python数据分析之pandas(1)
python数据分析之pandas(1)
前言
最近在学习关于数据分析和数据挖掘相关的东西,来记录一下自己的学习过程,和大家一起分享。希望能够和大家一起讨论,学习更多。
工具
我用的是anaconda的jupyter notebook,学习资料大部分来自Github。
开始
学习pandas库,最先接触到的就是读取数据啦,我们pandas可以读取纯文本文件(csv文件, txt文件),还可以读取xlsx的excel文件,当然还可以读取MySQL数据表。
ps:现在连接MySQL数据库的方法主要有MySQLdb和pymysql。但是现在MySQLdb还不支持python3.0,还只能适用于2.0。所以我一般用的是pymysql,它们安装都很简单,只需要通过pip install安装就好了。
import pandas as pd
首先导入库,简化命名为pd,通过pandas中的read_cvs(path)方法进行数据的读取。path中填写文件的位置。当然可以先用变量保存一下下哈。
用pd.read_csv()读取数据
fpath = "../pandas/datas/ml-latest-small/ratings.csv"
ratings = pd.read_csv(fpath)
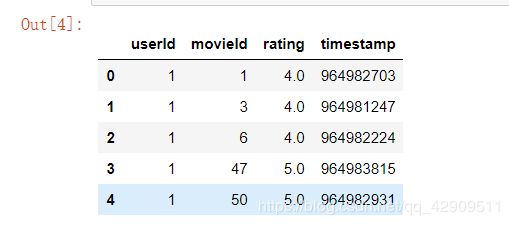
ratings.head()
读取数据之后,通过head()可以输出数据中的前5条数据,也可以自己在方法里面设置读取的数据条数。
当然,pandas还有很多基础的函数对数据分析。
ratings.shape #显示数据的行数和列数
ratings.columns #查看列名列表
ratings.dtypes # 查看每列的数据类型
读取txt文件,自己指定分隔符、列名
fpath = "./datas/crazyant/access_pvuv.txt"
pvuv = pd.read_csv(fpath, sep="\t", header=None, names=['pdate', 'pv', 'uv' )
指定分割符为‘\t’,并且有三个列,分别命名为’pdate’, ‘pv’, ‘uv’。
原始数据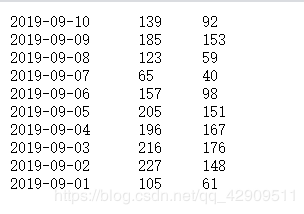
再将原始数据进行处理之后,制表符作为分割符,形成三列数据,名字分别为’pdate’, ‘pv’, ‘uv’。然后我们输出pvuv如图所示,是不是感觉很神奇。
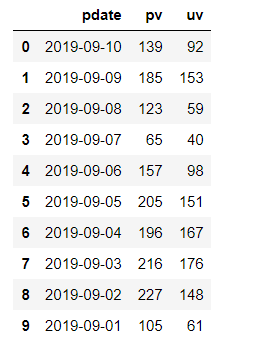
读取excel文件
fpath = "./datas/crazyant/access_pvuv.xlsx"
pvuv = pd.read_excel(fpath)
读取MySQL数据库
import pymysql
conn = pymysql.connect(
host='127.0.0.1',
user='root',
password='12345678',
database='test',
charset='utf8'
)
在我们安装完pymysql库之后,进行导入。然后通过connect方法进行连接。
- host=‘数据库IP地址,自己的电脑一般是localhost’
- user=‘数据库名’
- password=‘数据库的密码’
- database=‘要连接的数据库名’
- charset=’字符格式‘
连接之后,就可以使用read_sql()方法进行数据库语句的执行。
mysql_page = pd.read_sql("select * from crazyant_pvuv", con=conn)
mysql_page
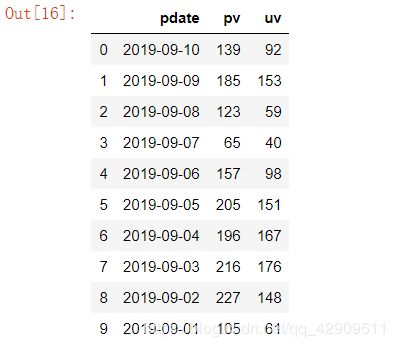
如果是要通过数据库进行一些操作,可以去专门学一下python使用数据库,有更加好规范的方法进行对数据库的操作。
结尾
欢迎大家指出不足,一起讨论,一起学习。