《TensorFlow深度学习应用实践》速成笔记与学习心得
因急于从零开始做一个TensorFlow项目,边看边记一下这本书里可用的内容。本文的内容是为看这本书不求甚解,能用即可,突击速成。如果有人也需要速成一个TensorFlow小项目,本文应该能帮你节约一点时间。
第1章 星星之火
讲的是计算机视觉的起源和深度学习的基本概念之类的,没啥好看的
第2章 Python的安装与使用
怎么装Python和pycharm,网上资料很多。突然讲threading类,目前没明白是啥。
第3章 深度学习的理论基础----机器学习
机器学习的分类
可以按学科、学习模式、应用领域分
机器学习的基本算法
讲得很详细,但对做项目没用
算法的理论基础
原理就是逼近,这个看看别的书扫一下盲就能懂
回归算法
线性回归高中知识,类比一下就行
决策树
人工智能书上有讲,算熵分节点。总之第3章内容是扫盲用的。
第4章 Python类库的使用----数据处理及可视化展示
机器学习建模的最终目标是求一个数字时,建模过程基本上可转化为回归问题。差别在是逻辑回归还是线性回归。
分类是逻辑回归,离散。预测一个是多少是线性回归,连续。
numpy的初步使用
numpy可以查查文档,这里简单了解就行
# 可以存储不同类型的数据,下标从0开始
data = np.mat(
[
[1,2,Flase],[2,4,Flase]
]
)
matplotlib包使用
可视化用的包,均是初步了解
深度学习理论方法----相似度计算
讲两个相似度公式,了解即可
数据统计学的可视化展示
四分位的概念,画个图展示,因为数值大小不一,就要标准化,介绍了一些标准化方法:0-1,Z-score。还有些别的图,要用的时候再查。
第5章OpenCV的基础使用
# OpenCV安装
pip install opencv-python
书上入门用很快,有时间也可以看看OpenCV官方文档。例子上的卷积用的是scipy库的,因为想做的项目用TensorFlow,而且TensorFlow的卷积更好学,所以这章没学。
第6章 OpenCV与TensorFlow的融合
颜色调整、裁剪、仿射等暂且不管,为了扩充数据集也就需要用一次,可以等到要用这些操作的时候再查
img = cv2.resize(dst,(h,w))# 对图像扩缩
img2 = img[up:down,left,right] # 对图像裁挖
第7章 Let’s play TensorFlow
TensorFlow游乐场,有个宏观认识。讲个了简单的回归程序和TensorFlow怎么工作的。记了一下一个最简单的TensorFlow程序的代码。
import numpy as np
import tensorflow as tf
inputX = np.random.rand(100) # x的值
inputY = np.multiply(3,inputX) + 1 # 实际的y值
weight = tf.Variable(0.25)
bias = tf.Variable(0.25)
y = tf.multiply(weight,inputX)+bias # 预测的y值
loss = tf.reduce_sum(tf.pow((y-inputY), 2))
train_step = tf.train.GradientDescentOptimizer(0.001).minimize(loss)
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
for i in range(1000):
sess.run(train_step)
if i % 50 == 0:
print("step:", i,"W:", sess.run(weight), "bias:", sess.run(bias))

第8章 Hello TensorFlow,从0到1
安装TensorFlow
安装TensorFlow,个人认为最方便的是用pip,无论是Windows、Linux或者是Mac
pip install tensorflow==2.0.0
# == 后面的版本号可以按需修改
常量、变量和数据类型
tf.constant()
tf.Variable()
# 要看数值需要sess.run()
TensorFlow矩阵计算
tf.constant([1,2,3], shape=[2,3]) # 2行3列矩阵
tf.random_normal(shape, mean =0.0, stddev=1.0,dtype=float32,seed=None,name=None)
# 有内置的一按些概率分布生成矩阵的函数
tf.diag()# 返回对角矩阵
tf.trace() # 迹
tf.matmul(a,b)
Hello TensorFlow(基础实例程序)
把下面的代码复制粘贴一下就能运行,可以在tensorboard里查看图和loss的每一步的结果(书里的学习率设置的很大,我这里设成0.25运行出来是错的,每步loss都变大,i刚到3的时候loss都1e157了,也可能与初始值随机得有关,不想去管为什么,所以直接设置成0.00001)
(更新:为什么把学习率设置得那么小?因为我没有用placeholder,第11章说批量输入时一次太多会出错)
import tensorflow as tf
import numpy as np
inputX = np.random.rand(3000,1)
noise = np.random.normal(0,0.05,inputX.shape)
inputY = inputX*4 + 1 + noise
print(inputX.shape[0], inputX.shape[1])
# 3000 * 1 matmul 1 * 4 = 3000 * 4
with tf.name_scope("layer_1"):
weight1 = tf.Variable(np.random.rand(inputX.shape[1], 4))
bias1 = tf.Variable(np.random.rand(inputX.shape[1], 4))
#x1 = inputX
y1_ = tf.matmul(inputX, weight1) + bias1
# 3000 * 4 matmul 4 * 1 = 3000 * 1 隐藏层
with tf.name_scope("layer_2"):
weight2 = tf.Variable(np.random.rand(4, 1))
