[实例分割] SOLOv2: Dynamic, Faster and Stronger
转载请注明作者和出处: http://blog.csdn.net/john_bh/
论文链接: SOLOv2: Dynamic, Faster and Stronger
作者及团队:阿德莱德大学 & 清华大学 & 字节跳动 AI Lab
会议及时间:Arxiv 2020.3
code1:https://github.com/WXinlong/SOLO
文章目录
- 1.主要贡献
- 2. SOLOv1
- 3. SOLOv2
- 3.1 Dynamic Instance Segmentation
- 3.2 Matrix NMS
- 4. Experiments
- 4.1 Ablation Experiments
- 4.2 Boundingbox Object Detection
- 4.3 Results on the LVIS dataset
- 4.4 Panoptic Segmentation
1.主要贡献
SOLOv2中作者旨在建立一个性能强大的简单,直接,快速的实例分割框架。
- 提出动态学习对象分割器的 mask head,这样使mask head 依赖于位置。具体来说,将掩码分支分解为mask kernel分支和mask feature 分支,分别学习卷积核和卷积特征。—
mask learning - 提出矩阵NMS(non maximum suppression)以显着减少由于掩码的NMS造成的推理时间开销。Matrix NMS一次性使用并行矩阵操作执行NMS,并产生了更好的结果。—
mask NMS - SOLOv2 可以用于目标检测和全景分割任务,也可以作为势力级识别任务的baseline,代码地址:https://git.io/AdelaiDet 。
- Dynamic Convolutions:
- 在传统的卷积层中,学习的卷积核保持固定并独立于输入;
- 空间变换网络(Spatial Transform Networks)预测了全局参数变换以扭曲特征图,从而使网络能够自适应地对以输入为条件的特征图进行变换;
- 动态滤波器(Dynamic filter)来主动预测卷积滤波器的参数。 它以样本特定的方式将动态生成的滤镜应用于图像;
- 可变形卷积网络(Deformable Convolutional Networks)通过预测每个图像位置的偏移量来动态学习采样位置。
- NonMaximum Suppression
- NMS 根据阈值很硬去除重复的预测;
- Soft-NMS 根据邻居与较高得分的预测的重叠来降低其置信度得分。与传统的NMS相比,检测精度有所提高,但由于顺序操作,推理速度较慢;
- 自适应NMS 将动态抑制阈值应用于每个实例,该阈值是针对人群中的行人检测量身定制的;
- Fast NMS可以并行地确定要保留的预测还是丢弃的预测。请注意,它会以性能下降为代价加快速度;
Matrix NMS解决了以下问题:同时进行硬删除和顺序操作。结果,在简单的PyTorch实施中,Matrix NMS能够在不到1 ms的时间内处理500个掩模,并且比Fast NMS的效率高出0.4%。
2. SOLOv1
![[实例分割] SOLOv2: Dynamic, Faster and Stronger_第1张图片](http://img.e-com-net.com/image/info8/38a9b795ab0a498182ae210b4d365eec.jpg)
SOLOv1输入图像被划分为 S × S S\times S S×S网格。如果对象的中心位于网格单元格中,则该网格单元格负责预测语义类别以及分配每个像素的位置类别。其中包含两个分支:类别分支和掩码分支。
- 类别分支:预测语义类别。对于每个网格,SOLO都会预测 C C C 维输出,用来表示语义类的概率。其中, C C C 是类别的数量。这些概率取决于网格单元,如果将输入图像划分为 S × S S×S S×S 网格,则输出空间将为 S × S × C S×S×C S×S×C。
- 掩码分支:对对象实例进行分割。给定输入图像 I I I ,如果将其划分为 S × S S\times S S×S 网格,则总共最多会有 S 2 S^2 S2 个预测掩码。具体来说,实例掩码输出将具有 H I × W I × S 2 H_I \times W_I \times S^2 HI×WI×S2 维。第 k t h k^{th} kth 个通道将负责在网格 ( i , j ) (i,j) (i,j) 处分割实例,其中 k = i ⋅ S + j k=i\cdot S+j k=i⋅S+j ( i i i 和 j j j 从零开始)。 这样,在语义类别和class-agnostic 掩码之间建立了一对一的对应关系,如图2所示。
![[实例分割] SOLOv2: Dynamic, Faster and Stronger_第2张图片](http://img.e-com-net.com/image/info8/2b9497da204448ba8f4d441338e26e18.jpg)
掩码分支的最后一层是 1 × 1 1\times 1 1×1卷积层,以特征 F ∈ R H × W × E F\in R^{H\times W\times E} F∈RH×W×E 为输入,输出 S 2 S^2 S2通道,即 M M M。卷积核 G ∈ R 1 × 1 × E × S 2 G\in R^{1\times 1\times E \times S^2} G∈R1×1×E×S2,操作可以写成:

这一层可以看作是 S 2 S^2 S2 分类器,每个分类器负责分类像素是否属于这个位置类别。.
