听说你想爬点壁(mei)纸图
面向小白的基础教程,无法再基础了,里面的原理一些名词,原理写的也比较详细,虽然可能看了还不太懂,但肯定能让你实战应用。


首先导入我们需要的模块
import requests # requests是python实现的最简单易用的HTTP库
import re #regular expression,正则表达式,是用来简洁表达一组字符串特征的表达式。最主要应用在字符串匹配中。
import os #os库提供通用的,基本的操作系统交互功能(windows,mac os,linux)
找网站的网址和User-Agent
为什么要使用User Agent?
因为一些网站不喜欢外界的爬虫消耗自己的服务器的大量资源,因此他自身就写了一个反爬虫程序,不使用代理的话,他们就能识别出你是爬虫,从而给你进行重定向无数次,导致你的爬虫报错.
User-Agent其实就是你的浏览器信息。是一种向访问网站提供你所使用的浏览器类型及版本、操作系统及版本、浏览器内核、等信息的标识。通过这个标 识,用户所访问的网站可以显示不同的排版从而为用户提供更好的体验或者进行信息统计;
-
一般网站都有反爬虫机制,所以我们要对我们的爬虫进行伪装,应该先去该网址找到他的请求头,也就是他的User-Agent
-
请求头:右键单击然后点检查,然后按步骤找请求头
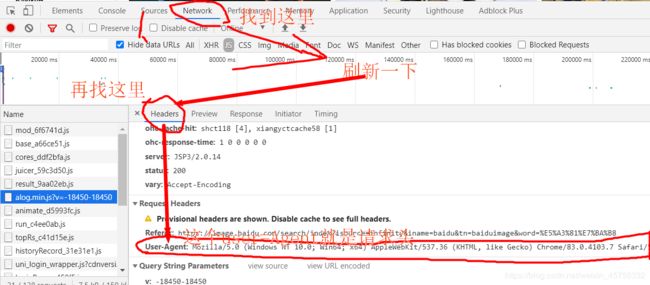
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.7 Safari/537.36'}
- 设置我们需要爬取的网页url,也就是这个网址

url='https://image.baidu.com/search/index?isource=infinity&iname=baidu&tn=baiduimage&word=%E5%A3%81%E7%BA%B8'
获取单张图片的url,并保存图片
- 首先找到单张图片的URL
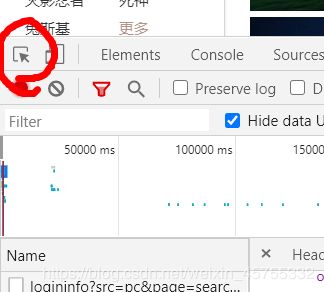
找张图片单击一下
每往下滑动滑轮就Name那一栏就会出现新的内容,下面的数字是0—30的,也就是相当于每一页有三十张图片。

可以看到多了很多,点开右面的每个图片的json信息,比如时间,内容,最关键的有这张图片的URL地址
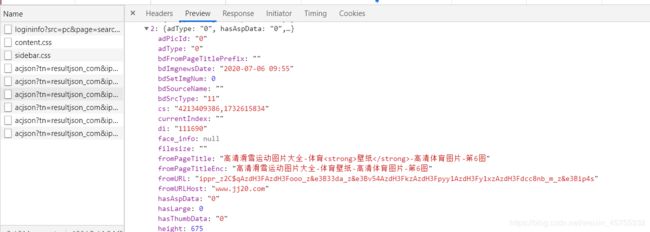
这个就是这张图片的网址,可以复制下打开看看。

