (_numQuads));
glUnmapBuffer(GL_ARRAY_BUFFER);
glBindBuffer(GL_ARRAY_BUFFER, 0);
//Bind VAO
GL::bindVAO(_quadVAO);
}
else
{
#define kQuadSize sizeof(_quads[0].bl)
glBindBuffer(GL_ARRAY_BUFFER, _buffersVBO[0]);
glBufferData(GL_ARRAY_BUFFER, sizeof(_quads[0]) * _numQuads , _quads, GL_DYNAMIC_DRAW);
GL::enableVertexAttribs(GL::VERTEX_ATTRIB_FLAG_POS_COLOR_TEX);
// vertices
glVertexAttribPointer(GLProgram::VERTEX_ATTRIB_POSITION, 3, GL_FLOAT, GL_FALSE, kQuadSize, (GLvoid*) offsetof(V3F_C4B_T2F, vertices));
// colors
glVertexAttribPointer(GLProgram::VERTEX_ATTRIB_COLOR, 4, GL_UNSIGNED_BYTE, GL_TRUE, kQuadSize, (GLvoid*) offsetof(V3F_C4B_T2F, colors));
// tex coords
glVertexAttribPointer(GLProgram::VERTEX_ATTRIB_TEX_COORD, 2, GL_FLOAT, GL_FALSE, kQuadSize, (GLvoid*) offsetof(V3F_C4B_T2F, texCoords));
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, _buffersVBO[1]);
}
//Start drawing verties in batch
for(const auto& cmd : _batchedQuadCommands)
{
auto newMaterialID = cmd->getMaterialID();
if(_lastMaterialID != newMaterialID || newMaterialID == QuadCommand::MATERIAL_ID_DO_NOT_BATCH)
{
//Draw quads
if(quadsToDraw > 0)
{
glDrawElements(GL_TRIANGLES, (GLsizei) quadsToDraw*6, GL_UNSIGNED_SHORT, (GLvoid*) (startQuad*6*sizeof(_indices[0])) );
_drawnBatches++;
_drawnVertices += quadsToDraw*6;
startQuad += quadsToDraw;
quadsToDraw = 0;
}
//Use new material
cmd->useMaterial();
_lastMaterialID = newMaterialID;
}
quadsToDraw += cmd->getQuadCount();
}
//Draw any remaining quad
if(quadsToDraw > 0)
{
glDrawElements(GL_TRIANGLES, (GLsizei) quadsToDraw*6, GL_UNSIGNED_SHORT, (GLvoid*) (startQuad*6*sizeof(_indices[0])) );
_drawnBatches++;
_drawnVertices += quadsToDraw*6;
}
if (Configuration::getInstance()->supportsShareableVAO())
{
//Unbind VAO
GL::bindVAO(0);
}
else
{
glBindBuffer(GL_ARRAY_BUFFER, 0);
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, 0);
}
_batchedQuadCommands.clear();
_numQuads = 0; 代码12:
代码13:
void BatchCommand::execute()
{
// Set material
_shader->use();
_shader->setUniformsForBuiltins(_mv);
GL::bindTexture2D(_textureID);
GL::blendFunc(_blendType.src, _blendType.dst);
// Draw
_textureAtlas->drawQuads();
} 从代码11、代码12、代码13中,我们都看到了这些函数中对OpenGl的API调用来进行渲染。其中特别提醒一下,在CustomCommand::execute()中直接调用的函数是我们设置的回调函数。在这个函数中,我们可以自己使用OpenGL的API进行图形的渲染。这就在第三节中讲 如何在Cocos2d-x中自己设置渲染功能中向_customCommand添加的函数。在这里我先给出简便的方式,_customCommand.func = CC_CALLBACK_0(HelloWorld::onDraw, this)。
