ElasticSearch 极简教程
引子
lucene、solr、nutch、elasticSearch、LogStash、Kibana.
lucene是一个文档索引、检索框架。
solr是一个基于lucene的搜索服务,目的就是要搞一个搜索引擎,提供- http服务,支持json、xml、csv、二进制流等格式的输入输出。
nutch用于建立web搜索引擎,包括爬虫和全文搜索。
平时我们在 GitHub 上进行搜索的时候,Github 不仅可以帮我们找到相隔的代码产库,还可以帮助实现代码级的搜索及搜索词的高亮的显示,。当你在网上购物的时候,它也可以帮助你做商品的推荐。当你下班的时候,Elasticsearch 可以帮助你定位附件的乘客和司机,帮助平台优化调度,除了搜索,结合 Kibana、Logstash、Beats 的 ELK(Elastic Stack) 还被广泛使用在大数据近实时分析的领域,包括了日志分析、指标监控、信息安全等多个领域,它可以帮助你探索海量的、结构化的、非结构化的数据,按需创建是可视化报表,对监控数据设置报警阀值。
ELK
ElasticSearch:也是基于lucene的,搞索引、搜索和统计。
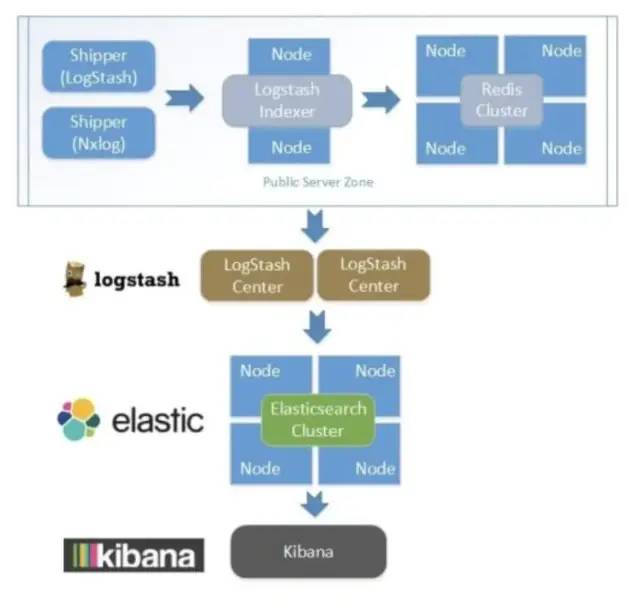
logstash主要是搜集,解析和转换日志,把各种格式转换成固定格式,方便es等软件去分析。
Kibana主要用于展示,提供了图标、表格、地图等组件