![[实例分割] SOLOv2: Dynamic, Faster and Stronger_第3张图片](http://img.e-com-net.com/image/info8/02d4b21fb45847b09ad93739ceadf0e7.jpg)
如图7所示,SOLOv1 中, decoupled SOLO 原始输出张量 M ∈ R H × W × S M\in R^{H\times W \times S} M∈RH×W×S 被分别对应于两个轴的两个输出张量 X ∈ R H × W × S X\in R^{H\times W \times S} X∈RH×W×S和 Y ∈ R H × W × S Y\in R^{H\times W \times S} Y∈RH×W×S代替。 因此,输出空间从 H × W × S 2 H\times W \times S^2 H×W×S2 减少到 H × W × 2 S H\times W \times 2S H×W×2S。对于位于网格位置 ( i , j ) (i,j) (i,j)的对象,vanilla SOLO在输出张量 M M M 的第 k k k 个通道上对其掩码进行分割,其中 k = i ⋅ S + j k = i\cdot S + j k=i⋅S+j。 在 decoupled SOLO中,该对象的掩模预测被定义为两个通道映射的元素乘:

从另一个角度看,既然输出 M M M 是冗余的,特征 F F F 是固定的,为什么不直接学习卷积核 G G G 呢?这样,可以简单地从预测的 S 2 S^2 S2 分类器中选取有效的分类器,并动态地进行卷积。模型参数的数量也减少了。此外,由于预测的内核是根据输入动态生成的,因此它得益于灵活性和自适应特性。此外,每个 S 2 分 S^2分 S2分类器都取决于位置。此它符合按位置分割对象的核心思想,并通过按位置预测分割器更进一步。
3. SOLOv2
3.1 Dynamic Instance Segmentation
SOLOv2继承了SOLOv1的大部分设置,如网格单元、多级预测、CoordConv 和 loss function。在此基础上,引入了将原始掩码分支解耦为mask kernel 分支和 mask feature 分支的动态方案,分别用于预测卷积核和卷积特征。图2显示了与SOLOv1的比较。
![[实例分割] SOLOv2: Dynamic, Faster and Stronger_第4张图片](http://img.e-com-net.com/image/info8/6ab0016b02534c6698aa4c3099a6a232.jpg)
-
Mask Kernel Branch
Mask kernel 分支位于预测head内,与语义类别分支平行。预测 head 在 FPN 输出的特征图金字塔上工作。Head内的2个分支都有4个卷积层来提取特征,最终的的一个卷积层做预测。Head 的权重在不同的特征图层级上共享。作者在kernel分支上增加了空间性,做法是在第一个卷积内加入了归一化的坐标,即输入后面跟着两个额外的通道。对于每个网格,kernel分支预测 D D D 维输出,表示预测的卷积核权重,其中 D D D 是参数的数量。 当为了生成具有 E E E 个输入通道的 1 × 1 1\times 1 1×1 卷积的权重, D = E D=E D=E,当 3 × 3 3 \times 3 3×3 卷积, D = 9 E D=9E D=9E。这些生成的权重取决于位置,即网格单元。 如果将输入图像划分为 S × S S \times S S×S 个网格,则输出空间将为 S × S × D S \times S \times D S×S×D。
注意到这里不需要激活函数。(这里输入为 H × W × E H×W×E H×W×E 的特征 F F F ,其中 E E E 是输入特征的通道数;输出为卷积核 S × S × D S×S×D S×S×D ,其中 S S S 是划分的网格数目, D D D 是卷积核的通道数。对应关系如下: 1 × 1 × E 1×1×E 1×1×E 的卷积核,则 D = E D=E D=E , 3 × 3 × E 3×3×E 3×3×E 的卷积核,则 D = 9 E D=9E D=9E,以此类推) 。 -
Mask Feature Branch