以上就是把一个完整的渲染的流程都梳理了一片,下面我给出了流程图,如图3。
图3:

第二,RenderCommand的类型。
这里的类型讲解主要参考这篇文章中关于RenderComman的类型讲解。
QUAD_COMMAND:QuadCommand类绘制精灵等。
所有绘制图片的命令都会调用到这里,处理这个类型命令的代码就是绘制贴图的openGL代码,下一篇文章会详细介绍这部分代码。
CUSTOM_COMMAND:CustomCommand类自定义绘制,自己定义绘制函数,在调用绘制时只需调用已经传进来的回调函数就可以,裁剪节点,绘制图形节点都采用这个绘制,把绘制函数定义在自己的类里。这种类型的绘制命令不会在处理命令的时候调用任何一句openGL代码,而是调用你写好并设置给func的绘制函数,后续文章会介绍引擎中的所有自定义绘制,并自己实现一个自定义的绘制。
BATCH_COMMAND:BatchCommand类批处理绘制,批处理精灵和粒子
其实它类似于自定义绘制,也不会再render函数中出现任何一句openGL函数,它调用一个固定的函数,这个函数会在下一篇文章中介绍。
GROUP_COMMAND:GroupCommand类绘制组,一个节点包括两个以上绘制命令的时候,把这个绘制命令存储到另外一个_renderGroups中的元素中,并把这个元素的指针作为一个节点存储到_renderGroups[0]中。
第三,如何在Cocos2d-x中自己设置渲染功能。
1.第一种方法针对的是整个图层的渲染。
重写visit()函数,并且在visit()函数中直接向CommandQueue添加CustomCommand,设置好回调函数,这个比较直接,如代码14,代码14是子龙山人《基于Cocos2d-x学习OpenGL ES 2.0》第一篇中的部分代码。或者重写draw()函数,并且在draw()函数中向CommandQueue添加CustomCommand,设置好回调函数,这个就比较按照正规的流程走。
代码14:
void HelloWorld::visit(cocos2d::Renderer *renderer, const Mat4 &transform, bool transformUpdated)
{
Layer::draw(renderer, transform, transformUpdated);
//send custom command to tell the renderer to call opengl commands
_customCommand.init(_globalZOrder);
_customCommand.func = CC_CALLBACK_0(HelloWorld::onDraw, this);
renderer->addCommand(&_customCommand);
}
void HelloWorld::onDraw()
{
//question1: why the triangle goes to the up side
//如果使用对等矩阵,则三角形绘制会在最前面
Director::getInstance()->pushMatrix(MATRIX_STACK_TYPE::MATRIX_STACK_MODELVIEW);
Director::getInstance()->loadIdentityMatrix(MATRIX_STACK_TYPE::MATRIX_STACK_MODELVIEW);
Director::getInstance()->pushMatrix(MATRIX_STACK_TYPE::MATRIX_STACK_PROJECTION);
Director::getInstance()->loadIdentityMatrix(MATRIX_STACK_TYPE::MATRIX_STACK_PROJECTION);
auto glProgram = getGLProgram();
glProgram->use();
//set uniform values, the order of the line is very important
glProgram->setUniformsForBuiltins();
auto size = Director::getInstance()->getWinSize();
//use vao
glBindVertexArray(vao);
GLuint uColorLocation = glGetUniformLocation(glProgram->getProgram(), "u_color");
float uColor[] = {1.0, 1.0, 1.0, 1.0};
glUniform4fv(uColorLocation,1, uColor);
// glDrawArrays(GL_TRIANGLES, 0, 6);
glDrawElements(GL_TRIANGLES, 6, GL_UNSIGNED_BYTE,(GLvoid*)0);
glBindVertexArray(0);
CC_INCREMENT_GL_DRAWN_BATCHES_AND_VERTICES(1, 6);