从用途上来划分,从下至上可以分为采集层、服务层、展示层:


ElasticSearch 简介
ElasticSearch 是一个分布式、RESTful 风格的搜索和数据分析引擎。
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
ElasticSearch 架构
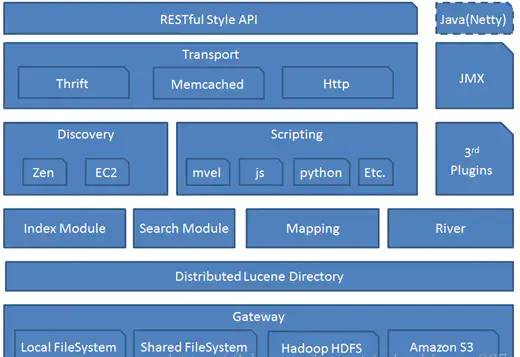
应用架构:
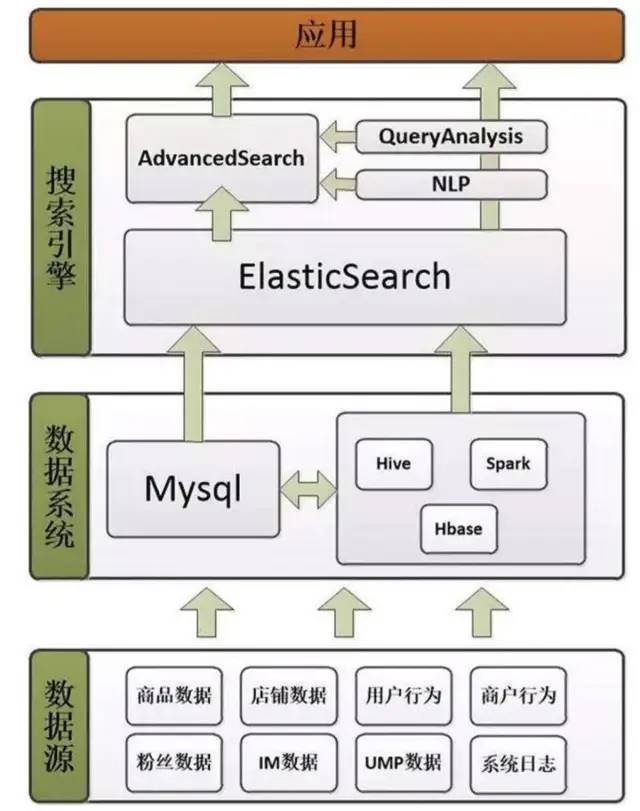
Elasticsearch分布式集群
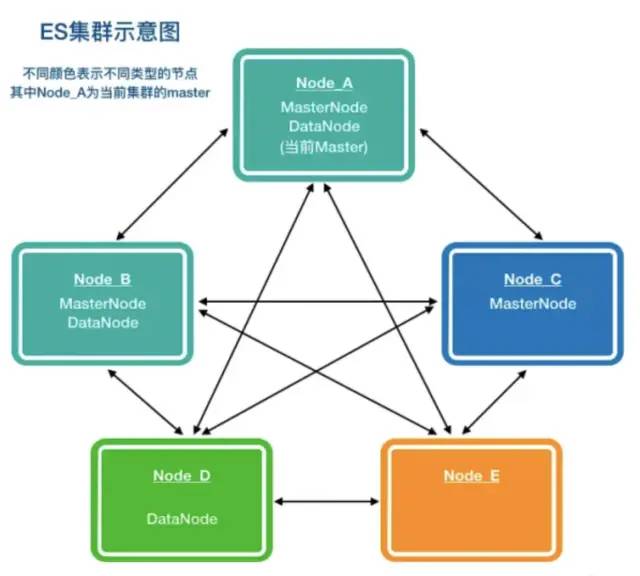
在 Elasticsearch(下称 ES)集群中有两个主要角色:Master Node 和 Data Node,其他如 Tribe Node 等节点可根据业务需要设立。
Master Nodes
Master Node,整个集群的管理者,负有对 index 的管理、shards 的分配,以及整个集群拓扑信息的管理等功能。
众所周知,Master Node 可以通过 Data Node 兼任,但是,如果对群集规模和稳定要求很高的话,就要职责分离,Master Node 推荐独立,它的状态关乎整个集群的存活。
Elasticsearch 基本概念
要了解 Elasticsearch ,首先要先了解下面的几个专有名词,索引(Index)、文档( Document)、类型(Type).
