数据库——SQL 上
目录
一、SQL查询语言概览
二、数据定义
2.1数据类型
2.2模式
2.2.1定义模式
2.2.2删除模式
2.3基本表
2.3.1定义基本表
2.3.2修改基本表
2.3.3删除基本表
2.4索引
2.4.1建立索引
2.4.2删除索引
一、SQL查询语言概览
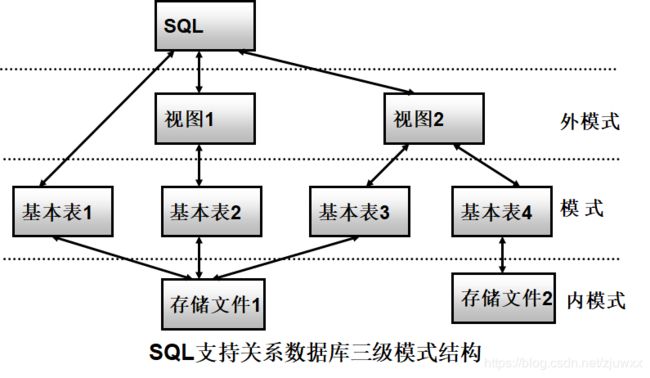
视图
- 从一个或几个基本表导出的表
- 数据库中只存放视图的定义而不存放视图对应的数据
- 视图是一个虚表
- 用户可以在视图上再定义视图
基本表
- 本身独立存在的表
- SQL中一个关系对应一个基本表
- 一个(或多个)基本表对应一个存储文件
- 一个表可以带若干索引
存储文件
- 逻辑结构组成了关系数据库的内模式
- 物理结构对用户是隐蔽的
二、数据定义

2.1数据类型
定义表的属性时需要指明其数据类型及长度
| 数据类型 |
含义 |
| char(n), character(n) |
长度为 n的定长字符串 |
| varchar(n), charactervarying(n) |
最大长度为 n的变长字符串 |
| clob |
字符串大对象 |
| blob |
二进制大对象 |
| Int, integer |
长整数(4字节) |
| smallint |
短整数(2字节) |
| bigint |
大整数(8字节) |
| numeric(p, d) |
定点数,由p位数字(不包括符号、小数点)组成,小数后面有d位数字 |
| decimal(p, d), dec(p, d) |
同 NUMERIC |
| real |
取决于机器精度的单精度浮点数 |
| double precision |
取决于机器精度的双精度浮点数 |
| float(n) |
可选精度的浮点数,精度至少为 n位数字 |
| boolean |
逻辑布尔量 |
| date |
日期,包含年、月、日,格式为 YYYY-MM-DD |
| time |
时间,包含一日的时、分、秒,格式为 HH:MM:SS |
| timestamp |
时间戳类型 |
| interval |
时间间隔类型 |
2.2模式
- 一个数据库中可以建立多个模式
- 一个模式下通常包括多个表、视图和索引等数据库对象
- 每一个基本表都属于某一个模式
2.2.1定义模式
定义模式实际上定义了一个命名空间,在这个空间中可以定义该模式包含的数据库对象,例如基本表、视图、索引等
create schema <模式名> [<模式元素>...]
/*
创建一个以<模式名>命名的模式,并可以在创建模式的同时为该模式创建或不创建模式元素
模式元素可以是表定义、视图定义、断言定义、授权定义等
该格式可在以后用授权语句向其他用户授权访问创建的模式
*/
--或
create schema [<模式名>] authorization <用户名> [<模式元素>...]