CHECK_GL_ERROR_DEBUG();
Director::getInstance()->popMatrix(MATRIX_STACK_TYPE::MATRIX_STACK_PROJECTION);
Director::getInstance()->popMatrix(MATRIX_STACK_TYPE::MATRIX_STACK_MODELVIEW);
} 从代码14中,我们看到重写visit()函数,在visit()函数中直接向RenderQueue添加RenderCommand,即“renderer->addCommand(&_customCommand);”,由于此RenderCommand类型为CustomCommand,所以要添加处理图形渲染的回调函数,即“_customCommand.func = CC_CALLBACK_0(HelloWorld::onDraw, this);”,这行代码就是添加回调函数的,onDraw()函数中调用OpengGL的API渲染图形。关于func是如何被调用,可以参考上面的代码12上下文的分析。
2.第二种方法针对个别精灵。
有时候,我们只要对个别精灵进行特效的处理,这个精灵需要使用我们自己编写的Shader,而图层其他的元素按默认处理就行了。这时候就需要第二种方法了。设置好Shader,向精灵添加Shader,最后在重写draw函数,在draw函数中进行特效的处理,如代码15,代码15是《捕鱼达人3》教程第二节的代码。
代码15:
bool FishLayer::init()
{
...省略了不相关的代码。
// 将vsh与fsh装配成一个完整的Shader文件。
auto glprogram = GLProgram::createWithFilenames("UVAnimation.vsh", "UVAnimation.fsh");
// 由Shader文件创建这个Shader
auto glprogramstate = GLProgramState::getOrCreateWithGLProgram(glprogram);
// 给精灵设置所用的Shader
m_Sprite->setGLProgramState(glprogramstate);
//创建海龟所用的贴图。
auto textrue1 = Director::getInstance()->getTextureCache()->addImage("tortoise.png");
//将贴图设置给Shader中的变量值u_texture1
glprogramstate->setUniformTexture("u_texture1", textrue1);
//创建波光贴图。
auto textrue2 = Director::getInstance()->getTextureCache()->addImage("caustics.png");
//将贴图设置给Shader中的变量值u_lightTexture
glprogramstate->setUniformTexture("u_lightTexture", textrue2);
//注意,对于波光贴图,我们希望它在进行UV动画时能产生四方连续效果,必须设置它的纹理UV寻址方式为GL_REPEAT。
Texture2D::TexParams tRepeatParams;
tRepeatParams.magFilter = GL_LINEAR_MIPMAP_LINEAR;
tRepeatParams.minFilter = GL_LINEAR;
tRepeatParams.wrapS = GL_REPEAT;
tRepeatParams.wrapT = GL_REPEAT;
textrue2->setTexParameters(tRepeatParams);
//在这里,我们设置一个波光的颜色,这里设置为白色。
Vec4 tLightColor(1.0,1.0,1.0,1.0);
glprogramstate->setUniformVec4("v_LightColor",tLightColor);
//下面这一段,是为了将我们自定义的Shader与我们的模型顶点组织方式进行匹配。模型的顶点数据一般包括位置,法线,色彩,纹理,以及骨骼绑定信息。而Shader需要将内部相应的顶点属性通道与模型相应的顶点属性数据进行绑定才能正确显示出顶点。
long offset = 0;
auto attributeCount = m_Sprite->getMesh()->getMeshVertexAttribCount();
for (auto k = 0; k < attributeCount; k++) {
auto meshattribute = m_Sprite->getMesh()->getMeshVertexAttribute(k);
glprogramstate->setVertexAttribPointer(s_attributeNames[meshattribute.vertexAttrib],
meshattribute.size,
meshattribute.type,
GL_FALSE,
m_Sprite->getMesh()->getVertexSizeInBytes(),
(GLvoid*)offset);
offset += meshattribute.attribSizeBytes;
