TensorFlow入门记录第三天
TensorFlow读取数据的方式
TensorFlow读取数据的方式有三种
1.通过占位符使用feed_dict传递数据
2.使用预加载的数据
3.从文件中读取数据
通过feed_dict传递数据或者预加载数据都比较简单,适用于数据集比较小的时候,当数据集很大的时候feed_dict会加大内存消耗降低运行速率,预加载数据会降低传输速率;最好的方法是从文件中读取数据,实现起来相对于前面两种会比较麻烦,但是效率是最高的。
**1.**通过feed_dict传递数据
num1 = tf.placeholder(tf.int32)
num2= tf.placeholder(tf.int32)
result = num1+num2
data1 = 3
data2 = 4
with tf.Session() as sess:
print(sess.run(result,feed_dict={num1:data1,num2:data2}))
这里num1和num2只是占位符,没有具体的数据,运行每个步骤的时候都要调用run()或者eval()函数中的feed_dict参数来提供生成的数据,这种方法允许传递数组数据,但是当数据集量很多时这种方法也会相对的繁琐且占用内存。
2. 通过预加载传递数据
num1 = tf.constant([1, 2, 3])
num2= tf.constant([3, 2, 1])
result = num1+num2
with tf.Session() as sess:
print(sess.run(result))
当数据集很小,可以在内存中完全加载的时候,可以通过将数据存储在常量或者变量中,当数据集很大的时候这种方法显然是不可取的。
3.通过文件读取数据
TensorFlow从文件读取数据是基于队列API构建的一个输入通道,这里需要用到TensorFlow中的 tf.train.string_input_producer ()去创建一个文件名队列,协调器 tf.train.Coordinator()和入队线程启动器 tf.train.start_queue_runners()去管理启动文件名队列,通常有以下几个步骤:
3.1.定义文件名列表
使用字符串张量 [" …","…",…] 或者使用 files=tf.train.match_filenames_once(’.JPG’) 函数创建。
3.2.定义文件名队列
使用tf.train.string_input_producer() 函数创建一个文件名队列,这里有两个比较重要的参数一个是num_epochs默认为None,这个参数是指训练集中的全部样本的训练次数;一个是shuffle默认为True,这个参数是指是否打乱文件名;
3.3.定义Reader
Reader阅读器用于读取文件名列表中的文件,根据文件的格式选择不同的阅读器,常用的有CSV文件,二进制文件,图片文件,TensorFlow标准格式文件(TFRecords)等。
CSV文件的阅读器使用:tf.TextLineReader()定义
二进制文件使用:tf.FixedLengthRecordReader()定义
图片文件使用:tf.WholeFileReader()定义
TFRecords文件使用:tf.TFRecordReader()定义。
3.4定义Decoder
Decoder解析器是将文件中的数据解码为张量,根据不同的阅读器类型定义相对应的解码器。
其中常用的有
-
CSV文件解码器:tf.decode_csv() 二进制文件解码器:tf.decode_raw() 图片文件解码器:tf.image.decode_image(), tf.image.decode_gif(),tf.image.decode_jpeg(), tf.image.decode_png() TFRecords文件文件解码器:tf.parse_single_example()。
解析器函数中有一个参数record_defaults决定解析产生的Tensor类型,当文件中的值有缺失式,可以用这个参数去指定一个默认值进行填充。
举个读取csv文件的例子:
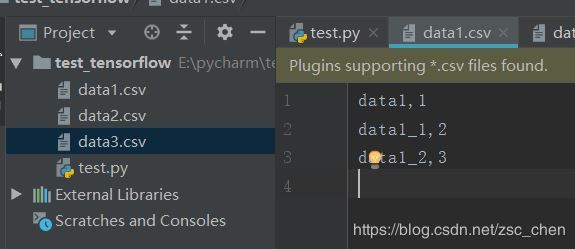
首先创建几个csv文件,内容和数量随意,这里创建了3个csv文件
# 用字符串张量创建文件名列表
filename_list = ['data1.csv', 'data2.csv', 'data3.csv']
#定义文件名队列
filename_queue = tf.train.string_input_producer(filename_list, shuffle=False)
# 定义Reader
reader = tf.TextLineReader()
#reader.read返回参数有两个,分别为key和value
key,value = reader.read(filename_queue)
# 定义Decoder
list_name, list_data = tf.decode_csv(value, record_defaults=[['no_data'], ['no_data']])
# 运行Graph
with tf.Session() as sess:
#创建线程管理协调器
coord = tf.train.Coordinator()
#开启QueueRunner,文件名进入队列
runner = tf.train.start_queue_runners(coord=coord)
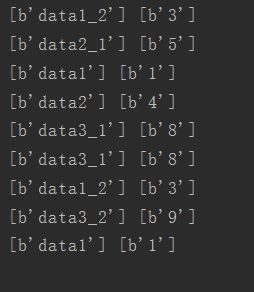
for i in range(9):
print (list_name.eval(),list_data.eval())
运行之后发现输出是乱序的,而且列表中的数值也对不上,这时候需要用到tf.train.shuffle_batch()或者tf.train.shuffle_batch()函数。