索引(Index)
Index 一索引是文档的容器,是一类文档的结合
Index 体现了逻辑空间的概念:每个索引都有自己的 Mapping,用于定义包含的文档的字段名和字段类型
Shard 体现了物理空间的概念:索引中的数据分散在 Shard 上
索引的 Mapping 与 Settings
Mapping 定义文档字段的类型
Setting 定义不同的数据分布
索引有不同语义,在 ES 中指的是在集群中创建的索引(名词),也可以指的是文档到 ES 的过程(动词),即是一次倒排索引的过程。而在其他地方看到索引更多表示 B 树索引或者倒排索引。
文档( Document)
Elasticsearch 是面向文档的,文档是所有可搜索数据的最小单位
日志文件中的日志项
一本电影的具体信息
一首歌的详细信息
文档会被序列化成 JSON 格式,保存在 Elasticsearch 中
JSON 对象由字段组成,
每个字段都有对应的字段类型(字符串/数值/布尔/日期/二进制/范围类型)
每个文档都有一个 Unique ID
可以自己指定 ID 或者通过 Elasticsearch 自动生成
类型(Types)
ElasticSearch与大数据
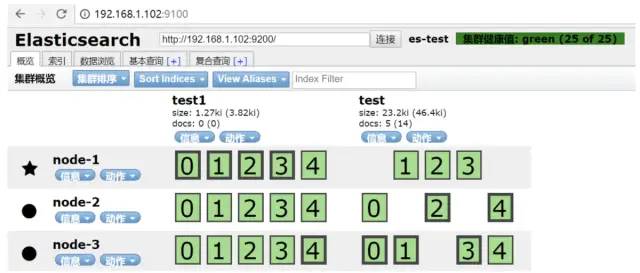
1. 海量数据组合条件查询
2. 毫秒级或者秒级返回数据
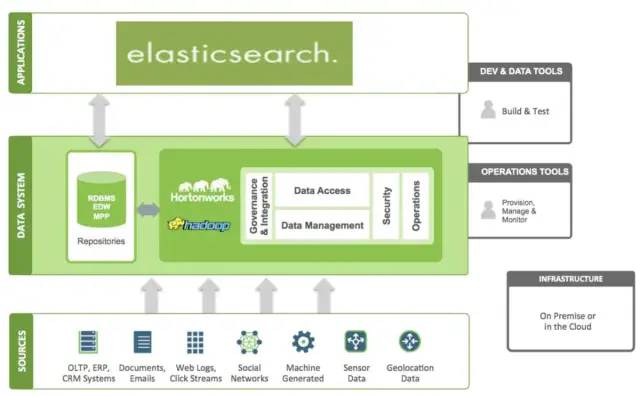
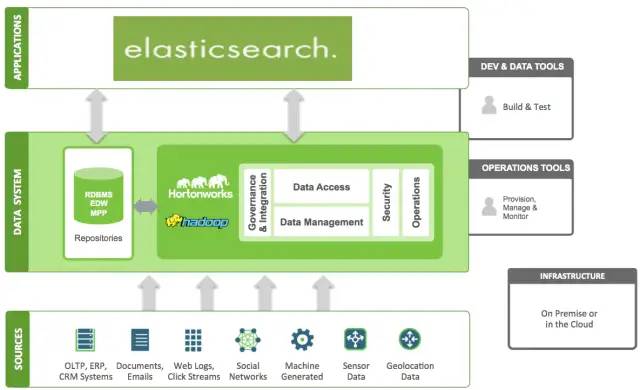
ElasticSearch 在Hadoop生态圈的位置
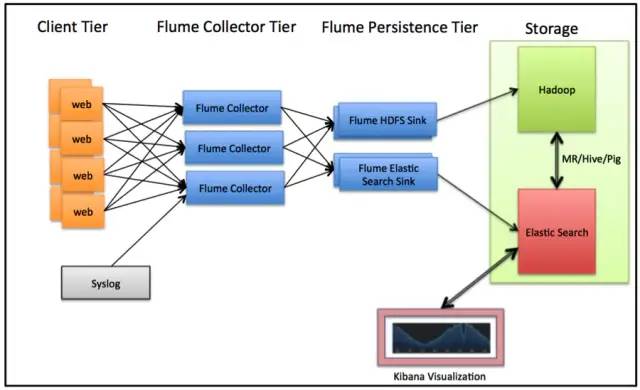
ElasticSearch 应用场景
1. 站内搜索:主要和 Solr 竞争,属于后起之秀
2. NoSQL Json文档数据库:主要抢占 Mongo 的市场,它在读写性能上优于 Mongo ,同时也支持地理位置查询,还方便地理位置和文本混合查询。
3. 监控:统计、日志类时间序的数据存储和分析、可视化,这方面是引领者
4. 国外:Wikipedia(维基百科)使用 ES 提供全文搜索并高亮关键字、Stack Overflow(IT问答网站)结合全文搜索与地理位置查询、Github使用Elasticsearch检索1300亿行的代码
5. 国内:百度(在云分析、网盟、预测、文库、钱包、风控等业务上都应用了ES,单集群每天导入30TB+数据,总共每天60TB+)、新浪 、阿里巴巴、腾讯等公司均有对ES的使用
6. 使用比较广泛的平台ELK(ElasticSearch, Logstash, Kibana)
ElasticSearch vs Solr
Solr 定义:Solr是Apache 下的一个开源项目,使用Java基于Lucene开发的全文检索服务是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
ElasticSearch vs Solr 优缺点
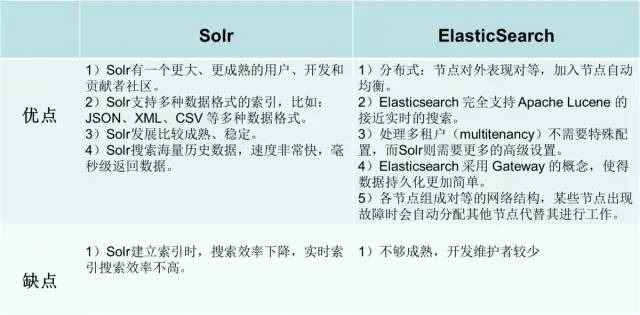
ElasticSearch vs Solr 检索速度
当单纯的对已有数据进行搜索时,Solr更快。
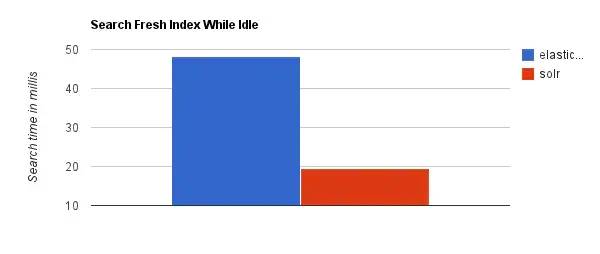
