以太坊存储分析(整合)
- 分析背景及概述
更加深入地了解以太坊的内部存储机制,更好地实现自己的区块链,存储是一个不能缺少的模块。但是存储又不是单一的数据保存,它涉及到了以太坊核心的编码、数据结构,中间还有缓存的部分,最后才通过leveldb(一种key-value数据库)保存到硬盘上。其中以太坊实现的代码十分精巧,设计同时考虑效率与优雅的问题,所以有些地方不那么好理解;加上以太坊的源码和结构不断更新,有一些参考资料只能作为参考,最权威的还是以太坊黄皮书,但是理论太多,涉及到一些难懂的数理描述。
以太坊数据存储布局

以太坊MPT结构

- 相关数据编码格式
1)RLP
RLP(Recursive Length Prefix)编码是以太坊中数据序列化的一个主要编码方式,可以将任意的嵌套二进制数据进行序列化。以太坊中针对RLP的编码规则定义如下:
1. 如果是一个单字节并且其值在[0x00,0x7f]范围内,RLP编码就是自身。
- 否则,如果一个数据串的字节长度是0-55字节,那么它的RLP编码是在数据串开头增加一个字节,这个字节的值是0x80加上数据串的字节长度。因此增加的该字节的取值范围为[0x80, 0xb7]。
3. 如果一个数据串的字节长度大于55,那么它的RLP编码是在开头增加一个字节,这个字节的值等于0xb7加上数据串字节长度的二进制编码的字节长度,然后依次跟着数据串字节长度部分和内容部分。比如:一个长度为1024字节的数据串,其字节长度用16进制表示为0x0400,长度为2个字节,因此RLP编码头字节的值为0xb9(0xb7 + 0x02),然后跟着两字节为0x0400,后面再加上数据串的具体内容。因此增加的首字节的取值范围为[0xb8, 0xbf],因此其能编码的最大数据长度为2^56。
4. 如果是一个嵌套的列表数据,则需要先将列表中的数据按照单元素的编码规则进行RLP编码后串联得到列表数据的payload。如果一个列表数据的payload的字节长度为0-55,那么列表的RLP编码在其payload前加上一个字节,这个字节的值是0xc0加上payload的字节长度。因此首字节的取值范围为[0xc0, 0xf7]。
5. 如果一个列表数据的payload的长度大于55,那么它的RLP编码是在开头增加一个字节,这个字节的值等于0xf7加上列表payload字节长度的二进制编码的字节长度,然后依次跟着payload字节长度部分和payload部分。因此首字节的取值范围为[0xf8, 0xff],因此一个列表中存储的所有元素的字节长度不能超过2^56。
如下是一些RLP编码的参考样例。
原始数据
编码数据
'a'
0x61
1000
0x8203E8
"abc"
0x83616263
"123456789012345678901234567890123456789012345678901234567890"
0xB83C313233343536373839303132333435363738393031323334353637383930313233343536373839303132333435363738393031323334353637383930
""
0x80
[0,1,2,3]
0xC400010203
["abc","def","ghi"]
0xCC836162638364656683676869
["abc","def","ghi","123456789012345678901234567890123456789012345678901234567890"]
0xF89486162638364656683676869B83C313233343536373839303132333435363738393031323334353637383930313233343536373839303132333435363738393031323334353637383930
[]
0xC0
注意:1000为以太坊整数 以太坊整数256bit 256/8 = 32 (byte)
2)hex prefix编码


可以看出编码方式很简单,重点是理解其中各符合的定义:x是一个nibble(半字节,在计算机中,通常将8位二进制数称为字节,而把4位二进制数称为半字节)数组,t是标志位,用以标志节点类型。
为什么要进行编码?
在以太坊协议中,不管是地址还是hash,都是一个16进制串,如"0x5b3edbcf7d0a97e95e57a4554a29ea66601b71ad",数据最小的表示单位为一位16进制,2^4=16,用4bit可以表示十六进制所有数字(个人根据上下文理解加上去的,别人没解释这一句),如1、a等,但在编程实现中,数据的最小表示单位往往是byte(8bit,2位16进制数),这样在用byte来表示一串奇数长度的16进制串时会出现问题,如"5b3"和"5b30",直接转成byte都是5b30。还有一种简单直观的转换方式,"5b3"->"050b03",这种方式虽然简单,但是数据量会翻倍,不利于大量hash的计算,同时也会增加tree的大小,降低同步性能。Hex-Prefix Encoding能解决这些问题。
下面举个具体例子说明编码过程:
对"0x5b3ed"编码(奇数位)
"0x5b3ed" = "0005 1011 0003 1110 1101"
t=0 时, "0001"+"0005 1011 0003 1110 1101"->"00010005 10110003 11101101"->"0x15b3ed"
t !=0时 "0011"+"0005 1011 0003 1110 1101"->"00110005 10110003 11101101"->"0x35b3ed"
对"0x5b3e"编码(偶数位)
"0x5b3e" = "0005 1011 0003 1110"
t=0 时, "0000"+"0005 1011 0003 1110 1101"->"00000005 10110003 11101101"->"0x005b3e"
t !=0时 "0010"+"0005 1011 0003 1110 1101"->"00100005 10110003 11101101"->"0x205b3e"
t=0与t!=0实际用处, t=0是其实是针对拓展节点,t!=0其实是针对叶子节点