}
//uv滚动初始值设为0
m_LightAni.x = m_LightAni.y = 0;
return true;
}
void FishLayer::draw(Renderer* renderer, const Mat4 &transform, uint32_t flags)
{
if(m_Sprite)
{
//乌龟从右向左移动,移出屏幕后就回到最右边
auto s = Director::getInstance()->getWinSize();
m_Sprite->setPositionX(m_Sprite->getPositionX()-1);
if(m_Sprite->getPositionX() < -100)
{
m_Sprite->setPositionX(s.width + 10);
}
auto glprogramstate = m_Sprite->getGLProgramState();
if(glprogramstate)
{
m_LightAni.x += 0.01;
if(m_LightAni.x > 1.0)
{
m_LightAni.x-= 1.0;
}
m_LightAni.y += 0.01;
if(m_LightAni.y > 1.0)
{
m_LightAni.y-= 1.0;
}
glprogramstate->setUniformVec2("v_animLight",m_LightAni);
}
}
Node::draw(renderer,transform,flags);
} 以上都是我通过阅读别人的代码总结的方法,不知道还有没有其他的在Cocos2d-x中自己设置渲染功能的方法,如果有的话,请告诉我,直接在我的博客留言就可以了。
参考资料:
1.http://cn.cocos2d-x.org/article/index?type=wiki&url=/doc/cocos-docs-master/manual/framework/native /wiki/renderer/zh.md
2.http://cocos2d-x.org/wiki/Cocos2d_v30_renderer_pipeline_roadmap
3.http://cn.cocos2d-x.org/tutorial/show?id=1336
4.http://blog.csdn.net/bill_man/article/details/35839499
5.《Cocos2d-x高级开发教程》2.1.4节
6.Cocos2d-x3.2和Cocos2d-x2.0.4源码
如需转载,请标明出处:http://blog.csdn.net/cbbbc/article/details/39449945
/************************************************************************************************************************/
上一篇文章介绍了cocos2d-x的基本渲染结构,这篇顺着之前的渲染结构介绍渲染命令QUAD_COMMAND命令的部分,通过这部分的函数,学习opengl处理图片渲染的方法,首先介绍这节需要涉及到的基本概念VAO和VBO。
VAO和VBO:
顶点数组对象(Vertex Array Object 即VAO)是一个包含一个或数个顶点缓冲区对象(Vertex Buffer Object, 即 VBO)的对象,一般存储一个可渲染物体的所有信息。顶点缓冲区对象(VertexBuffer Object VBO)是你显卡内存中的一块高速内存缓冲区,用来存储顶点的所有信息。
这些概念显得很晦涩,简而言之,一般我们绘制一些图形需要将所有顶点的信息存储在一个数组里,但是经常会出现一些点是被重复使用的,这样就会出现一个点的信息的存储空间被重复使用的问题,这样第一会造成存储控件的浪费,第二就是如果我们要修改这个点的信息,需要改多次。所以我们采用索引的方式来描述图形,这样可以用一个数组存储点的信息,另外一个数组存储点的索引,这样所有的点都是不同的,另外把顶点信息存储在显卡的内存中,减少了cpu向gpu传输数据的时间,提高了程序的渲染效率,这就是VBO,在OpenGL3.0中,出现了更进一步的VAO,VBO通过绘制上下文获得绘制状态,VAO可以拥有多个VBO,它记录所有绘制状态,它的代码更简洁,效率更高,在cocos2d-x的绘制中,我们会判断底层是否支持VAO,如果支持VAO,那么优先采用VAO绘制。二者的区别可以从初始化就可以看出来:
需要介绍的两个关键的函数
glBindBuffer:它绑定缓冲区对象表示选择未来的操作将影响哪个缓冲区对象。如果应用程序有多个缓冲区对象,就需要多次调用glBindBuffer()函数:一次用于初始化缓冲区对象以及它的数据,以后的调用要么选择用于渲染的缓冲区对象,要么对缓冲区对象的数据进行更新。
当传入的第二个参数第一次使用一个非零无符号整数时,创建一个新的缓冲区对象;当第二个参数是之前使用过的,这个缓冲区对象成为活动缓冲区对象;如果第二个参数值为0时,停止使用缓冲区对象
glBufferData:保留空间存储数据,他分配一定大小的(第二个参数)的openGL服务端内存,用于存储顶点数据或索引。这个被绑定的对象之前相关联的数据都会被清除。
glBufferData参数介绍