bias2 = tf.Variable(np.random.rand(inputX.shape[1], 1))
y2_ = tf.matmul(y1_, weight2) + bias2
loss = tf.reduce_mean(tf.reduce_sum(tf.square( (y2_ - inputY) )))
train = tf.train.GradientDescentOptimizer(0.00001).minimize(loss)# 梯度下降,学习率0.00001
init = tf.global_variables_initializer()
# 为了在tensorboard里看loss变化的图
tf.summary.scalar('loss', loss)
merged_summaries=tf.summary.merge_all()
sess = tf.Session()
sess.run(init)
writer = tf.summary.FileWriter('./hidelayer', graph=tf.get_default_graph())
for i in range(1000):
sess.run(train)
summary = sess.run(merged_summaries)
writer.add_summary(summary, global_step = i)# 把每步的loss写进去
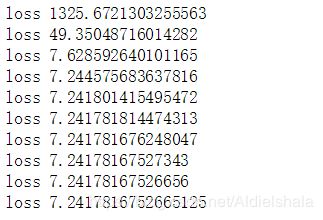
if i % 100 == 0:
#print( "weight1:", sess.run(weight1), "weight2:", sess.run(weight2),
# "bias1:", sess.run(bias1),"bias2", sess.run(bias2) )
print("loss",sess.run(loss))
sess.close()

第9章 TensorFlow重要算法基础
BP神经网络介绍
讲BP的历史和发展,没啥好看的
BP神经网络中的两个基础算法
- 最小二乘法
讲了原理,高中知识,用numpy实现了,可以锻炼代码能力,加深算法理解。 - 梯度下降算法
梯度,大一知识,梯度下降算法,大二知识。用TensorFlow就是一行代码。
TensorFlow实战----房屋价格的计算
又到一个例子了,这个例子比之前的都要好,因为这个例子在讲“怎么做”和“为什么这样”,不像前面一样直接给代码,值得一看。
- 数据收集
需要有数据,没有数据就没法训练 - 模型建立与计算
选模型(线性?指数?),就是选要拟合的函数,函数没选好,事倍功半。然后用最小二乘法拟合。 - TensorFlow程序设计
讲了如何一步一步写程序。这里也是,学习率设成0.00001都不行,还要更小,而且我的w和b的结果都是一样的。。不知道为什么,先记录在这。
import tensorflow as tf
import numpy as np
# 数据集
xs = np.random.randint(46,99,100)# 46 ~ 99 100个
ys = 1.7 * xs
# 参数
w = tf.Variable(0.1)
b = tf.Variable(0.0)
# 模型与算法,算法是梯度下降
y_ = tf.multiply(w,xs) + b # 预测值,也就是模型
loss = tf.reduce_sum(tf.pow(ys - y_ , 2))
train = tf.train.GradientDescentOptimizer(0.0000001).minimize(loss)# 梯度下降
# 变量(参数)初始化,并将loss显示在tensorboard里
init = tf.global_variables_initializer()
tf.summary.scalar('loss', loss)
merged_summaries=tf.summary.merge_all()
sess = tf.Session()
sess.run(init)
writer = tf.summary.FileWriter('./predict_house', graph=tf.get_default_graph())
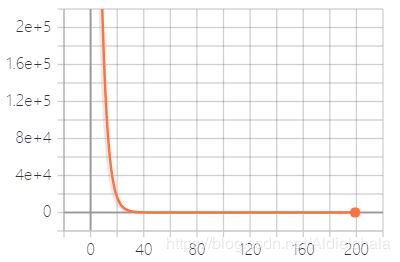
for i in range(200):
sess.run(train)
summary = sess.run(merged_summaries)
writer.add_summary(summary, global_step = i)# 把每步的loss写进去
if i % 100 == 0:
print("loss",sess.run(loss))
print("w:", sess.run(w), "b:",sess.run(w))
sess.close()
反馈神经网络反向传播算法
这章推导反向传播,和用numpy写代码实现,没看。值得看,但因为没时间就没看。
第10章 TensorFlow数据的生成和读取详解
TensorFlow的队列
q = tf.FIFOQueue(3,"float") # 容量为3
init = q.enqueue_many(([0.1,0.2,0.3], ))# 一次填3个
sess.run(init)
print(sess.run( q.dequeue() ))
读文件:
- 从磁盘读数据名称和路径
- 文件名入队
- 出队读文件数据
- decoder解码数据
- 数据输入样本队列
CSV文件的创建与读取
CSV文件纯文本存储
CSV文件的创建
创建CSV文件目的是对要加载的文件地址和标签进行记录
import os
path='figure_data'
filename=os.listdir(path)
strText=""
with open("train_list.csv", "w") as fid:
for a in range(len(filename)):
# 这里根据自己数据集和需求写
strText = path+os.sep+filename[a] + ","+filename[a].split('_')[1].split('.')[0]+"\n"
fid.write(strText)
fid.close()
CSV文件的读取
image_add_list=[]
image_label_list=[]
with open("train_list.csv") as fid:
for image in fid.readlines():
