Linux 内存管理窥探(11):伙伴系统(概述)
Linux 系统启动过程中使用 memblock 进行内存的简单管理,到了后期,初始化内存完毕后,使用大名鼎鼎的 Buddy System 来进行内存管理(分配/释放回收)
伙伴系统概述
伙伴系统是一个结合了2的方幂个分配器和空闲缓冲区合并计技术的内存分配方案, 其基本思想很简单. 内存被分成含有很多页面的大块, 每一块都是2个页面大小的方幂. 如果找不到想要的块, 一个大块会被分成两部分, 这两部分彼此就成为伙伴. 其中一半被用来分配, 而另一半则空闲. 这些块在以后分配的过程中会继续被二分直至产生一个所需大小的块. 当一个块被最终释放时, 其伙伴将被检测出来, 如果伙伴也空闲则合并两者.
举个例子:
伙伴系统的宗旨就是用最小的内存块来满足内核的对于内存的请求。在最初,只有一个块,也就是整个内存,假如为1M大小,而允许的最小块为64K,那么当我们申请一块200K大小的内存时,就要先将1M的块分裂成两等分,各为512K,这两分之间的关系就称为伙伴,然后再将第一个512K的内存块分裂成两等分,各位256K,将第一个256K的内存块分配给内存,这样就是一个分配的过程。下面我们结合示意图来了解伙伴系统分配和回收内存块的过程。
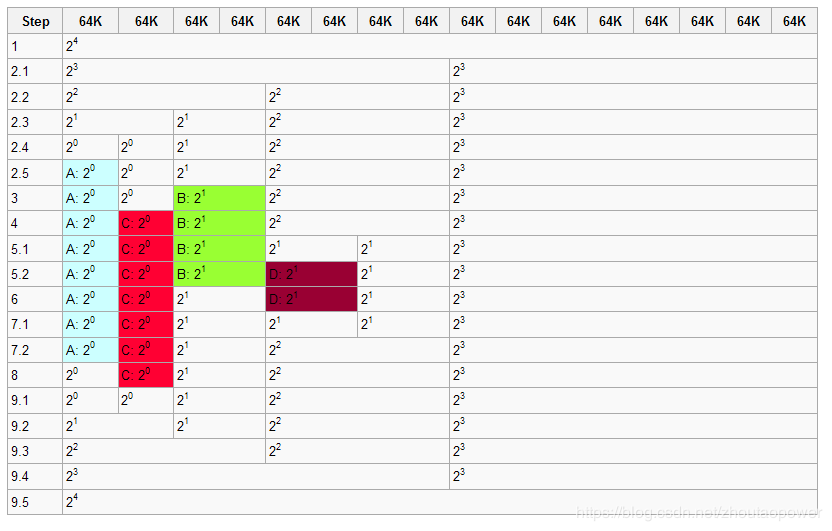
1 初始化时,系统拥有1M的连续内存,允许的最小的内存块为64K,图中白色的部分为空闲的内存块,着色的代表分配出去了得内存块。
2 程序A申请一块大小为34K的内存,对应的order为0,即2^0=1个最小内存块
2.1 系统中不存在order 0(64K)的内存块,因此order 4(1M)的内存块分裂成两个order 3的内存块(512K)
2.2 仍然没有order 0的内存块,因此order 3的内存块分裂成两个order 2的内存块(256K)
2.3 仍然没有order 0的内存块,因此order 2的内存块分裂成两个order 1的内存块(128K)
2.4 仍然没有order 0的内存块,因此order 1的内存块分裂成两个order 0的内存块(64K)
2.5 找到了order 0的内存块,将其中的一个分配给程序A,现在伙伴系统的内存为一个order 0的内存块,一个order1的内存块,一个order 2的内存块以及一个order 3的内存块
3 程序B申请一块大小为66K的内存,对应的order为1,即2^1=2个最小内存块,由于系统中正好存在一个order 1的内存块,所以直接用来分配
4 程序C申请一块大小为35K的内存,对应的order为0,同样由于系统中正好存在一个order 0的内存块,直接用来分配
5 程序D申请一块大小为67K的内存,对应的order为1
5.1 系统中不存在order 1的内存块,于是将order 2的内存块分裂成两块order 1的内存块
5.2 找到order 1的内存块,进行分配
6 程序B释放了它申请的内存,即一个order 1的内存块
7 程序D释放了它申请的内存
7.1 一个order 1的内存块回收到内存当中
7.2由于该内存块的伙伴也是空闲的,因此两个order 1的内存块合并成一个order 2的内存块
8 程序A释放了它申请的内存,即一个order 0的内存块
9 程序C释放了它申请的内存
9.1 一个order 0的内存块被释放
9.2 两个order 0伙伴块都是空闲的,进行合并,生成一个order 1的内存块m
9.3 两个order 1伙伴块都是空闲的,进行合并,生成一个order 2的内存块
9.4 两个order 2伙伴块都是空闲的,进行合并,生成一个order 3的内存块
9.5 两个order 3伙伴块都是空闲的,进行合并,生成一个order 4的内存块