参数1,目标GL_ARRAY_BUFFER或者GL_ELEMENT_ARRAY_BUFFER
参数2,内存容量
参数3,用于初始化缓冲区对象,可以使一个指针,也可以是空
参数4,如何读写,可以选择如下几种
GL_DYNAMIC_DRAW:多次指定,多次作为绘图和图像指定函数的源数据,缓冲区对象的数据不仅常常需要进行更新,而且使用频率也非常高
GL_STATIC_DRAW:数据只指定一次,多次作为绘图和图像指定函数的源数据,缓冲区对象的数据只指定1次,但是这些数据被使用的频率很高
GL_STREAM_DRAW:数据只指定一次,最多只有几次作为绘图和图像指定函数的源数据,缓冲区对象中的数据常常需要更新,但是在绘图或其他操作中使用这些数据的次数较少
从初始化的代码上,为什么VAO反倒复杂了呢?因为他只是把绘制时需要做的一些事情提前放到初始化函数中,来看一下绘制流程。
可以看到,这些设置属性的函数放在了绘制函数里,虽然看似是一样的,但是绘制函数会被调用的更频繁,所以把这些函数放到初始化函数中可以大幅提高程序的效率。
这里介绍VAO的两个函数:
glMapBuffer函数返回一个指针,指向与第一个参数相关联的当前绑定缓冲区对象的数据存储。第一个参数与glBufferData的第一个参数一致。第二个参数是GL_READ_ONLY、GL_WRITE_ONLY或GL_READ_WRITE之一,表示可以对数据进行的操作。
glUnmapBuffer表示对当前绑定缓冲区对象的更新已经完成,并且这个缓冲区可以释放。
enableVertexAttribs激活相关属性,激活的属性可以调用glVertexAttribPointer指定数据源,可选的有VERTEX_ATTRIB_FLAG_POSITION,VERTEX_ATTRIB_FLAG_COLOR和VERTEX_ATTRIB_FLAG_TEX_COORDS,这里这个参数是激活这三个。
glVertexAttribPointer指定了渲染时第一个参数代表的索引值的顶点属性数组的数据格式和位置。
第一个参数指定要修改的顶点属性的索引值,包括VERTEX_ATTRIB_POSITION(位置),VERTEX_ATTRIB_COLOR(颜色),VERTEX_ATTRIB_TEX_COORDS(纹理坐标)。
第二个参数指定每个属性值的组件数量且必须为1、2、3、4之一。
第三个参数指定数组中每个组件的数据类型。可用的符号常量有GL_BYTE, GL_UNSIGNED_BYTE, GL_SHORT,GL_UNSIGNED_SHORT,GL_FIXED, 和 GL_FLOAT,初始值为GL_FLOAT。
第四个参数指定当被访问时,固定点数据值是否应该被归一化(GL_TRUE,意味着整数型的值会被映射至区间[-1,1](有符号整数),或者区间[0,1](无符号整数))或者直接转换为固定点值(GL_FALSE)。
第五个参数指定了一个属性到下一个属性之间的步长(这就允许属性值被存储在单一数组或者不同的数组中)。也就是连续顶点属性之间的偏移量。如果为0,那么它们是紧密排列在一起的。初始值为0。
第六个参数指定一个指针,指向数组中第一个顶点属性的第一个组件。初始值为0。
最后需要调用绘制元素函数,绘制这些信息
需要注意的是在Renderer的析构函数中要调用glDeleteBuffers来释放它的资源,并使它的标识可以其他缓冲区对象使用。
上一篇中介绍的几种渲染命令中的QUAD_COMMAND(这里把它称作四边形绘制)命令回调用drawBatchedQuads调用绘制函数,处理这个逻辑的命令是这样的:
void Renderer::flush()
{
//绘制
drawBatchedQuads();
//清空
_lastMaterialID = 0;
} 这个处理主要是把命令存入_batchedQuadCommands中,如果如果Quad数据量超过VBO的大小,那么调用绘制,将缓存的命令全部绘制
如果一直没有超过VBO的大小,drawBatchedQuads绘制函数将在flush被调用时调用
如有错误,欢迎指出
[转自]http://blog.csdn.net/bill_man/article/details/38314077/********************************************************************************************************************************************/
上一篇介绍了QUAD_COMMAND渲染命令,顺带介绍了VAO和VBO,这一篇介绍批处理渲染命令BatchCommand,批处理命令的处理在Render中比较简单
首先调用flush将之前缓存的VBO绘制出来,然后调用命令自己的执行函数,这个过程和CUSTOM_COMMAND是一样的,不同的是这里的execute调用的是BatchCommand确定的绘制函数,CUSTOM_COMMAND调用是传入的func函数,这里看一下BatchCommand的execute函数。
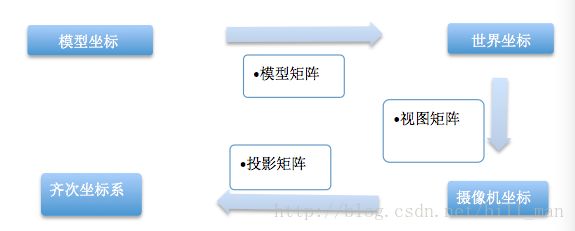
首先介绍其中一个重要的概念MVP,MVP即模型(Model)、视图(View)、投影(Projection)。
模型矩阵:所有物体都处于世界空间中,所以绘制和做变换的前提是把物体由模型空间转换到世界空间中,而这个转换就需要乘以模型矩阵。