掩码特征分支需要预测实例感知特征图 F ∈ R H × W × E F \in R^{H\times W\times E} F∈RH×W×E,其中 E E E 是掩码特征的维数。 F F F 将由mask kenel 分支的输出卷积。 如果使用了所有预测权重,即 S 2 S^2 S2 分类器,则最终卷积后的输出实例掩码将为 H × W × S 2 H\times W \times S^2 H×W×S2,这与SOLOv1的输出空间相同。由于掩模特征和掩模核是解耦和分别预测的,因此有两种构造掩模特征分支的方法:
1.predict the mask features for each FPN levels:分别可以把它和内核分支一起放到head中,这样可以预测每个FPN级别的掩码特征。
2.predict a unified mask feature representation for all FPN levels:为所有FPN级别预测一个统一的掩码特征表示。作者采用了通过比较采用后一种方法,以提高其有效性和效率。为了学习统一的高分辨率掩码特征表示,作者使用特征金字塔融合:将FPN P2 至 P5层分别依次 经过 【 3 × 3 3\times 3 3×3 conv,group norm,ReLU和 2x bilinear upsampling】,这样 FPN特征 P2 至 P5 被合并到了一个相同的输出(原图的1/4),然后再做逐点相加(element-wise summation),最后一层做【 1 × 1 1\times1 1×1卷积,group norm 和ReLU】操作。 详细信息如图3所示。
应该注意的是,在进行卷积和双线性上采样之前,将归一化的像素坐标输入到最深的FPN级别(以1/32比例)。 提供的准确位置信息对于启用位置敏感度和预测实例感知功能非常重要。
![[实例分割] SOLOv2: Dynamic, Faster and Stronger_第5张图片](http://img.e-com-net.com/image/info8/c89fd086fe1e45e78eb320610e884b92.jpg)
-
Forming Instance Mask:
对于每个单元格 ( i , j ) (i,j) (i,j),首先得到掩码核 G i , j , : ∈ R D G_{i,j,:} \in R^D Gi,j,:∈RD 然后将 G i , j G_{i,j} Gi,j与 F F F 卷积得到实例掩码。总的来说,每个预测级别最多有 S 2 S^2 S2掩码。最后,使用 Matrix NMS 得到最终的实例分割结果。 -
Learning and Inference
Loss 函数和 SOLOv1 一样,如公式2所示:
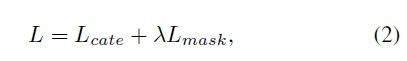
3.2 Matrix NMS
其启发自soft NMS,soft NMS 是每次选择置信度最高的候选mask(或框)降低与其存在重叠的候选mask(或框)的置信度。这种过程像传统的Greedy NMS一样是顺序的,无法并行实现。作者反其道而行之,既然是降低每个mask的置信度,那我就干脆想办法按照一定规则对所有mask挨个降低置信度。
某一候选 m j m_j mj 置信度被降低,和两方面因素有关:其衰减因子受以下因素影响:
- 1.每个预测 m i m_i mi对 候选 m j m_j mj的惩罚 ( 预 测 得 分 s i > 候 选 得 分 s j ) (预测得分s_i> 候选得分s_j) (预测得分si>候选得分sj); 可以通过 f ( i o u i , j ) f(iou_{i, j}) f(ioui,j)轻松计算 m j m_j mj 上每个预测 m i m_i mi 的惩罚值 ;
- 2. m i m_i mi 本身也有一定该路置信度被其他候选 m k m_k mk降低。当然 m k m_k mk 的置信度还有可能被其他 m k m_k mk迫使衰减,如果考虑到完整链条,那这个过程就复杂了,作者以上面的过程作为计算衰减因子的近似,不追求完美的数学表达。而且实际计算时仅考虑最大重叠的置信度高的mask的带来的衰减。而且,概率通常与IoU呈正相关。 所以,在这里可以直接用 most overlapped prediction m i m_i mi来近似概率:
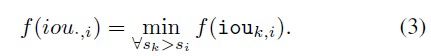
为此,最终的衰变因子变成公式4:
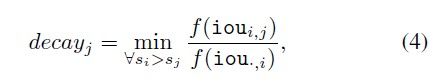
更新后的分数由 s j = s j ⋅ d e c a y j s_j=s_j \cdot decay_j sj=sj⋅decayj 计算得出。
考虑两个最简单的递减函数,表示为线性函数:
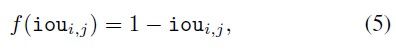
Gaussian:

Matrix NMS的所有操作都可以一次性实现,不需要递归。
- 对按分数降序排列的前N个预测计算一个两两配对的IoU矩阵。对于二进制掩码,IoU矩阵可以通过矩阵运算有效地实现;
- 计算得到了IoU矩阵上的最大列数重叠的IoU;
- 计算所有较高得分预测的衰减因子,通过逐列最小值选取各预测的衰减因子作为最有效的衰减因子(Eqn. (4));
- 最后,通过衰减因子对分数进行更新。
为了使用,只需要threshing和选择 top-k 得分掩码作为最终的预测。
图4显示了Pytorch风格的 Matrix NMS 伪代码:
![[实例分割] SOLOv2: Dynamic, Faster and Stronger_第6张图片](http://img.e-com-net.com/image/info8/6003acc49475499b9e9844b9299fe41c.jpg)
4. Experiments
- Main Results
![[实例分割] SOLOv2: Dynamic, Faster and Stronger_第7张图片](http://img.e-com-net.com/image/info8/0d89a2c4d040427683fed671101a2498.jpg)
- SOLOv2 Visualization
可视化掩码特征分支的输出.,如图5所示: 使用最终输出 64 个通道的模型(mask prediction 前的最后一层特征图的通道 E=64)。首先,mask feature 是 position-aware 的;其次,一些特征图对所有的前景目标响应(白色框)![[实例分割] SOLOv2: Dynamic, Faster and Stronger_第8张图片](http://img.e-com-net.com/image/info8/5d8cb47a505248508db712cd09743448.jpg)
与Mask R-CNN分割结果的比较:
![[实例分割] SOLOv2: Dynamic, Faster and Stronger_第9张图片](http://img.e-com-net.com/image/info8/b190089477db43188ff7d0d2023eef14.jpg)
最终的输出如图8所示。不同的物体有不同的颜色,SOLOv2方法在不同的场景中显示了良好的效果,值得指出的是,边界处的细节被很好地分割,特别是对于大型对象。
![[实例分割] SOLOv2: Dynamic, Faster and Stronger_第10张图片](http://img.e-com-net.com/image/info8/2c6bc4f4eb9c4f06bca50841cff1edd8.jpg)
4.1 Ablation Experiments
-
COCO test-dev数据集上进行了实例分割实验:
![[实例分割] SOLOv2: Dynamic, Faster and Stronger_第11张图片](http://img.e-com-net.com/image/info8/05b54aa7a55949e29cd53633aadd8c74.jpg)
-
Kernel shape: 最优的是 1x1x256,文章中所有试验都用的这个参数
![[实例分割] SOLOv2: Dynamic, Faster and Stronger_第12张图片](http://img.e-com-net.com/image/info8/9f5a6d91e3f84200b7b20b1529d3dbc0.jpg)
-
Effectiveness of coordinates: 由于本文是使用位置,或更确切的说,是利用位置来学习目标分割器。如果 mask kernel branch 对位置不敏感,则外观相同的目标将会有相同的kernel,导致相同的输出 mask。如果 mask feature branch 对位置不敏感,则它将不知道如何按照 mask 匹配的顺序将像素分配给不同通道。如表4所示,如果没有 coordinates 输入,则只能达到 36.3% AP。
这个结果还比较理想,因为 CNN 可以从 zero-padding 操作中隐式的学习到绝对位置信息。但这种隐式的学习是不准确的,使用 coordconv 时,可以增加 1.5 AP。