odd 奇数 even 偶数
- 数据结构
Block
type Block struct {
header *Header //区块头
uncles []*Header //叔节点
transactions Transactions //交易数组
hash atomic.Value
size atomic.Value
td *big.Int //所有区块Difficulty之和
ReceivedAt time.Time
ReceivedFrom interface{}
}
Block(区块)是Ethereum的核心数据结构之一。所有账户的相关活动,以交易(Transaction)的格式存储,每个Block有一个交易对象的列表;每个交易的执行结果,由一个Receipt对象与其包含的一组Log对象记录;所有交易执行完后生成的Receipt列表,存储在Block中(经过压缩加密)。不同Block之间,通过前向指针ParentHash一个一个串联起来成为一个单向链表,BlockChain 结构体管理着这个链表。
Block结构体基本可分为Header和Body两个部分,其UML关系族如下图所示:

Header
type Header struct {
ParentHash common.Hash //指向父区块的指针
UncleHash common.Hash //block中叔块数组的RLP哈希值
Coinbase common.Address //挖出该区块的人的地址
Root common.Hash //StateDB中的stat trie的根节点的RLP哈希值
TxHash common.Hash //tx trie的根节点的哈希值
ReceiptHash common.Hash //receipt trie的根节点的哈希值
Bloom Bloom //布隆过滤器,用来判断Log对象是否存在
Difficulty *big.Int //难度系数
Number *big.Int //区块序号
GasLimit uint64 //区块内所有Gas消耗的理论上限
GasUsed uint64 //区块内消耗的总Gas
Time *big.Int //区块应该被创建的时间
Nonce BlockNonce //挖矿必须的值
}
Header是Block的核心,注意到它的成员变量全都是公共的,这使得它可以很方便的向调用者提供关于Block属性的操作。Header的成员变量全都很重要,值得细细理解:
ParentHash:指向父区块(parentBlock)的指针。除了创世块(Genesis Block)外,每个区块有且只有一个父区块。
Coinbase:挖掘出这个区块的作者地址。在每次执行交易时系统会给与一定补偿的Ether,这笔金额就是发给这个地址的。
UncleHash:Block结构体的成员uncles的RLP哈希值。uncles是一个Header数组,它的存在,颇具匠心。
Root:StateDB中的“state Trie”的根节点的RLP哈希值。Block中,每个账户以stateObject对象表示,账户以Address为唯一标示,其信息在相关交易(Transaction)的执行中被修改。所有账户对象可以逐个插入一个Merkle-PatricaTrie(MPT)结构里,形成“state Trie”。
TxHash: Block中 “tx Trie”的根节点的RLP哈希值。Block的成员变量transactions中所有的tx对象,被逐个插入一个MPT结构,形成“tx Trie”。
ReceiptHash:Block中的 "Receipt Trie”的根节点的RLP哈希值。Block的所有Transaction执行完后会生成一个Receipt数组,这个数组中的所有Receipt被逐个插入一个MPT结构中,形成"Receipt Trie"。
Bloom:Bloom过滤器(Filter),用来快速判断一个参数Log对象是否存在于一组已知的Log集合中。
Difficulty:区块的难度。Block的Difficulty由共识算法基于parentBlock的Time和Difficulty计算得出,它会应用在区块的‘挖掘’阶段。
Number:区块的序号。Block的Number等于其父区块Number +1。
Time:区块“应该”被创建的时间。由共识算法确定,一般来说,要么等于parentBlock.Time + 10s,要么等于当前系统时间。
GasLimit:区块内所有Gas消耗的理论上限。该数值在区块创建时设置,与父区块有关。具体来说,根据父区块的GasUsed同GasLimit * 2/3的大小关系来计算得出。
GasUsed:区块内所有Transaction执行时所实际消耗的Gas总和。
Nonce:一个64bit的哈希数,它被应用在区块的"挖掘"阶段,并且在使用中会被修改。
Body
type Body struct {
Transactions []*Transaction //交易的数组
Uncles []*Header
}
里面主要是交易对象和叔块位置
HeaderChain
Header的链表
BlockChain
Block的链表
要介绍MPT树,先要提一下Merkle Tree,通常也被称作Hash Tree,顾名思义,就是存储hash值的一棵树。
它可以是多叉树