视图矩阵:下一步需要把世界空间转换到相机空间或者是视角空间中,这需要乘以视图矩阵。
投影矩阵:最后需要将3d的立方体投影到一个2d平面上,需要从观察坐标系到齐次坐标系,需要乘以投影矩阵。整个过程如下图所示:
setUniformsForBuiltins函数
void GLProgram::setUniformsForBuiltins(const kmMat4 &matrixMV)
{
//通过flag中的变量判断是否使用了相关的矩阵,这些标志变量在updateUniforms被设置
kmMat4 matrixP;
kmGLGetMatrix(KM_GL_PROJECTION, &matrixP);
if(_flags.usesP)
setUniformLocationWithMatrix4fv(_uniforms[UNIFORM_P_MATRIX], matrixP.mat, 1);
if(_flags.usesMV)
setUniformLocationWithMatrix4fv(_uniforms[UNIFORM_MV_MATRIX], matrixMV.mat, 1);
if(_flags.usesMVP) {
kmMat4 matrixMVP;
kmMat4Multiply(&matrixMVP, &matrixP, &matrixMV);
setUniformLocationWithMatrix4fv(_uniforms[UNIFORM_MVP_MATRIX], matrixMVP.mat, 1);
}
if(_flags.usesTime) {
Director *director = Director::getInstance();
//这里不会使用真实的每帧时间去设置,那样太耗费效率
float time = director->getTotalFrames() * director->getAnimationInterval();
setUniformLocationWith4f(_uniforms[GLProgram::UNIFORM_TIME], time/10.0, time, time*2, time*4);
setUniformLocationWith4f(_uniforms[GLProgram::UNIFORM_SIN_TIME], time/8.0, time/4.0, time/2.0, sinf(time));
setUniformLocationWith4f(_uniforms[GLProgram::UNIFORM_COS_TIME], time/8.0, time/4.0, time/2.0, cosf(time));
}
if(_flags.usesRandom)
setUniformLocationWith4f(_uniforms[GLProgram::UNIFORM_RANDOM01], CCRANDOM_0_1(), CCRANDOM_0_1(), CCRANDOM_0_1(), CCRANDOM_0_1());
}这个函数里,有一个频繁出现的变量名uniforms,uniform是一种和着色器相关的,它必须被声明为全局变量,用于整个图元批次向保持不变的着色器传递数据,对于顶点着色器来说,可能最普遍的统一值就是变换矩阵,它通过调用glUniformXXXX系列函数向着色器传递数据,这里这个函数被封装了,调用setUniformLocationXXXX系列函数可以设置uniforms,这个函数首先通过调用updateUniformLocation函数判断这个uniforms的值是否确实被更新(在一个hash表里存上曾经设置过的键值对),如果确实需要被更新再调用glUniformXXXX更新这个uniforms,节约效率
bindTexture2DN函数主要是调用glActiveTexture和glBindTexture做贴图的绑定
glActiveTexture选择一个纹理单元,线面的纹理函数将作用于该纹理单元上,参数为符号常量GL_TEXTUREi ,i的取值范围为0~N-1,N是opengl实现支持的最大纹理单元数,这里,因为批处理只有一个纹理,所以textureUnit一直是0,由于使用缓存,只会被调用一次
glBindTexture建立一个绑定到目标纹理的有名称的纹理。比如把一个贴图绑定到一个形状上。
最后调用的绘制函数和上一篇介绍的类似,另外关于shader和混合的问题,将在后面单独开文章介绍
在引擎中使用BatchCommand这个命令的地方有两处ParticleBatchNode和SpriteBatchNode,使用方法很简单。
_batchCommand.init(
_globalZOrder,
_shaderProgram,
_blendFunc,
_textureAtlas,
transform);
renderer->addCommand(&_batchCommand); 需要说明的是,在3.0之后的版本中,由于添加了auto-batch功能,ParticleBatchNode和SpriteBatchNode的节约效率的功能已经不那么明显,但是3.0之前的版本中,把精灵放在SpriteBatchNode父节点上和将粒子系统放在ParticleBatchNode,是能够把相同的精灵批处理,对于相同的贴图只调用一次绘制函数,还是对提升效率很有帮助的。
如有错误,欢迎指出