Linux 伙伴系统
如例子所示,伙伴系统需要确定2的次幂,在 Linux 系统中,有一个宏:
#define MAX_ORDER 11来表征分配的时候的最大阶。
通常情况下,其值是 11。
伙伴系统的相关内容,保存并嵌入到 zone 结构中,其中的 free_area 代表了空闲内存链表:
struct zone
{
/* free areas of different sizes */
struct free_area free_area[MAX_ORDER];
};其中 free_area 也是一个结构体:
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};enum migratetype {
MIGRATE_UNMOVABLE,
MIGRATE_MOVABLE,
MIGRATE_RECLAIMABLE,
MIGRATE_PCPTYPES, /* the number of types on the pcp lists */
MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES,
#ifdef CONFIG_CMA
MIGRATE_CMA,
#endif
#ifdef CONFIG_MEMORY_ISOLATION
MIGRATE_ISOLATE, /* can't allocate from here */
#endif
MIGRATE_TYPES
};
这里,MAX_ORDER 的值是 11,所以呢,在 zone 结构的 free_area:
free_area[0] : 代表了 2 的 0 次方个页面组合成的空闲链表,即 1 个 page 组成的空闲链表
free_area[1] : 代表了 2 的 1 次方个页面组合成的空闲链表,即 2 个 page 组成的空闲链表
free_area[2] : 代表了 2 的 2 次方个页面组合成的空闲链表,即 4 个 page 组成的空闲链表
......
free_area[10] : 代表了 2 的 10 次方个页面组合成的空闲链表,即 2^10=1024 个 page 组成的空闲链表,即 4MB
而在 free_area 结构体,又有 list 链表数组,这个数组的下标是代表了这个空闲链表,这个是什么意思呢?因为在 Linux 中将同一个阶数的内存块,根据不同的属性,又分布到了不同的链表中,便于管理,比如,这块申请的内存,是否可移动?是否可回收?
所以根据这样构建出来的链表类似于:
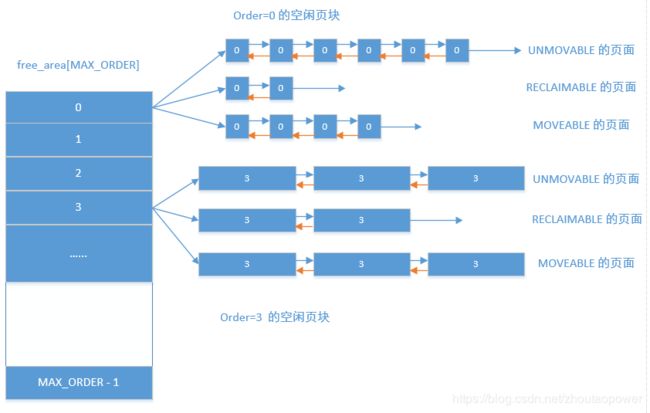
当然,上面这个图代表了一个 zone 中的结构,系统中有多个 zone,则,整个系统的情况为:
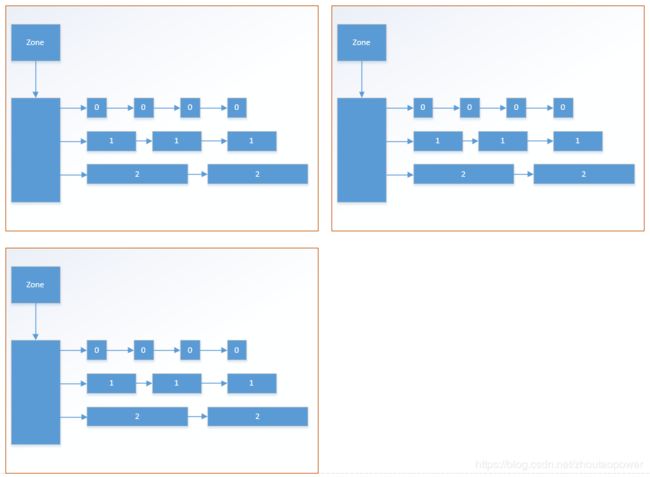
所以,根据上面的分析,知道了伙伴系统的基本概念,和 Linux 下,伙伴系统的结构组织。
这里我们看到,在组织每个 order 的链表的时候,分为了几种类型来进行组织,即 MIGRATE_TYPES,他代表了我们这个内存块的属性,数组是根据页框的移动性来划分的,这个玩意的根本目的是:减少内存碎片。他是在伙伴系统出来后,为了降低内存碎片提出来的一个方案。
所以,Linux 下,就根据可移动性来组织页
| 页面类型 | 描述 | 举例 |
| 不可移动页 | 在内存中有固定位置, 不能移动到其他地方. | 核心内核分配的大多数内存属于该类别 |
| 可移动页 | 可以随意地移动 | 属于用户空间应用程序的页属于该类别. 它们是通过页表映射的,如果它们复制到新位置,页表项可以相应地更新,应用程序不会注意到任何事 |