1.tf.train.batch() 按顺序读取队列中的数据
参数:
-
tensors:排列的张量或词典. batch_size:从队列中提取新的批量大小. num_threads:线程数量.若批次是不确定 num_threads > 1. capacity:队列中元素的最大数量. enqueue_many:tensors中的张量是否都是一个例子. shapes:每个示例的形状.(可选项) dynamic_pad:在输入形状中允许可变尺寸. allow_smaller_final_batch:为True时,若队列中没有足够的项目,则允许 最终批次更小.(可选项) shared_name:如果设置,则队列将在多个会话中以给定名称共享 name:操作的名称
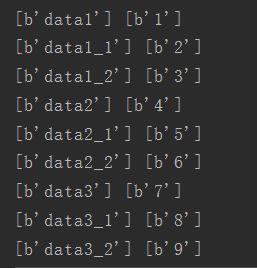
通常需要设置的为前四个,后面的根据项目的实际需要在自行设置。在代码中调用tf.train.batch() ,结果是按照列表顺序输出的,并且对应的值也是正确的
# 用字符串张量创建文件名列表
filename_list = ['data1.csv', 'data2.csv', 'data3.csv']
#定义文件名队列
filename_queue = tf.train.string_input_producer(filename_list, shuffle=False)
# 定义Reader
reader = tf.TextLineReader()
#reader.read返回参数有两个,分别为key和value
key,value = reader.read(filename_queue)
# 定义Decoder
list_name, list_data = tf.decode_csv(value, record_defaults=[['no_data'], ['no_data']])
# 按顺序读取队列中的数据
list_batch, list_batch_2 = tf.train.batch([list_name,list_data], batch_size=1, capacity=200, num_threads=2)
# 运行Graph
with tf.Session() as sess:
#创建线程管理协调器
coord = tf.train.Coordinator()
#开启QueueRunner,文件名进入队列
runner = tf.train.start_queue_runners(coord=coord)
for i in range(9):
list_1, list_2 = sess.run([list_batch, list_batch_2])
print (list_1,list_2)
coord.request_stop()
coord.join(runner)
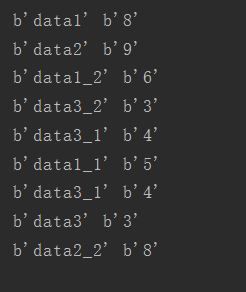
2.tf.train.shuffle_batch() 将队列中数据打乱后再读取出来
参数:
-
ensors:排列的张量或词典. batch_size:从队列中提取新的批量大小. capacity:队列中元素的最大数量. min_after_dequeue:出队后队列中元素的最小数量,用于确保元素的混 合级别. num_threads:线程数量. seed:队列内随机乱序的种子值. enqueue_many:tensors中的张量是否都是一个例子. shapes:每个示例的形状 allow_smaller_final_batch:为True时,若队列中没有足够的项目,则允许最终批次更小 shared_name:如果设置,则队列将在多个会话中以给定名称共享. name:操作的名称
通常需要设置的为前五个,后面的根据项目的实际需要在自行设置。在代码中调用tf.train.shuffle_batch() ,结果是乱序输出的,但对应的值是正确的
# 用字符串张量创建文件名列表
filename_list = ['data1.csv', 'data2.csv', 'data3.csv']
#定义文件名队列
filename_queue = tf.train.string_input_producer(filename_list, shuffle=False)
# 定义Reader
reader = tf.TextLineReader()
#reader.read返回参数有两个,分别为key和value
key,value = reader.read(filename_queue)
# 定义Decoder
list_name, list_data = tf.decode_csv(value, record_defaults=[['no_data'], ['no_data']])
# 将队列中的数据乱序读出
list_batch, list_batch_2 = tf.train.shuffle_batch([list_name,list_data], batch_size=1, capacity=200, min_after_dequeue=100,num_threads=2)
# 运行Graph
with tf.Session() as sess:
#创建线程管理协调器
coord = tf.train.Coordinator()
#开启QueueRunner,文件名进入队列
runner = tf.train.start_queue_runners(coord=coord)
for i in range(9):
list_1, list_2 = sess.run([list_batch, list_batch_2])
print (list_1,list_2)
coord.request_stop()
coord.join(runner)