可以看到是个美女壁纸

通过正则表达式来提取每张图片的url
- requests.get(url,headers) 构造一个向服务器请求资源的url对象,加headers是为了应对反爬虫机制
- response.content.decode(‘utf-8’) 对网页解码,utf-8 是针对Unicode的一种可变长度字符编码。它可以用来表示Unicode标准中的任何字符
- re.findall(’“thumbURL”:"(.*?)"’,content,re.S) 找到content这个网址的thumbURL匹配的内容
1、. 匹配任意除换行符“\n”外的字符;
2、表示匹配前一个字符0次或无限次;
3、?表示前边字符的0次或1次重复
4、 .? 表示匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。
如:a.*?b匹配最短的,以a开始,以b结束的字符串。如果把它应用于aabab的话,它会匹配aab和ab。
#获取单张图片的url,并保存图片
def get_img(url):
#获取到这个网页,并对其解码
response=requests.get(url,headers)
content=response.content.decode('utf-8')
#正则表达式来查找这个content网址的thumbURL里面的内容,也就是图片的网址
#re.S如果不设置的话就会进行单行匹配,也就是可能无法找到所有内容
img_urls=re.findall('"thumbURL":"(.*?)"',content,re.S)
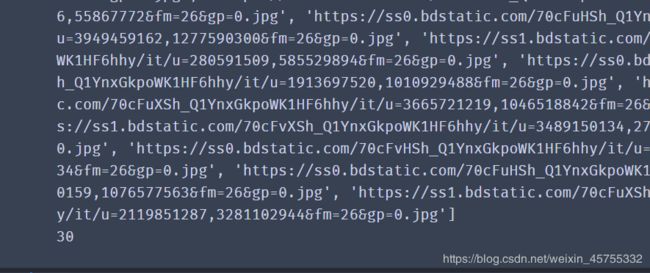
print(img_urls)
print(len(img_urls))
get_img(url)
下面就是匹配到的图片的地址,但他的数量是有限的,可以看到只有30张图片的地址
图片的保存
先来保存这三十张照片,用二进制的格式保存,并对其命名为1-n
#获取单张图片的url,并保存图片
def get_img(url):
#获取到这个网页,并对其解码
response=requests.get(url,headers)
content=response.content.decode('utf-8')
#正则表达式来查找这个content网址的thumbURL里面的内容,也就是图片的网址
#re.S如果不设置的话就会进行单行匹配,也就是可能无法找到所有内容
img_urls=re.findall('"thumbURL":"(.*?)"',content,re.S)
#***********************************************
#保存获取到的图片
i=0
for img_url in img_urls:
#对每一张图片进行处理
response=requests.get(img_url,headers)
content=response.content
#以wb(二进制)的形式保存图片,并进行命名
with open('{}.jpg'.format(i),'wb') as f:
#把这个网址的内容保存到上面的jpg文件中
f.write(content)
#图片按照先后顺序进行从1到n的命名,所以i++
i+=1
#***********************************************
if __name__ =='__main__':
get_img(url)
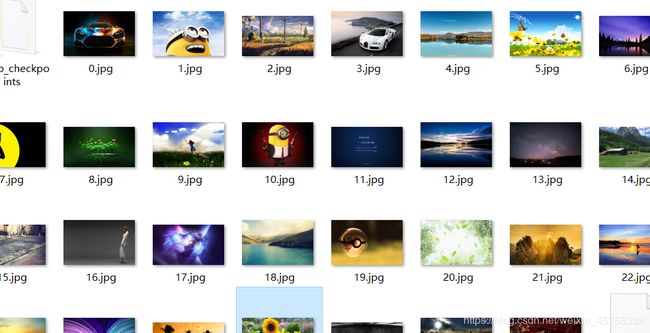
这是爬取后保存到我同文件目录下的图片
性能优化
保存到特定文件夹
#***********************************************
#自动创建保存图片的文件夹
word = input ('请输入文件夹的名称:')
if not os.path.exists(word):
#如果不存在就自己生成一个
os.mkdir(word)
#获取单张图片的url,并保存图片
#***********************************************
def get_img(url):
#获取到这个网页,并对其解码
response=requests.get(url,headers)
content=response.content.decode('utf-8')
#正则表达式来查找这个content网址的thumbURL里面的内容,也就是图片的网址
#re.S如果不设置的话就会进行单行匹配,也就是可能无法找到所有内容
img_urls=re.findall('"thumbURL":"(.*?)"',content,re.S)
#***********************************************
#保存获取到的图片
i=0
for img_url in img_urls:
#对每一张图片进行处理
response=requests.get(img_url,headers)
content=response.content
#以wb(二进制)的形式保存图片,并进行命名
with open('{}.jpg'.format(i),'wb') as f:
#把这个网址的内容保存到上面的jpg文件中
f.write(content)
#图片按照先后顺序进行从1到n的命名,所以i++
i+=1
#***********************************************
if __name__ =='__main__':
get_img(url)
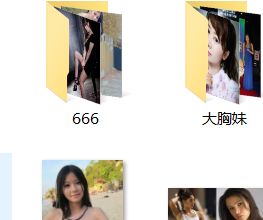
可以看到文件夹里爬取了好多壁(mei)纸
设置下载内容
![]()
上下两个图片对比下,Word之前都是一样的,就是后面的搜索内容不用,导致了搜索结果不同,所以我们可以借助这个来对指定内容的图片进行下载

import requests
import re
import os
#num=int(input('请输入要爬取的图片页数(一页30张):'))
#自动创建保存图片的文件夹
word = input ('请输入文件夹的名称:')
#*****************************************************
#这里 我取了内容之前的网址,最后在加上内容
url='https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq\
=1594449010780_R&pv=&ic=&nc=1&z=&hd=&latest=©right=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf\
-8&sid=&word='+word
#*****************************************************
print(url)
if not os.path.exists(word):
#如果不存在就自己生成一个
os.mkdir(word)
#获取单张图片的url,并保存图片
def get_img(url):
#获取到这个网页,并对其解码
response=requests.get(url,headers)
content=response.content.decode('utf-8')
#正则表达式来查找这个content网址的thumbURL里面的内容,也就是图片的网址
#re.S如果不设置的话就会进行单行匹配,也就是可能无法找到所有内容
img_urls=re.findall('"thumbURL":"(.*?)"',content,re.S)
#***********************************************
i=0
#保存获取到的图片
for img_url in img_urls:
#对每一张图片进行处理
response=requests.get(img_url,headers)
content=response.content
#以wb(二进制)的形式保存图片,并进行命名
with open(word+'/'+'{}.jpg'.format(i),'wb') as f:
#把这个网址的内容保存到上面的jpg文件中
f.write(content)
print("正在爬取第%d张图片"%i)
#图片按照先后顺序进行从1到n的命名,所以i++
i+=1
#***********************************************
if __name__ =='__main__':
get_img(url)
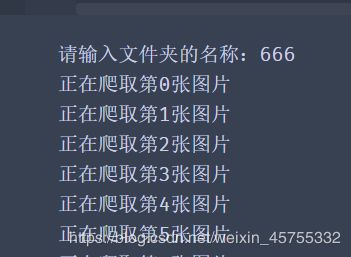
这里我输入了666,他给我创建了一个666的文件夹,并且爬取到了关于666的图片