当实时建立索引时, Solr会产生io阻塞,查询性能较差, Elasticsearch具有明显的优势。
ElasticSearch vs Solr 总结
1. 二者安装都很简单。
2. Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能。
3. Solr 支持更多格式的数据,比如JSON、XML、CSV,而 Elasticsearch 仅支持json文件格式。
4. Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供
5. Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch。
6. Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用。
ElasticSearch vs 关系型数据库RDBMS
下面是 RDBMS 和 Elasticsearch 一个不是很恰当类比,Elasticsearch 集群可以包含多个索引 Indes(数据库),每一个索引可以包含一个doc类型 Type(表),每一个类型包含多个文档 Document(记录),然后每个文档包含多个字段 Fields(列),DSL 相当于 RDBMS 的 SQL。
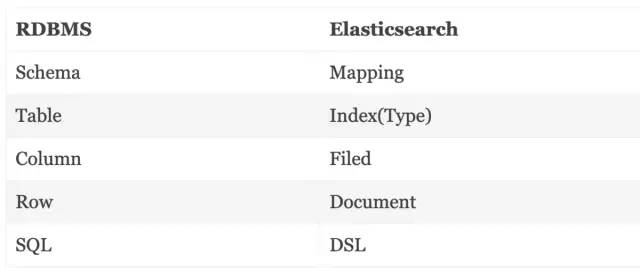
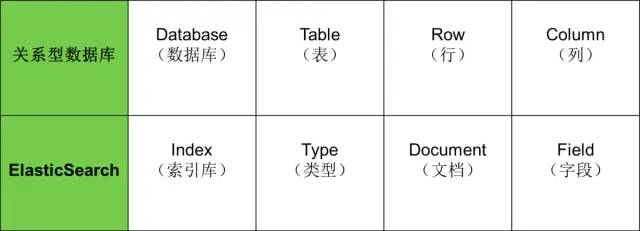
与传统 SQL 数据库管理系统(其花费10秒钟以上的时间来获取所需的搜索查询数据)相比,Elasticsearch 可以在10毫秒内完成此操作。由于 Elasticsearch 具有分布式架构,因此它可以扩展到数千个服务器并容纳PB级的数据。我们不必管理分布式设计的复杂性,因为 ES 已经自动完成。我们有多种方法可以为一些文档建立索引或查询它们,然而在使用 ES 下,我们可以轻松实现在海量数据快速检索全文,得到我们想要的结果。
下面将介绍Elasticsearch的安装与简单使用。
安装并运行Elasticsearch
安装 Elasticsearch 之前,你需要先安装一个较新版本的 Java,最好的选择是,你可以从 www.java.com 获得官方提供的最新版本的Java。
你可以从 elastic 的官网 elastic.co/downloads/elasticsearch 获取最新版本的Elasticsearch。解压文档后,按照下面的操作,即可在前台(foregroud)启动 Elasticsearch:
cd elasticsearch-
./bin/elasticsearch
此时,Elasticsearch运行在本地的9200端口,在浏览器中输入网址“http://localhost:9200/”,如果看到以下信息就说明你的电脑已成功安装Elasticsearch:
{
"name" : "YTK8L4q",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "hB2CZPlvSJavhJxx85fUqQ",
"version" : {
"number" : "6.5.4",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "d2ef93d",
"build_date" : "2018-12-17T21:17:40.758843Z",
