简洁明了的tensorflow2.0教程——实现鸢尾花分类
通过本文你可以学会神经网络最基本的用法,可以对tensorflow用法有初步的了解,实现神经网络入门,适用于有着在机器学习/或者深度学习有着理论基础,拥有一定python编程基础但是对神经网络实践缺少经验的coder,通过阅读并且自己完成本篇博客中的代码小白也能学会如何利用神经网络来实现简单的分类任务。这一讲源码在我的github,地址:https://github.com/JohnLeek/Tensorflow-study,源码文件为day1_iris_classfiction.py,觉得不错可以给个Star。
一、环境配置
这里需要用到的第三方包有numpy,pandas,matplotlib,sklearn,注意的是tensorflow用的是2.0版本,不涉及图像GPU和CPU版本随意选择,读者可先用pip命令安装好所需要的包,tensorflow2.0的安装配置见我这篇博客,https://blog.csdn.net/JohnLeeK/article/details/104508885,开发工具选择pycharm,pycharm中配置tensorflow运行环境可以参考我的这篇matplot配置博客,https://blog.csdn.net/JohnLeeK/article/details/99582355,大同小异,也可自行百度解决。
二、鸢尾花数据集展示与说明
废话不多说直接进入正题,首先我们看一下鸢尾花数据集的结构
敲入如下代码:
from sklearn import datasets
from pandas import DataFrame
import pandas as pd
#.data返回特征值
x_data = datasets.load_iris().data
#.target 返回标签
y_data = datasets.load_iris().target
print("x_data from datasets: \n",x_data)
print("y_data from datasets: \n",y_data)
x_data = DataFrame(x_data,columns=['花萼长度','花萼宽度','花瓣长度','花瓣宽度'])
pd.set_option('display.unicode.east_asian_width',True)
x_data['类别'] = y_data
print("x_data add a column: \n",x_data)
结果:

