es的基础介绍和kibana操作文档
ES的作用:
1、Elasticsearch的功能
(1)分布式的搜索引擎和数据分析引擎
(2)全文检索,结构化检索,数据分析
(3)对海量数据进行近实时的处理
2、es存储结构:
我们从es存储一个数据来分析es的结构:
{
"_index": "bankorderindex",
"_type": "bankorder",
"_id": "1254423336",
"_version": 2,
"found": true,
"_source": {
"id": 1254423336,
"orderSn": "2019073018171802610757311210N",
"realMoney": 0.02,
"payTime": 1564481844000,
"createTime": 1564481838394
}
}
index相当于我们的mysql中的数据库的database
_type相当于我们数据的表名
id:相当于我们表中的某一条主键id,也是一个唯一标识
version相当于数据的版本号,可以做乐观锁
_source相当于我们的表数据,在es存储都是json数据
3、kibana的使用
1、查看集群中有哪些索引:
GET /_cat/indices?v
2、创建索引
PUT /test_index?pretty
3、删除索引:
DELETE /test_index?pretty
4、新增文档并建立索引
语法格式为:
PUT /index/type/id
{
"json数据"
}
index指索引名、type指索引的类型、id是这条数据的id。
PUT /bankorderindex/bankorder/1254423936
{
"id": 1254423936,
"orderSn": "2019073018171802610757311291N",
"realMoney": 0.02,
"payTime": 1564481844000,
"createTime": 1564481838394
}
创建成功之后返回:

ES会自动建立index和type,不需要提前创建,而且es默认会对document每个field都建立倒排索引,让其可以被搜索。
对于查询,我们使用的是GET
GET /bankorderindex/bankorder/1254423936
查询es之后返回:
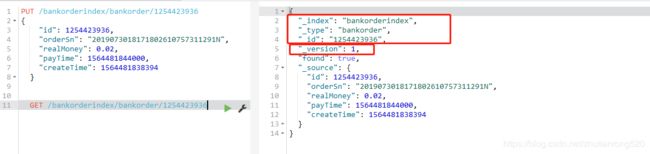
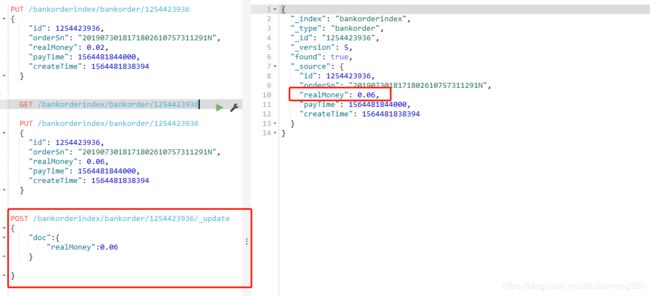
修改分为全部修改和部分修改,
全部修改就是直接替换,这种替换方式有一个不好,即使必须带上所有的field,才能去进行信息的修改
修改全部
PUT /bankorderindex/bankorder/1254423936
{
"id": 1254423936,
"orderSn": "2019073018171802610757311291N",
"realMoney": 0.06,
"payTime": 1564481844000,
"createTime": 1564481838394
}

修改部分:
POST /bankorderindex/bankorder/1254423936/_update
{
"doc":{
"realMoney":0.06
}
}
删除
直接DELETE就可以了
DELETE /bankorderindex/bankorder/1254423936
查询
GET /bankorderindex/bankorder/_search
took:耗费了几毫秒
timed_out:是否超时,这里是没有
_shards:数据拆成了5个分片,所以对于搜索请求,会打到所有的primary shard(或者是它的某个replica shard也可以)
hits.total:查询结果的数量,3个document
hits.max_score:score的含义,就是document对于一个search的相关度的匹配分数,越相关,就越匹配,分数也高
hits.hits:包含了匹配搜索的document的详细数据
query DSL
查询所有的订单:
GET /bankorderindex/bankorder/_search
{
"query": { "match_all": {} }
}
查询名称包含N的订单,同时按照价格降序排序
GET /bankorderindex/bankorder/_search
{
"query" : {
"match" : {
"orderSn" : "2019073018171802610757311271N"
}
},
"sort": [
{ "realMoney": "desc" }
]
}

分页查询订单
GET /bankorderindex/bankorder/_search
{
"query": { "match_all": {} },
"from": 1,
"size": 5
}
指定要查询出来订单号和订单金额就好
GET /bankorderindex/bankorder/_search
{
"query": { "match_all": {} },
"_source": ["orderSn", "realMoney"]
}
根据订单创建时间查询
GET /bankorderindex/bankorder/_search
{
"query":{
"range":{
"createTime":{
"from":"1564502400",
"to":"1564675200"
}
}
}
}

4、document的核心元数据
1、_index元数据
(1)代表一个document存放在哪个index中
(2)类似的数据放在一个索引,非类似的数据放不同索引:product index(包含了所有的商品),
sales index(包含了所有的商品销售数据),inventory index(包含了所有库存相关的数据)。
如果你把比如product,sales,human resource(employee),
全都放在一个大的index里面,比如说company index,不合适的。
(3)index中包含了很多类似的document:类似是什么意思,其实指的就是说,
这些document的fields很大一部分是相同的,你说你放了3个document,
每个document的fields都完全不一样,这就不是类似了,就不太适合放到一个index里面去了。
(4)索引名称必须是小写的,不能用下划线开头,不能包含逗号:product,website,blog
2、_type元数据
(1)代表document属于index中的哪个类别(type)
(2)一个索引通常会划分为多个type,逻辑上对index中有些许不同的几类数据进行分类:
因为一批相同的数据,可能有很多相同的fields,但是还是可能会有一些轻微的不同,
可能会有少数fields是不一样的,举个例子,就比如说,商品,可能划分为电子商品,
生鲜商品,日化商品,等等。
(3)type名称可以是大写或者小写,但是同时不能用下划线开头,不能包含逗号