"build_snapshot" : false,
"lucene_version" : "7.5.0",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
在这里,我们安装的Elasticsearch版本号为6.5.4。
Kibana 是一个开源的分析和可视化平台,旨在与 Elasticsearch 合作。Kibana 提供搜索、查看和与存储在 Elasticsearch 索引中的数据进行交互的功能。开发者或运维人员可以轻松地执行高级数据分析,并在各种图表、表格和地图中可视化数据。
你可以从 elastic 的官网 https://www.elastic.co/downloads/kibana 获取最新版本的Kibana。解压文档后,按照下面的操作,即可在前台(foregroud)启动Kibana:
cd kibana-
./bin/kabana
此时,Kibana运行在本地的5601端口,在浏览器中输入网址“http://localhost:5601”,即可看到以下界面:
参考资料
https://www.cnblogs.com/wwwggg/p/5588698.html
https://www.cnblogs.com/rodge-run/p/6551152.html
https://www.jianshu.com/p/1dc661517ab3
https://www.jianshu.com/p/9ce30e154d2f
https://www.jianshu.com/p/d48c32423789
https://www.jianshu.com/p/366d9bd38d14
Kotlin开发者社区

专注分享 Java、 Kotlin、Spring/Spring Boot、MySQL、redis、neo4j、NoSQL、Android、JavaScript、React、Node、函数式编程、编程思想、"高可用,高性能,高实时"大型分布式系统架构设计主题。
High availability, high performance, high real-time large-scale distributed system architecture design。
分布式框架:Zookeeper、分布式中间件框架等
分布式存储:GridFS、FastDFS、TFS、MemCache、redis等
分布式数据库:Cobar、tddl、Amoeba、Mycat
云计算、大数据、AI算法
虚拟化、云原生技术
分布式计算框架:MapReduce、Hadoop、Storm、Flink等
分布式通信机制:Dubbo、RPC调用、共享远程数据、消息队列等
消息队列MQ:Kafka、MetaQ,RocketMQ
怎样打造高可用系统:基于硬件、软件中间件、系统架构等一些典型方案的实现:HAProxy、基于Corosync+Pacemaker的高可用集群套件中间件系统
Mycat架构分布式演进
大数据Join背后的难题:数据、网络、内存和计算能力的矛盾和调和
Java分布式系统中的高性能难题:AIO,NIO,Netty还是自己开发框架?
高性能事件派发机制:线程池模型、Disruptor模型等等。。。
合抱之木,生于毫末;九层之台,起于垒土;千里之行,始于足下。不积跬步,无以至千里;不积小流,无以成江河。