基于深度学习的音乐推荐系统(一)音频频谱图绘制
-
采集mp3音频样本
数据量小可以直接客户端批量下载,网易云下载的是mp3格式,每天每个id下载限度300首。
数据量大写爬虫。
-
mp3音频样本转为wav格式样本
这一步涉及到python的文件路径编程,主要用到的是os库函数。
from pydub import AudioSegment
import os,sys
#单个转码
# print(sys.argv[0])
# print(os.getcwd())
# source_file_path = "E:\\毕业设计\\music\\老四叔 - 关于南方破碎的理想.mp3"
# destin_path = "./music/老四叔 - 关于南方破碎的理想.wav"
# print(source_file_path)
# sound = AudioSegment.from_mp3(source_file_path)
# sound.export(destin_path,format = 'wav')
#批量转码
#想遍历的文件夹的路径
path = r'E:/毕业设计/music/'
for files in os.listdir(path):
print(files)
source_file_path = path+files
destin_path = path+'\\wav\\'+files[:-3]+'wav'
sound = AudioSegment.from_mp3(source_file_path)
sound.export(destin_path,format='wav')
-
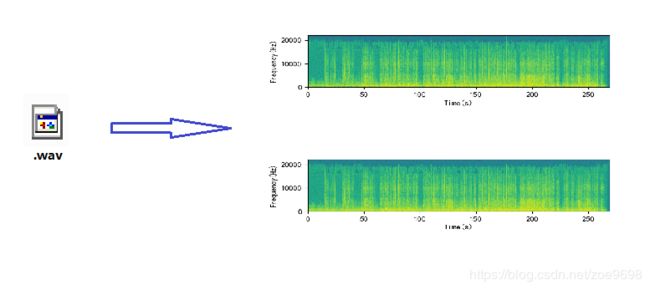
将wav音频文件绘制成音频频谱图
频谱图(语谱图):横坐标为时间(time(s)),纵坐标为频率。
更详细的音频基础知识见上文音频处理中需要用到的关于声乐的基本概念。
因为从网易云下载的音频文件转码为wav格式后,均为双声道,所以代码中将两个声道分开绘图。

注意到:
![]()
例如:12767663/44100=289.51(s)
for files in os.listdir(filepath):
print('filename:',files)
wav_path = filepath+files
pic_path = 'E:/毕业设计/pic_one/'+files[:-3]+'png'
f = wave.open(wav_path,'rb')
params = f.getparams()
nchannels,sampwidth,framerate,nframes = params[:4]
print('nchannels(声道数):',nchannels)
print('sampwidth(量化位数byte):',sampwidth)
print('framerate(采样频率):',framerate)
print('nframes(采样点数):',nframes)
strData = f.readframes(nframes)#读取音频,字符串格式
waveData = np.fromstring(strData,dtype=np.int16)#将字符串转化为int
waveData = waveData*1.0/(max(abs(waveData)))#wave幅值归一化
print('waveData:',waveData)
#多通道处理
waveData = np.reshape(waveData,[nframes,nchannels])
f.close()#关闭文件读写流
time = np.arange(0,nframes)*(1.0/framerate)
print('time:',time)
#绘图,两个声道分别画
plt.figure()
# #第一个声道
# plt.subplot(7,1,1)
# plt.plot(time,waveData[:,0])
# plt.xlabel("Time(s)")
# plt.ylabel("Amplitude")
# plt.title("Ch-1 wavedata")
# plt.grid(True)#标尺,on:有,off:无
# #第二个声道
# plt.subplot(7,1,3)
# plt.plot(time,waveData[:,1])
# plt.xlabel("Time(s)")
# plt.ylabel("Amplitude")
# plt.title("Ch-2 wavedata")
# plt.grid(True)#标尺,on:有,off:无
#频谱图(横坐标时间、纵坐标频率)
#第一声道
plt.subplot(1,1,1)
plt.specgram(waveData[:,0],Fs = framerate,scale_by_freq = True,sides='default')
#plt.ylabel('Frequency(Hz)')
#plt.xlabel('Time(s)')
# #第二声道
# plt.subplot(3,1,3)
# plt.specgram(waveData[:,1],Fs = framerate,scale_by_freq = True,sides='default')
# plt.ylabel('Frequency(Hz)')
# plt.xlabel('Time(s)')
plt.axis('off')
fig = plt.gcf()
width = nframes/framerate/10
height = 2.56
fig.set_size_inches(width,height)#输出width*height像素
plt.gca().xaxis.set_major_locator(plt.NullLocator())
plt.gca().yaxis.set_major_locator(plt.NullLocator())
plt.subplots_adjust(top=1,bottom=0,left=0,right=1,hspace =0, wspace =0)
plt.margins(0,0)
plt.savefig(pic_path)
#plt.show()
plt.close('all')#防止内存溢出
pic_cut(pic_path)
-
频谱图切割为256*256像素的子图
观察到虽然音频文件都是双声道,但是两个声道除了颜色(即音量)有细微差距,其他非常相似。
故对所有样本均取第一声道进行频谱图绘制。
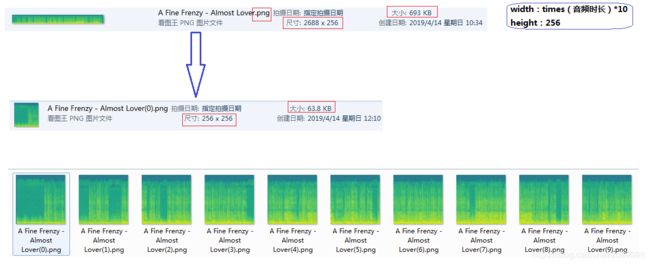
这一步涉及到Python图片切割的库函数是pillow(PIL)
关于crop()的问题,参阅
使用python PIL库裁剪和保存图像时遇到困难
Python实现图片裁剪的两种方式——Pillow和OpenCV
def pic_cut(picpath):
print('picpath:',picpath)
#将频谱图全部分割为256*256
img = Image.open(picpath)
#print(img.width/256)
for i in range(0,int(img.width/256)):
cpic_path = "E:/毕业设计/cut_pic/"+os.path.split(picpath)[1][:-4]+"("+str(i)+")"+".png"
print('cpic_path:',cpic_path)
print('int(img.width/256):',int(img.width/256))
cropped = img.crop((i*256,0,i*256+256,256))
cropped.save(cpic_path)