| 可回收页 | 不能直接移动, 但可以删除, 其内容可以从某些源重新生成. | 例如,映射自文件的数据属于该类别 kswapd守护进程会根据可回收页访问的频繁程度,周期性释放此类内存. , 页面回收本身就是一个复杂的过程. 内核会在可回收页占据了太多内存时进行回收, 在内存短缺(即分配失败)时也可以发起页面回收. |
1. 比如:如果没有按照上述来进行分类的话,会出现什么样的情况呢?
图中一共有32个页,只分配出了4个页框,但是能够分配的最大连续内存也只有8个页框(因为伙伴系统分配出去的内存必须是2的整数次幂个页框),内核解决这种问题的办法就是将不同类型的页进行分组:

假如上图中大部分页都是可移动页,而分配出去的四个页都是不可移动页,由于不可移动页插在了其他类型页的中间,就导致了无法从原本空闲的连续内存区中分配较大的内存块。
2. 如果按照上述进行分类,则:
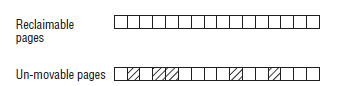
将可回收页和不可移动页分开,这样虽然在不可移动页的区域当中无法分配大块的连续内存,但是可回收页的区域却没有受其影响,可以分配大块的连续内存。
| 宏 | 类型 |
| MIGRATE_UNMOVABLE | 不可移动页 |
| MIGRATE_MOVABLE | 可移动页 |
| MIGRATE_RECLAIMABLE | 可回收页 |
| MIGRATE_PCPTYPES | 是per_cpu_pageset, 即用来表示每CPU页框高速缓存的数据结构中的链表的迁移类型数目 |
| MIGRATE_HIGHATOMIC | 在罕见的情况下,内核需要分配一个高阶的页面块而不能休眠.如果向具有特定可移动性的列表请求分配内存失败,这种紧急情况下可从MIGRATE_HIGHATOMIC中分配内存 |
| MIGRATE_CMA | Linux内核最新的连续内存分配器(CMA), 用于避免预留大块内存 |
| MIGRATE_ISOLATE | 是一个特殊的虚拟区域, 用于跨越NUMA结点移动物理内存页. 在大型系统上, 它有益于将物理内存页移动到接近于使用该页最频繁的CPU. |
| MIGRATE_TYPES | 只是表示迁移类型的数目, 也不代表具体的区域 |
如果内核无法满足针对某一给定迁移类型的分配请求, 会怎么样?
内核在内存迁移的过程中提供了一个备用列表fallbacks, 规定了在指定列表中无法满足分配请求时. 接下来应使用哪一种迁移类型,
static int fallbacks[MIGRATE_TYPES][MIGRATE_TYPES-1] = {
[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_RESERVE },
[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_RESERVE },
[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_RESERVE },
[MIGRATE_RESERVE] = { MIGRATE_RESERVE, MIGRATE_RESERVE, MIGRATE_RESERVE }, /* Never used */
};最后,上述的内存块都是在 zonelist 中的不同 zone 的 free_area 结构中的,那么这个 free_area 结构是在什么地方初始化的呢?初始化成什么样子呢?下一张将对其进行分析。
参考文档:
https://blog.csdn.net/vanbreaker/article/details/7605367
https://blog.csdn.net/gatieme/article/details/52420444