设置下载数量
当我们向下拉滑时,可以看到这里的数字在三十三十的增长,也就是每一页图片都是三十张,这样我们就有思路了,可以借助这个来获取多张图片

但我们不能借助上面的网址来解析了,因为那里没有图片数量,我们可以用右面的Request URL来解析。
这里我复制了下大家可以看看,这里有图片的网址及名称,所以我们可以用正则表达式来读取网址。
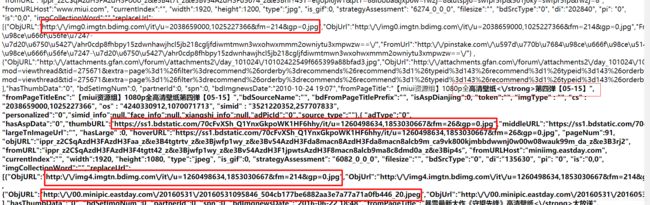
这里为了向大家证明这个Request URL是可以解析的,我把url换成了“高清壁纸”的Request URL,并输入了666,这里可以看到,之前的图片换成了高清壁纸,当然我们还没设置数量和内容。

下面设置我们要爬取的内容和数量
和上面一样,我们只保留word=之前的东西,Request URL的Word后面有两个内容,一个是图片内容,一个是图片数量。
我们可以&word= 后面的word我们需要爬取的内容;+&pn也就是page number照片的页数,一页三十张,所以后面for 循环就是30 60 90 这样训话下去的直到num30(之所以+1是因为python for循环包前不包后,所以230是到59就听了,所以要+1)
urls=['https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E9%AB%98%E6%B8%85%E5%A3%81%E7%BA%B8&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=&hd=&latest=©right\
=&word=' + word +'&pn={}'.format(j) for j in range(30,num*30+1,30)
]
这里要注意:
- 既然是for循环了,所以他一定是个数组,而下面我们是单个url,所以可以最后调用的时候,用for循环读取urls的url
if __name__ =='__main__':
for url in urls:
get_img(url)
2.这里我们的i在循环之外,函数之内,这里的每次调用get_img(url)函数,i就会从0开始计数,所以我们要设置一个全局变量 global i,让他不在从0开始。
这里是完整代码
#导入需要的模块
import requests # requests是python实现的最简单易用的HTTP库
import re #regular expression,正则表达式,是用来简洁表达一组字符串特征的表达式。最主要应用在字符串匹配中。
import os #os库提供通用的,基本的操作系统交互功能(windows,mac os,linux)
#一般网站都有反爬虫机制,所以我们要对我们的爬虫进行伪装
#先去该网址找到他的请求头
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.7 Safari/537.36'}
#自动创建保存图片的文件夹
word = input ('请输入想下载的图片的名称:')
if not os.path.exists(word):
#如果不存在就自己生成一个
os.mkdir(word)
#我们需要爬取图片的页数
num=int(input('请输入要爬取的图片页数(一页30张):'))
urls=['https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E9%AB%98%E6%B8%85%E5%A3%81%E7%BA%B8&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=\
&ic=&hd=&latest=©right=&word=' + word +'&pn={}'.format(j) for j in range(30,num*30+1,30)
]
i= 1
#获取单张图片的url,并保存图片
def get_img(url):
#获取到这个网页,并对其解码
response=requests.get(url,headers)
content=response.content.decode('utf-8')
#正则表达式来查找这个content网址的thumbURL里面的内容,也就是图片的网址
#re.S如果不设置的话就会进行单行匹配,也就是可能无法找到所有内容
img_urls=re.findall('"thumbURL":"(.*?)"',content,re.S)
#保存获取到的图片
#设置成全局变量
global i
for img_url in img_urls:
#对每一张图片进行处理
response=requests.get(img_url,headers)
content=response.content
#以wb(二进制)的形式保存图片,并进行命名
with open(word+'/'+ '{}.jpg'.format(i),'wb') as f:
f.write(content)
print("正在爬取第%d张图片"%i)
#图片按照先后顺序进行从1到n的命名,所以i++
i+=1
if __name__ =='__main__':
for url in urls:
get_img(url)
自己可以尝试换一些网站爬取,大题思路是这样的,但各个网站又有自己的特色,有的反爬虫机制做的很厉害,所以想爬取还是要深入的学习,这里只是入门级教程,所以写的很详细,之后会写爬取一些较难的网站教程,可以持续关注。