zookeeper原理篇-Zookeeper会话机制
前言
上篇文章我们学习了Zookeeper的选举流程和FastLeaderElection选举算法的实现过程,了解了Zookeeper从初始化开始到选举的过程,本篇文章我们开始研究Zookeeper中的会话机制体系
会话
在Zookeeper中,会话是个很重要的概念之一,客户端与服务端之间的任何交互操作都和会话息息相关,其中包含zookeeper的临时节点的生命周期、客户端请求执行以及Watcher通知机制等。接下来,我们从全局的会话状态变化到创建会话再到会话管理三个方面来看看Zookeeper是如何处理会话相关的操作
会话状态
客户端需要与服务端创建一个会话,这个时候客户端需要提供一个服务端地址列表,“ host1 : port,host2: port ,host3:port ” ,根据地址开始创建zookeeper对象,这个时候客户端的状态则变更为CONNECTION,同时客户端会根据上述的地址列表,按照顺序的方式获取IP来尝试建立网络连接,直到成功连接上服务器,这个时候客户端的状态就可以变更为CONNECTED。在zookeeper服务端提供服务的过程中,有可能遇到网络波动等原因,导致客户端与服务端断开了连接,这个时候客户端会进行重新连接操作,这个时候的状态为CONNECTION,当连接再次建立后,客户端的状态会再次更改为CONNECTED,也就是说只要在zookeeper运行期间,客户端的状态总是能保持在CONNECTION或者是CONNECTED。当然在建立连接的过程中,如果出现了连接超时、权限检查失败或者是在建立连接的过程中,我们主动退出连接操作,这个时候客户端的状态都会变成CLOSE状态。
会话创建
Session
Session是Zookeeper中会话的实例载体,一个Session则是指代一个客户端会话。一个会话必须包含以下几个基本的属性:
-
SessionID : 会话的ID,用来唯一标识一个会话,每一次客户端建立连接的时候,Zookeeper服务端都会给其分配一个全局唯一的sessionID
-
TimeOut:一次会话的超时时间,客户端在构造Zookeeper实例的时候,会配置一个sessionTimeOut参数用于指定会话的超时的时间。Zookeeper服务端会按照连接的客户端发来的TimeOut参数来计算并确定超时的时间
-
TickTime:下一次会话超时的时间点,为了方便Zookeeper对会话进行所谓的分桶策略进行管理,同时也可以实现高效的对会话的一个检查和清理。TickTime是一个13位的Long类型的数值,一般情况下这个值接近TimeOut,但是并不完全相等
-
isCloseing:用来标记当前会话是否已经处于被关闭的状态。如果服务端检测到当前会话的超时时间已经到了,就会将isCloseing属性标记为已经关闭,这样以后即使再有这个会话的请求访问也不会被处理
SessionID
SessionID作为一个全局唯一的标识,我们可以来探究下Zookeeper是如何保证Session会话在集群环境下依然能保证全局唯一性的:
在sessionTracker初始化的时候,会调用initializeNextSession来生成session,算法大概如下:
1. `public s ta tic long initializeNextSession(long id) {`
2. `long nextSid = 0;`
3. `nextSid = (System.currentTim eM illis() « 24) » 8;`
4. `nextSid = nextSid | (id « 56);`
5. `return nextSid;`
6. `}
}`
从这段代码,我们可以看到session的创建大概分为以下几个步骤:
1.获取当前时间的毫秒表示
我们假设当前System.currentTimeMills()获取的值是1380895182327,其64位二进制表示为:
00000000 00000000 00000001 01000001 10000011 11000100 01001101 11110111
2.接下来左移24位,我们可以得到结果:
01000001 100000011 11000100 01001101 11110111 00000000 00000000 00000000,可以看到低位已经把高位补齐,剩下的低位都使用了0补齐
3.右移8位,结果变成了:
00000000 01000001 100000011 11000100 01001101 11110111 00000000 00000000
4.计算机器码标识ID:
在initializeNextSession方法中,出现了一个id变量,这个变量就是生成的SID的值,而SID在部署的时候就是我们在myid中配置的值,一般是一个整数,假设此时的值为2,转为64位二进制表示:
00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000010
此时发现高位几乎都是0,进行左移56位以后,得到值如下:
00000010 00000000 00000000 00000000 00000000 00000000 00000000 00000000
5.将前面第三步和第四步得到的结果进行 | 操作:
可以得到结果为:
00000010 01000001 10000011 11000100 01001101 11110111 00000000 00000000
这个时候我们可以得到一个单机中唯一的序列号ID,整个算法大概可以理解为,先通过高8位确定机器以后,后面的56位按照毫秒进行随机,可以看出来当前的算法!还是蛮严谨的,基本上看不出来什么明显的问题,但是其实也有问题的,其中我们可以看到,zk选择了当前机器时间内的毫秒作为基数,但是如果时间到了2022年4月8号以后, System . currentTimeMillis ()的值会是多少呢?