可知数据集提供了死个鸢尾花属性,分别为花萼长度、花萼宽度、花瓣长度、花瓣宽度,0,1,2分别对应不同的鸢尾花品种。到这里我们就可以设计出来本次鸢尾花分类的神经网络模型,输入层4个神经元对应鸢尾花数据集的4个特征,输出层3个神经元对应鸢尾花的3个分类。
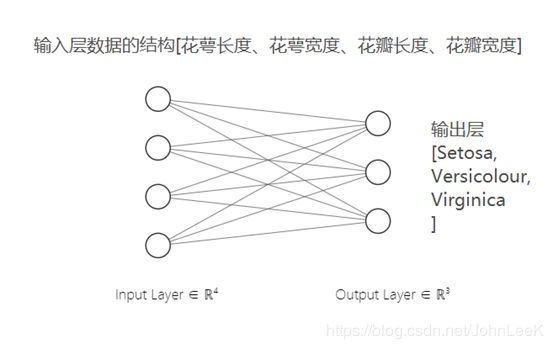
好了有了数据集的准备,并且我们也搭建出来了简单的神经网络模型(不包括偏置神经元,通常在设计神经网络时会忽略,bias)。
三、本次实验中用到的函数介绍
1、tf.cast
tf.cast(data,tf.float32)
这个函数用于将我们的数据转化为可供tensorflow训练和测试使用的张量(Tensor),通常我们读取的数据为numpy格式或者是python自带的数据形式,但是在喂入神经网络的时候需要做转化,使用cast函数即可,data为我们要转化的数据,tf.float32为转化之后的数据类型。
2、tf.data.Dataset.from_tensor_slices
tf.data.Dataset.from_tensor_slices(tensor1,tensor2)这个函数会将我们的训练接Tensor1和tensor2做标签对应关系,以方便神经网络训练,注意tensor1和tensor2维度必须相同。
3、tf.Variable
tf.Variable(
initial_value=None, trainable=None, validate_shape=True, caching_device=None,
name=None, variable_def=None, dtype=None, import_scope=None, constraint=None,
synchronization=tf.VariableSynchronization.AUTO,
aggregation=tf.compat.v1.VariableAggregation.NONE, shape=None
)这里我们只使用initial_value,这个函数会将我们传入的tensor或者数标记为“可训练”,可以在训练的过程中更新我们传入的参数。
4、tf.random.truncated_noaml
tf.random.truncated_normal(
shape, mean=0.0, stddev=1.0, dtype=tf.dtypes.float32, seed=None, name=None
)shape参数指定我们生成的神经元形状用list传入,如[4,3]指定生成4的神经元,3为输出,mean为生成随机数的中指,stddev为方差,seed为随机数种子。
5、tf.GradientTape
tf.GradientTape(
persistent=False, watch_accessed_variables=True
)该函数可实现参数的自动求导
6、tf.matmual
该函数实现了tensor的乘法
7、tf.nn.softmax
tf.nn.softmax(
logits, axis=None, name=None
)神经网络最后的输出为矩阵的形式,为了获得我们期待的形式我们使用softmax让输出符合概率分布
8、tf.one_hot
tf.one_hot(
indices, depth, on_value=None, off_value=None, axis=None, dtype=None, name=None
)将标签转化为独热码性质,注意depth,这里指定分类,鸢尾花分类是3,所以depth=3
9、gradient
配合tf.GradientTape使用,实现参数的求导
10、assign_sub
实现参数自更新
四、正式开始工作
导入我们要用到的模块:
import tensorflow as tf
from sklearn import datasets
from matplotlib import pyplot as plt
import numpy as np
刚才我们已经看过鸢尾花数据集结构了,现在我们导入数据集
x_data = datasets.load_iris().data
y_data = datasets.load_iris().target
首先官方给出的数据集是有顺序的,所以我们需要打乱数据集顺序,如同我们人认识这个世界的时候一样,知识都是杂乱无章的涌入我们大脑的,避免陷入局部最优解,可以获得更高的分类准确率。
###seed为随机种子,保证每次生成的随机数一样
###方便你得到的结果和我一样
np.random.seed(116)
np.random.shuffle(x_data)
np.random.seed(116)
np.random.shuffle(y_data)
tf.random.set_seed(116)
这样我们就保证了数据集的乱序,而且乱序用的seed是一样的,所以都有同样的顺序。
接下来我们拆分数据集和训练集,指定前120组数据为训练集,剩余的30组数据为测试集,通常训练集大小为总数据集大小的60%--70%。
x_train = x_data[:-30]
y_train = y_data[:-30]
x_test = x_data[-30:]
y_test = y_data[-30:]
tensorflow中一般默认数据类型为float32,但是我们读入的数据可能不是,所以我们做一下强制类型转换,保证数据的类型统一。
x_train = tf.cast(x_train,tf.float32)
x_test = tf.cast(x_test,tf.float32)
我们要实现输入数据就能得到对应的输出,还需要将特征值和标签匹配。
'''
匹配输入特征还有标签
batch为喂入神经神经网络每组数据大小
'''
train_db = tf.data.Dataset.from_tensor_slices((x_train,y_train)).batch(32)
test_db = tf.data.Dataset.from_tensor_slices((x_test,y_test)).batch(32)
这里batch为喂入神经网络的数据集大小,我们设置为32,这样就是分四次喂入神经网络。完成了基本准备工作后,我们就开始利用tensorflow搭建神经网络。
'''
搭建神经网络,4个特征值,输入层为4个神经元;3分类,所以输出层为3个神经元
seed保证生成的随机数相同,实际项目不需要
Variable标记训练参数
'''
w1 = tf.Variable(tf.random.truncated_normal([4,3],stddev=0.1,seed=1))
b1 = tf.Variable(tf.random.truncated_normal([3],stddev=0.1,seed=1))
接下来我们设置学习率,和迭代次数
lr = 0.1#学习率
train_loss_result = []#记录每轮训练之后的loss
test_acc = []#模型准确度
epoch = 500#每轮训练次数
loss_all = 0#每轮分为4step,记录四个step生成的4个loss和
神经网络训练部分
神经网络训练部分
for epoch in range(epoch): #数据集别循环每个epoch遍历一次数据集
for step,(x_train,y_train) in enumerate(train_db): #batch级别循环,每个step循环一个batch
with tf.GradientTape() as tape: #梯度下降求得参数值
y = tf.matmul(x_train,w1) + b1 #函数表达式 y = xw + b
y = tf.nn.softmax(y)#使输出符合概率分布
y_ = tf.one_hot(y_train,depth = 3)#将标签转化为独热码,方便求loss和accuracy
loss = tf.reduce_mean(tf.square(y_-y))#采用均方误差损失函数mes = mean(sum(y-out)^2)
loss_all += loss.numpy()#将每个step计算得出的loss累加,为后续求loss平均值提供数据
#计算w1和b1梯度
grads = tape.gradient(loss,[w1,b1])
#更新梯度
w1.assign_sub(lr*grads[0])
b1.assign_sub(lr*grads[1])
#每个epoch打印下loss
print("Epoch: {},loss: {}".format(epoch,loss_all/4))
#保存每个step的平均值
train_loss_result.append(loss_all/4)
训练完成之后我们便可以验证模型准确率了。
'''
total_correct为预测正确的样本个数
total_number为测试样本总数
'''
total_correct,total_number = 0,0
for x_test,y_train in test_db:
y = tf.matmul(x_test, w1) + b1
y = tf.nn.softmax(y)
pred = tf.argmax(y, axis=1) # 返回y中的最大值索引,即预测分类
# 将pred转化为y_test数据类型
pred = tf.cast(pred, dtype=y_test.dtype)
# 如果分类正确,correct = 1 否则为0,将bool类型结果转化为int
correct = tf.cast(tf.equal(pred, y_test), dtype=tf.int32)
# 将每个batch的correct数加起来
correct = tf.reduce_sum(correct)
# 将所有batch中的correct加起来
total_correct += int(correct)
# total_number为测试的总样本数,即x_test的行数,shape[0]返回行数
total_number += x_test.shape[0]
# 计算准确率
acc = total_correct / total_number
test_acc.append(acc)
print("Test_acc:", acc)
print("这是一条分割线------------------********************++++++++++++++++++")
结果可视化:为了方便我们观察模型训练结果我们使用matplotlib将准确率还有损失函数更新情况绘制成图片。
#绘制loss曲线
plt.title("Losss Function Curve")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.plot(train_loss_result,label="$Loss$")# 逐点画出trian_loss_results值并连线,连线图标是Loss
plt.legend()
plt.savefig("./loss")
#绘制Accuracy曲线
plt.title("Acc Curve")
plt.xlabel("Epoch")
plt.ylabel("Acc")
plt.plot(test_acc,label="$Accuracy$") # 逐点画出test_acc值并连线,连线图标是Accuracy
plt.legend
plt.savefig("./acc")
五、结果展示

从图中可以看出在我们完成500轮训练之后,分类准确率达到了100%,总的来说模型准确率不错,接下来看看绘制的Accuracy和Loss曲线。

可以看到在200轮左右模型基本得到了最优解,Loss也是一直下降,至此我们的第一个深度学习模型就已经搭建完毕。随后的博客中我会持续更新tensorflow2.0学习笔记,从简单的神经网络到CNN到RNN再到GAN。如果你觉得我的博客对你有帮助,别忘记点赞,你的点赞是我更新的动力!本节源码github地址:https://github.com/JohnLeek/Tensorflow-study,源码文件为:day1_iris_classfiction.py,觉得不错可以给个Star。