Deeplearning4j库学习
一、基础知识(了解)
背景知识:
如官网描述,dl4j-examples含有丰富的深度学习神经网络应用案例,这是一个为Java和Scala编写的首个商业级开源分布式深度学习库。DL4J与Hadoop和Spark集成,为商业环境(而非研究工具目的)所设计。Skymind是DL4J的商业支持机构。
Deeplearning4j的使用非常方便,它设计的目标是“即插即用”,通过更多预设的使用,避免太多配置,能够进行快速的原型制作。DL4J同时可以规模化定制。DL4J遵循Apache2.0许可协议,所以可以做其各种衍生产品。
Deeplearning4J Examples
Repository of Deeplearning4J neural net examples:
- MLP Neural Nets
- Convolutional Neural Nets
- Recurrent Neural Nets
- TSNE
- Word2Vec & GloVe
- Anomaly Detection
神经网络应用场景:
a.人脸/图像识别
b.语音搜索
c.文本到语音(转录)
d.垃圾邮件筛选(异常情况探测)
e.欺诈探测
f.推荐系统(客户关系管理、广告技术、避免用户流失)
g.回归分析
Deeplearning4j优点:
a.功能多样的N维数组类,为Java和Scala设计
b.与GPU集合
c.可在Hadoop、Spark上实现扩缩
d.Canova:机器学习库的通用向量化工具
e.ND4J:线性代数库,较Numpy快一倍
f.Deeplearning4j包括了分布式、多线程的深度学习框架,以及普通的单线程深度学习框架。定型过程以集群进行,也就是说,Deeplearning4j可以快速处理大量数据。神经网络可通过[迭代化简]平行定型,与Java、Scala和Clojure均兼容。Deeplearning4j在开放堆栈中作为模块组件的功能,使之成为首个为微服务架构打造的深度学习框架。
代码习得:(初步学习)
Deeplearning4j是一种用于配置深度多层神经网络的领域专用语言。首先都需要用MultiLayerConfiguration来设定网络的层及其超参数。
超参数是决定神经网络学习方式的变量,包括模型的权重更新次数、如何初始化权重、为节点添加哪些激活函数、使用哪些优化算法以及模型的学习速度。网络配置的示例如下:
JAVACopyMultiLayerConfiguration conf = new NeuralNetConfiguration.Builder()
.iterations(1)
.weightInit(WeightInit.XAVIER)
.activation("relu")
.optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT)
.learningRate(0.05)
// ……其他超参数
.backprop(true)
.build();
在Deeplearning4j中,添加一个层的方式是通过NeuralNetConfiguration.Builder()调用layer,指定其在所有层中的先后位置(下面示例中标记为零的层是输入层)、输入及输出节点数nIn和nOut,以及层的类型:DenseLayer。
JAVACopy.layer(0, new DenseLayer.Builder().nIn(784).nOut(250)
.build())
网络配置完成后,就可以用model.fit来定型模型了。
继续学习:
源码的下载地址:https://github.com/deeplearning4j/dl4j-examples
想要学习更多的知识可以访问:http://deeplearning4j.org/是其官方维护网站,上面有丰富的深度学习的教程(包括coursera教程)。
环境要求:
Jdk1.7或更高版本(本次实验选择1.8)
Eclipse Neon
Maven3.3.3及以上版本(本次实验选择3.3.9)
(相关安装教程网上都有,本次实验不再赘述)
实验步骤一:
1.初步简单编译实现:
本次实验一的目标是首先在linux(centos7)的环境中使用maven命令行的方式进行编译,并运行案例。
Build and Run
Use Maven to build the examples.
mvn clean package
Run the runexamples.sh script to run the examples (requires bash). It will list the examples and prompt you for the one to run. Pass the --all argument to run all of them. (Other options are shown with -h).
./runexamples.sh [-h | --help]日志及结果如下:

该实验过程简单,对初入门还不了解deeplearning4j是啥的同学,通过此次编译学习不仅学习了这种直接使用maven编译的方法,还可以对dl4j有个初步的了解。
该实验结果表明,编译过程因为需要maven从官网更新jar包,所以速度较慢,用时一个半小时左右,但运行的案例没有可视化界面,只能以文本的方式看到生成的实验结果。
实验步骤二:
1.导入maven项目,导入的过程不是一帆风顺的,如果maven没有安装好,会有maven的问题,还会有usr settings的问题出现,还会有缺少.dll文件路径依赖的问题出现。
莫慌,以上几个问题已经解决,如下:
a.缺少.dll文件的,到这里下载
http://dl.download.csdn.net/down11/20160808/df88eda72033f095833c6dc30085c479.rar?response-content-disposition=attachment%3Bfilename%3D%22DeepLearning4J_dll.rar%22&OSSAccessKeyId=9q6nvzoJGowBj4q1&Expires=1479646073&Signature=pv6BiwuHWQkIDN741zAm5OthcvA%3D
并添加到环境变量PATH中,版本的兼用性问题可以使用Dependency Walker
Dependency Walker官网:http://www.dependencywalker.com/
b.该重安装maven的就重安装,安装好了之后报几个项目的POM.xml文件的错,说maven-compiler-plugin.jar3.1,3.5.1参数拿不到,还有lifecircle有问题的,最后几个问题是settings.xml文件有问题的,经查找发现user settings文件缺省,打开windows-preference-maven-user settings,修改globalsettings的路劲为maven/conf路径下的settings.xml文件,并将其复制到user settings文件夹下,apply,ok后多次maven-update,后问题成功解决。
导入项目后目录如下,导入时间较长,请耐心等待,经验告诉我,如果没有任何设置,maven下载jar包都是从官网上下,国外服务器所以很慢。。。(一下午加一晚上),所以推荐设置私服的方法,如使用某个镜像站点,相关教程请百度:
首先我们做一个MLP的线性分类实验,该文件在如图位置:
找到训练文本所在目录,
根据实际情况设置目录,其代码该目录下有几个.csv都可以试一下
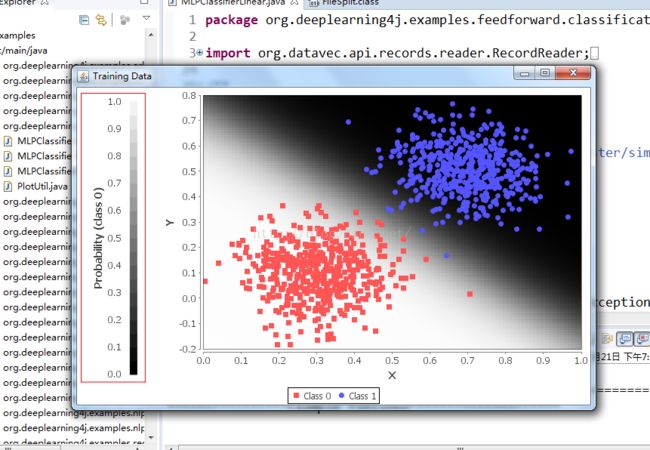
然后会弹出两个窗口,一个是训练数据的窗口:
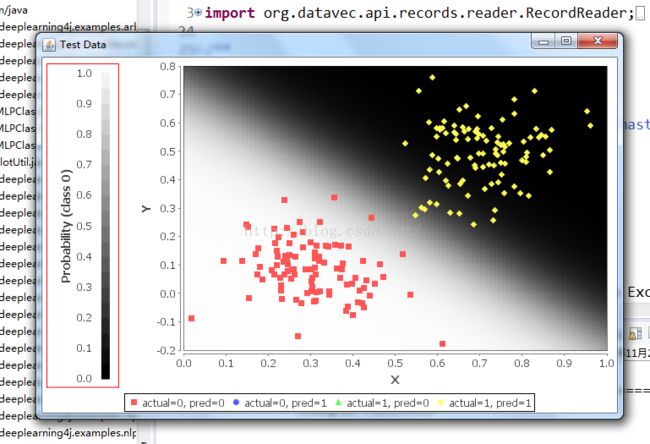
一个是测试数据的窗口,可以看到有清晰的线性聚类完毕。
然后是nlp的word2vec基于dl4j的实现,run如下:
其实现了一个网页版的word2vec的实现,端口是8080,安装了tomcat可以通过访问http://localhost:8080/(注意测试期间java项目要保持运行,否则会断开连接),web访问如下图所示:

清晰的看到这一个非常棒的ui界面,交互式体验,提交语料,生成模型,然后,便可以使用界面显示的几个功能查看其不同的可视化显示,同时该案例还展示了一个demo如下图:

是与day语义最相近的10个单词。
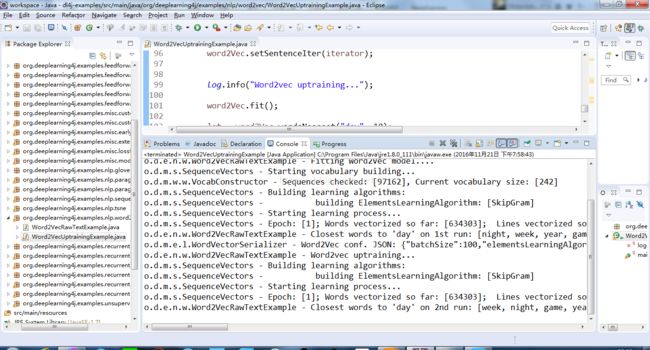
然后是不同训练次数下,生成的模型进行测试结果的对比实验,该案例在编写时分别训练了一次,两次,然后比较测试结果。
它是在初始词汇构建之后进行了模型权重更新的展示案例,也就是构建好了一个w2v模型后,这个模型还可以训练额外新的语料库,我们可以从这个案例中学到这种方法,但是要注意的是,本次案例中第二次训练没有新词被添加进语料库中,只有权重进行了更新,这种方法通常称为“冷词汇训练”。运行结果如下图所示,两次结果可以有一个对比,可以明显看到第二次要比第一次结果好很多。