![[实例分割] SOLOv2: Dynamic, Faster and Stronger_第13张图片](http://img.e-com-net.com/image/info8/4a965411c6ad4abca661c2074de0b3bb.jpg)
-
Unified Mask Feature Representation: 对于 mask 特征的学习,有两种选择:
- 分别学习 FPN 每个 level 的特征(solov1);
- 统一学习一个表示(图3)
表5中对比了这两种不同的方法,后者取得了好的效果,这也很容易理解,在 solov1中,大尺寸对象被分配到高层特征中去分割,高层特征的分辨率较低,会导致边界估计比较粗略。
![[实例分割] SOLOv2: Dynamic, Faster and Stronger_第14张图片](http://img.e-com-net.com/image/info8/f015281f43164966898401eef2dcdc52.jpg)
-
Dynamic and Decoupled: 动态学习 head 和 decoupled head 在表6中进行了对比,dynamic head 比 decoupled head 高 0.7% AP。这种提升,作者觉得来源于网络根据输入来动态的学习 kernel weights。
![[实例分割] SOLOv2: Dynamic, Faster and Stronger_第15张图片](http://img.e-com-net.com/image/info8/1c5494726f174374afe4baff6be680de.jpg)
-
Matrix NMS:
![[实例分割] SOLOv2: Dynamic, Faster and Stronger_第16张图片](http://img.e-com-net.com/image/info8/ab20fc87d1a34cc19367d8bb68b91c81.jpg)
-
Real-time setting: 除了精度高,速度也是SOLOv2的一点亮点,精度与Mask R-CNN相近的SOLO-512 在V100的GPU上可达31.3 fps!
![[实例分割] SOLOv2: Dynamic, Faster and Stronger_第17张图片](http://img.e-com-net.com/image/info8/8c720b1832fa42c3bbae4bb836cff8a9.jpg)
4.2 Boundingbox Object Detection
作者在生成的mask 上直接生成目标框,得到同样在COCO test-dev数据集上目标检测的结果,同样达到了主流算法水平:
![[实例分割] SOLOv2: Dynamic, Faster and Stronger_第18张图片](http://img.e-com-net.com/image/info8/d8d2e1dbb7e7435482f70dc0c6c2433d.jpg)
下图为作为目标检测算法使用时,与其他算法的精度和推断时间比较的散点图:
![[实例分割] SOLOv2: Dynamic, Faster and Stronger_第19张图片](http://img.e-com-net.com/image/info8/9b04265972c54f7f9c6572a795d9fbbf.jpg)
4.3 Results on the LVIS dataset
SPLOv2的几个版本在速度与其他相近时,精度大幅超越对手。从图中可见,相比经常被谈起的YOLOv3,SOLOv2 精度提升巨大。
作者在新出的LVIS实例分割数据集上与Mask R-CNN也进行了对比:
![[实例分割] SOLOv2: Dynamic, Faster and Stronger_第20张图片](http://img.e-com-net.com/image/info8/677295e1208145a1b85649b09d5bc43e.jpg)
4.4 Panoptic Segmentation
大多数情况下好于Mask R-CNN,平均精度更高,唯有在小目标分割上低于Mask R-CNN,这可能与网格的划分有关系(当然划分密集有助于检测到小目标,但计算代价更大)。将SOLOv2用于全景分割,在COCO val2017数据集上的结果:
![[实例分割] SOLOv2: Dynamic, Faster and Stronger_第21张图片](http://img.e-com-net.com/image/info8/d2e116a243654144a623258ce767b660.jpg)