但是比特币中使用的是类似下图的二叉树


如果要验证slice2数据的正确性,只需要拿到hash1, h12, h02这3个hash再加上本地存储的root hash,就可以验证了。需要传输的hash数据量从n变为log2n。
总结,Merkle root(包含在区块头里)是从可信渠道下载的(主链或者可信节点),接收到数据及这个数据对应的Merkle验证路径即可验证该数据的正确性。
但是MPT树的Hash Root貌似不像二叉树那么直观(还没完全从以太坊源码中理解)。
MPT节点有个flag字段,flag.hash会保存该节点采用merkle tree类似算法生成的hash,同时会将hash和源数据以

这样一个结构的核心思想是:hash可以还原出节点上的数据,这样只需要保存一个root(hash),即可还原出完整的树结构,同时还可以按需展开节点数据,比如如果只需要访问

trie树介绍

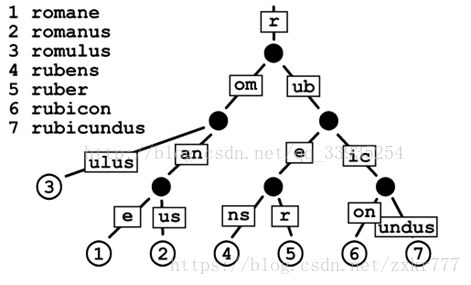
传统的tire,C++实现范例
/**
* 字典树/前缀树Tire
*/
#include
#include
using namespace std;
const int branchNum = 26; //26个英文字母
struct TrieNode
{
bool isStr;
TrieNode *next[branchNum];
};
void Insert(TrieNode *root, const char *word);
bool Search(TrieNode *root, const char *word);
void Delete(TrieNode *node);
int main()
{
TrieNode *root = new TrieNode();
root->isStr = false;
memset(root->next, NULL, sizeof(root->next)); //作用是在一段内存块中填充某个给定的值,它是对较大的结构体或数组进行清零操作的一种最快方法
Insert(root, "a");
Insert(root, "bcd");
Insert(root, "xyz");
Insert(root, "abcdef");
if (Search(root, "a"))
{
cout << "a exist" << endl;
}
Delete(root);
system("pause");
}
void Insert(TrieNode *root, const char *word)
{
TrieNode *location = root;
while (*word)
{
if (location->next[*word - 'a'] == NULL)
{
TrieNode *newNode = new TrieNode();
newNode->isStr = false;
memset(newNode->next, NULL, sizeof(newNode->next));
location->next[*word - 'a'] = newNode;
}
location = location->next[*word - 'a'];
word++;
}
location->isStr = true;
}
bool Search(TrieNode *root, const char *word)
{
TrieNode *location = root;
while (*word && location != NULL)
{
location = location->next[*word - 'a'];
word++;
}
return (location != NULL && location->isStr);
}
void Delete(TrieNode *location)
{
for (int i = 0; i < branchNum; i++)
{
if (location->next[i] != NULL)
{
Delete(location->next[i]);
}
}
delete location;
} 以太坊的MPT树是基于Trie改进而来的,做了很多优化,我们平时的字典树可能是26个字母,以太坊的是长度为17的数组,0 1 2 3 4 5 6 7 8 9 a b c d e f(十六进制的十六位)+ 拓展数据(根据节点的性质功能不一样);以太坊增加了两个新的节点,称为叶节点和扩展节点,两个节点的形式一样,都是一个[key,value]的组合,原来的节点称为分支节点。
Merkle Patricia Tree有4种类型的节点:
叶子节点(leaf),表示为[key,value]的一个键值对。和前面的英文字母key不一样,这里的key都是16编码出来的字符串,每个字符只有0-f 16种,value是RLP编码的数据
扩展节点(extension),也是[key,value]的一个键值对,但是这里的value是其他节点的hash值,通过hash链接到其他节点
分支节点(branch),因为MPT树中的key被编码成一种特殊的16进制的表示,再加上最后的value,所以分支节点是一个长度为17的list,前16个元素对应着key中的16个可能的十六进制字符,如果有一个[key,value]对在这个分支节点终止,最后一个元素代表一个值,即分支节点既可以搜索路径的终止也可以是路径的中间节点。分支节点的父亲必然是extension node
空节点,代码中用null表示
直接看代码不好说清楚,还是用一个例子解释
Suppose we want a trie containing four path/value pairs ('do', 'verb'), ('dog', 'puppy'), ('doge', 'coin'), ('horse', 'stallion').
First, we convert both paths and values to bytes. Below, actual byte representations for paths are denoted by <>, although values are still shown as strings, denoted by '', for easier comprehension (they, too, would actually be bytes):
<64 6f> : 'verb'
<64 6f 67> : 'puppy'
<64 6f 67 65> : 'coin'
<68 6f 72 73 65> : 'stallion'
Now, we build such a trie with the following key/value pairs in the underlying DB:
rootHash: [ <16>, hashA ]
hashA: [ <>, <>, <>, <>, hashB, <>, <>, <>, hashC, <>, <>, <>, <>, <>, <>, <>, <> ]
hashC: [ <20 6f 72 73 65>, 'stallion' ]
hashB: [ <00 6f>, hashD ]
hashD: [ <>, <>, <>, <>, <>, <>, hashE, <>, <>, <>, <>, <>, <>, <>, <>, <>, 'verb' ]
hashE: [ <17>, hashF ]
hashF: [ <>, <>, <>, <>, <>, <>, hashG, <>, <>, <>, <>, <>, <>, <>, <>, <>, 'puppy' ]
hashG: [ <35>, 'coin' ]
transaction tree(交易树)
state tree(状态树 主要是Account信息)
receipt tree (收据树)
附:跟存储分析相关的源码(version: 1.8.11-stable)
core/state/statedb.go
core/state/database.go
ethdb/interface.go 定义了数据库的接口(key-value接口)
ethdb/memory_database.go 内存数据库
ethdb/database.go leveldb封装
tire/tire.go
tire/trie_test.go (看测试用例是很好的学习方式)
core/headerchain.go
core/rawdb/accessors_chain.go
- 数据库体系
一些常见的键值对(header和body)
| key |
value |
|---|---|
| 'h' + num + hash |
header's RLP raw data |
| 'h' + num + hash + 't' |
td |
| 'h' + num + 'n' |
hash |
| 'H' + hash |
num |
| 'b' + num + hash |
body's RLP raw data |
| 'r' + num + hash |
receipts RLP |
| 'l' + hash |
tx/receipt lookup metadata |
| "LastHeader" |
hash |
| "LastBlock" |
hash |
| "LastFast" |
hash |
数据库体系UML