--将创建的模式授权于<用户名>指定的用户。当<模式名>缺省时,用<用户名>作为模式名例:为用户 Zhang创建了一个模式 test,并且在其中定义一个表 tab1
create schema test authorization Zhang;
create table tab1 (
col1 smallint,
col2 int,
col3 char(20),
col4 numeric(10,3),
col5 decimal(5,2)
);2.2.2删除模式
drop schema <模式名> cascade|restrict
cascade(级联)
--删除模式的同时把该模式中所有的数据库对象全部删除
restrict(限制)
--如果该模式中定义了下属的数据库对象(如表、视图等),则拒绝该删除语句的执行删除上例中建立的模式
drop schema zhang cascade;
--删除模式 Zhang,同时该模式中定义的表 tab1也被删除
2.3基本表
2.3.1定义基本表
create table <表名> (
<列名> <数据类型> [default <缺省值>] [列级约束定义],
<列名> <数据类型> [default <缺省值>] [列级约束定义],
...,
[<表级约束定义>, ..., <表级约束定义>]
);
--表名:基本表的名字
--列名:组成表的各个属性
--列级约束定义
[constraint <约束名>] <列约束>
--常用的列约束:
--not null:不允许该列取空值
--primary key:指明该列是主码,非空、唯一
--unique:该列上的值必须唯一,即该列为候选码
--check (<条件>):指明该列的值必须满足的条件,<条件>是一个涉及该列的布尔表达式
--表级约束定义
[constraint <约束名>] <列约束>
--常用的表约束:
--primary key (A1, ..., Ak):属性列 A1, ..., Ak构成该关系的主码。当主码只包括一个属性时,也可以用列级约束定义主码
--unique (A1, ..., Ak):属性列 A1, ..., Ak上的值必须唯一,即 A1, ..., Ak构成候选码。当候选码只包括一个属性时,也可以用列级约束定义主码
--check (<条件>):说明该表上的一个完整性约束条件,<条件>是一个涉及该表一个或多个列的布尔表达式
--foreign key (A1, ..., Ak) references <外表名> (<外表主码>) [<参照触发动作>]:属性 A1, ..., Ak是关系(表)的外码,<外表名>给出被参照关系的表名,<外表主码>给出被参照关系的主码,<参照触发动作>说明违反参照完整性时需要采取的措施
--如果完整性约束条件涉及到该表的多个属性列,则必须定义在表级上,否则既可以定义在列级也可以定义在表级例:建立一个“课程”表Course
create table Course (
Cno char(4) primary key, --Cno是该表的主码
Cname char(40),
Cpno char(4),
Ccredit smallint,
--primary key(Cname,Cpno), "Cname,Cpno共同构成了该表的主码"
foreign key (cpno) references course(cno)
);2.3.2修改基本表
alter table <表名>
[ add [column] <列名> <数据类型> [列级约束定义] ]
[ alter [column] <列名> {set default <缺省值>|drop default} ]
[ drop [ column ] <列名> {cascade|restrict} ]
[ add <表级约束定义>]
[ drop constraint <约束名> [cascade|restrict] ]
--add:增加新列、新的列级约束定义和表级约束定义
--drop column:删除表中的列
--cascade:自动删除引用了该列的其他对象
--restrict:如果该列被其他对象引用,关系数据库管理系统将拒绝删除该列
--drop constraint:删除指定的完整性约束条件
--alter column:修改原有的列定义,包括修改列名和数据类型2.3.3删除基本表
drop table <表名> [restrict|cascade]
--删除基本表导致存放在表中的数据和表定义都将被彻底删除
2.4索引
建立索引的目的:加快查询速度
2.4.1建立索引
--索引可以建立在该表的一列或多列上,各列名之间用逗号分隔
create [unique] [cluster] index <索引名>
on <表名> ( <列名> [<次序>], ..., <列名> [<次序>] )
--表名:要建索引的基本表的名字
--次序:指定索引值的排列次序,升序:ASC,降序:DESC。缺省值:ASC
--unique:此索引的每一个索引值只对应唯一的数据记录
--cluster:表示要建立的索引是聚簇索引例:为学生-课程数据库中的Student,Course,SC三个表建立索引。Student表按学号升序建唯一索引,Course表按课程号升序建唯一索引,SC表按学号升序和课程号降序建唯一索引
create unique index Student on student(sno);
create unique index Course on course(cno);
create unique index SC on sc(sno asc, cno desc);2.4.2删除索引
drop index <索引名>
--删除索引时,系统会删除索引结构,并从数据字典中删去该索引的定义