image_add_list.append(image.strip().split(",")[0])
image_label_list.append(image.strip().split(",")[1])
TensorFlow文件的创建与读取
TFRecord是TensorFlow专门的文件格式,只学如何保存图片文件,因为只用图片文件
创建TFRecord
# 制作好CSV文件后,制作TFRecord
import tensorflow as tf
import cv2 as cv
from PIL import Image
image_add_list=[]
image_label_list=[]
with open("train_list.csv") as fid:
for image in fid.readlines():
image_add_list.append(image.strip().split(",")[0])
image_label_list.append(image.strip().split(",")[1])
for a in range(len(image_add_list)):
image_label_list[a]=int(image_label_list[a])
writer = tf.python_io.TFRecordWriter("train.tfrecord")
for a in range(len(image_add_list)):
img_path=image_add_list[a]
img = Image.open(img_path)
img_raw = img.tobytes()
example = tf.train.Example(features=tf.train.Features(feature={
"label":tf.train.Feature(int64_list=tf.train.Int64List(value=[image_label_list[a]])),
'image':tf.train.Feature(bytes_list=tf.train.BytesList(value=[img_raw]))
}))
writer.write(example.SerializeToString())
读取TFRecord
# 已有TFRecord文件
# 搞了几个小时没搞明白,总是报要用tf.data,不要用老的包的错,不搞了
看后面的总结说CSV文件是传统训练方式,TFRecord是TensorFlow专门的方式,各有优缺点。用CSV做慢点就慢点,反正小项目数据量不是很大。。
第11章 回归分析----从TensorFlow陷阱与细节开始
讲了些细节问题,最好还是用placeholder,由批量输入变成逐个输入。之前就犯了这样的错误。
逐个输入for (x,y) in zip(x_, y_)
批量输入没有上面的那行
逻辑回归输出是离散值,要做的项目是连续值,没看。但逻辑回归把二维当一维处理,用flatte进行一维变换。
第12章 MNIST手写体识别
没看,CNN留着要用再看。
第13章 卷积神经网络原理
基本概念
没看概念,直接看代码
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, name=None)
# input 图像,[batch, height,width,channel]要float32或64
# filter 卷积核,[filter_height, width, in_channels, out_channels] 用variable定义
# strides [1, 平行,垂直滑动步长, 1]
# padding "SAME" "VALID"
# 默认true
filter = tf.Variable(tf.ones([7,7,3,1])) # 7*7 可以提取边缘特征
tf.nn.max_pool(value, ksize, strides, padding, name=None)
# [batch, height,width,channel]这种输入,一般是卷积后接池化
# [1, height, width, 1] batch 和 channel不做池化
# strides [1, 平行,垂直滑动步长, 1]
# padding "SAME" "VALID"
卷积与池化可能导致欠拟合
卷积神经网络的结构详解
- 输入层
- 卷积层
- max_pool
- 全连接层
LeNet5网络可以识别手写体数字,训练分前向和反向。
TensorFlow实现LeNet
没看
第14章 卷积神经网络公式推导与应用
没看
第15章 猫狗大战----实战AlexNet
整章都在讲AlexNet做猫狗分类,看到这里就没再往下看了。
总结与心得
看到此处,已经基本知道做一个项目应该怎么做了。
- 首先明确问题类型,是一个分类问题(离散)还是一个回归问题(连续)
- 接下来就是要找数据,搞深度学习项目没有大量数据是不行的(除非像例子里的那种回归问题,自己造一二十个数据)
- 然后就是搭建环境找个网络结构,输入输出数据准备好,就可以梭哈了(不求甚解,只求做出结果
关于搭建Python和TensorFlow环境,Ubuntu,Mac,Windows我都配过,最简单的方法就是:
- 下载并安装Python,Ubuntu自带,Mac要装command line tools还是brew忘了,Windows直接去Python官网下载。最好装3.6以上版本,因为3.5很多包不支持了,2.x也要淡出历史的舞台了。建议不要安装anaconda,一直不明白搞个anaconda是干啥的,上来就装那么多包,经过自己和同学的实践发现,并不会用到那么多包,而且我之前在Ubuntu下都因为anaconda搞出一些莫名其妙的错误。
- 由于不用anaconda,那么就需要pip安装各种包,这时就需要pip换成国内源,建议换成清华源。
- 然后就是安装各种包,TensorFlow会自动下载版本相适应的numpy,要用其他包时再在命令行里输入下载就行。
pip install tensorflow==1.0.0
//这里随便输个数字就行,因为不知道输入命令时有什么版本能用,看报错信息就知道能下载什么版本
//为什么要选择下载版本?因为下最新版的话,搬运教科书的代码运行会出问题 :-)
- 接下来就是写要求的代码运行了。
再次说明,本文只为突击速成,学习不可抱突击态度,否则花了多长的时间突击,就会花更少的时间遗忘。比如我现在写完本文的时候,已经忘得差不多了。