附录:levelDB官方网站介绍的特点
特点:
key和value都是任意长度的字节数组;
entry(即一条K-V记录)默认是按照key的字典顺序存储的,当然开发者也可以重载这个排序函数;
提供的基本操作接口:Put()、Delete()、Get()、Batch();
支持批量操作以原子操作进行;
可以创建数据全景的snapshot(快照),并允许在快照中查找数据;
可以通过前向(或后向)迭代器遍历数据(迭代器会隐含的创建一个snapshot);
自动使用Snappy压缩数据;
可移植性;
限制:
非关系型数据模型(NoSQL),不支持sql语句,也不支持索引;
一次只允许一个进程访问一个特定的数据库;
没有内置的C/S架构,但开发者可以使用LevelDB库自己封装一个server。
Leveldb是一个key-value数据库,所以用法上还是比较简单的;有一点要注意的是,以太坊的分片版本还没上线,因为MPT的特性,海量数据存储账户的更新操作会带来指数级的数据存取,现阶段存储还是问题。
- 有待深入研究
- 以太坊Tire树(MPT)在插入的过程中怎么缓存、计算hash
- Merkle state transition proof
- 交易存储分析
- 参考
- https://github.com/ZtesoftCS/go-ethereum-code-analysis
- https://blog.csdn.net/weixin_41545330/article/details/79394153
- https://blog.csdn.net/qq_33935254/article/details/55505472
- https://ethfans.org/hpcoder/articles/961
- https://blog.csdn.net/Blockchain_lemon/article/details/79308137
- https://blog.csdn.net/itleaks/article/details/79992072
- https://github.com/ethereum/wiki/wiki/Patricia-Tree
- http://www.cnblogs.com/fengzhiwu/p/5584809.html
- https://blog.csdn.net/wsyw126/article/details/61416055