1. `Date d = newDate(2022-1900 f 3,8);`
2. `System. out. p rin tln ( Long. toBinaryString(d .getTime()));`
打印出来的结果为:
1. `0000000000000000000000011000000000000100110000010000010000000000`
接着我们左移24位以后会发现,这个时候的值依然是个负数,所以我们为了保证不会出现负数的情况,解决方案如下:
1. `publicstaticlong initializeNextSession(long id { ) {`
2. `long nextSid = 0;`
3. `nextSid = (System.currentTim eM illis() « 24) > » 8;`
4. `nextSid = nextSid | (id « 56);`
5. `return nextSid;`
6. `} }`
这样就可以避免生成的时候出现负数了
SessionTracker
SessionTracker是Zookeeper中的会话管理器,负责整个zk生命周期中会话的创建、管理和清理操作,而每一个会话在Sessiontracker内部都保留了三份,大体如下:
1.sessionsWithTimeout这是一个ConcurrentHashMap
2.sessionsById是一个HashMap
3.sessionsSets同样也是一个HashMap
会话创建
创建会话的过程,大体可以分为几个步骤,分别是处理ConnectRequest请求、创建会话、处理器链路处理和响应,在zk服务端中,首先是NIOServerCnxn来负责接受来自客户端的会话创建请求,并且进行反序列化工作,然后开始分配超时时间。分配完毕后,会开始创建sessionId,并且将其注册到SessionsById和sessionsWithTimeOut,进行激活,这个时候就可以考虑处理流转。
会话管理
Zookeeper中的会话管理主要是SesssionTracker负责的,内部使用了一个特殊的机制,称之为分桶策略,所谓分桶策略,其实是将类似的会话放在一个区块中进行管理,以便于zookeeper对会话进行不同区块的隔离以及同一区块的统一处理
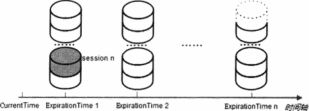
从图中我们可以看到,所有的会话都分配在了不同的区块中,分配原则是每个会话的下个超时的时间点,ExpiractionTime是指最近一次可能过期的时间点,每一个会话的ExpiractionTime的计算方式如下:
ExpiractionTime = CurrentTime + SessionTimeout
但是不要忘记了,Zookeeper的Leader服务器在运行期间会定期检查是否超时,这个定期的时间间隔为ExpiractionInterval,单位是秒,默认情况下是tickTime的值,即2000毫秒进行一次检查,完整的ExpiractionTime的计算方式如下:
1. `ExpirationTime_= CurrentTime+ SessionTimeout;`
2. `ExpirationTime= (ExpirationTime_/ Expirationlnterval+ 1) x Expirationlnterval;`
会话激活
同样的,在整个zookeeper运行过程中,客户端会在超时时间内向服务端发送PING请求来保持时效性,俗称心跳检测,而服务端在接受到了客户端的心跳请求后需要再次激活会话状态,这个过程称之为TouchSession,流程如下:
1.检验会话是否已经被关闭,Leader会去检查会话是否被关闭,如果已经关闭,不会再去激活该会话
2.如果会话没有被关闭,则开始计算下一次的超时时间Expiration_New,而计算的过程则是使用上面的公式
3.计算完新的超时时间以后,会去获取会员原来的超时时间,并且根据时间来定位原来存放的区块
4.接着,从该区块中找到会话,进行会话迁移,放入新的Expiration_New对应的区块中,如图所示:
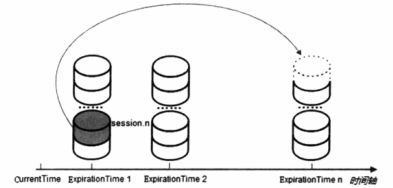
经过以上的步骤,基本已经完成了会话的激活,而每一次心跳的检测,则是进行了一次会话激活操作,在整个Zookeeper运行过程中,一般如下两个操作才会导致会话激活:
1.当客户端向服务端发送请求的时候,包括读写请求,都会主动触发一次会话激活
2.如果客户端在sessionTimeOut / 3时间范围内尚未和服务器之间进行通信,即没有发送任何请求,就会主动发起一个PING请求,去触发服务端的会话激活操作
除此之外,由于会话之间的激活是按照分桶策略进行保存的,因此我们可以利用此策略优化对于会话的超时检查,在Zookeeper中,会话超时检查也是由SessionTracker负责的,内部有一个线程专门进行会话的超时检查,只要依次的对每一个区块的会话进行检查,由于分桶是按照ExpriationInterval 的倍数来进行会话分布的,因此只要在这些时间点检查即可,这样可以减少检查的次数,并且批量清理会话,实现较高的效率。
会话清理
会话检查操作以后,当发现有超时的会话的时候,会进行会话清理操作,而Zookeeper中的会话清理操作,主要是以下几个步骤:
1.由于会话清理过程需要一定的时间,为了保证在清理的过程中,该会话不会再去接受和处理发来的请求,因此,在会话检查完毕后,SessionTracker会先将其会话的isClose标记为true,接着为了保证在进行会话关闭的过程中,在整个集群中都生效,Zookeeper使用了提交的方式,交给PreRequestProcessor处理器进行处理
2.在某个会话失效后,这个会话创建的相关临时节点列表都应该被删除,因此在删除会话之前,需要先找到与改会话相对应的临时节点列表,在Zookeeper的内存数据库中,会为每一个会话单独保存一份由该会话维护的临时节点集合,但是我们需要考虑一些特殊情况,例如在删除会话的时候,有没处理完毕的删除节点的请求,而这个被删除的节点刚好又是会话对应的临时节点,或者这个时候正在处理临时节点创建的请求,而且也是当前会话的请求。这个时候我们必须考虑处理方案,防止出现数据不一致的情况,而第一种情况,则是防止重复删除,我们只需要先把请求对应的节点删除,再去删除对应的列表即可,而第二种情况,我们也需要先执行添加节点的请求,保证节点不会出现删除遗漏即可。
3.当会话对应的临时节点列表找到后,Zookeeper会将列表中所有的节点变成删除节点的请求,并且丢给事物变更队列OutStandingChanges中,接着FinalRequestProcessor处理器会触发删除节点的操作,从内存数据库中删除。
4.当会话对应的临时节点被删除以后,就需要将会话从SessionTracker中移除了,主要从SessionById,sessionsWithTimeOut以及sessionsSets中将会话移除掉,当一切操作完成后,清理会话操作完成,这个时候将会关闭最终的连接NioServerCnxn。
会话重连
在Zookeeper运行过程中,也可能会出现会话断开后重连的情况,这个时候客户端会从连接列表中按照顺序的方式重新建立连接,直到连接上其中一台机器为止,这个时候可能出现两种状态,一种是正常的连接CONNECTED,这种情况是Zookeeper客户端在超时时间内连接上了服务端,而超时以后才连接上服务端的话,这个时候的客户端会话状态则为EXPIRED,被视为非法会话。
而在重连之前,可能因为其他原因导致的断开连接,即CONNECTION_LESS,会抛出异常org.apache.zookeeper.KeeperException$ConnectionLossException,我们需要捕获异常,并且在重连成功后,收到None-SyncConnection通知里面进行setData的处理操作即可。而在这个过程中,会话可能会出现两种情况:
会话失效:SESSION_EXPIRED
会话失效一般发生在ConnectionLoss期间,客户端尝试开始重连,但是在超时时间以后,才与服务端建立连接的情况,这个时候服务端就会通知客户端当前会话已经失效,我们只能选择重新创建一个会话,进行数据的处理操作
会话转移:SESSION_MOVED
会话转移也是在重连过程中常发生的一种情况,例如在断开连接之前,会话是在服务端A上,但是在断开连接重连以后,最终与服务端B重新恢复了会话,这种情况就称之为会话转移。而会话转移可能会带来一个新的问题,例如在断开连接之前,可能刚刚发送一个创建节点的请求,请求发送完毕后断开了,很短时间内再次重连上了另一台服务端,这个时候又发送了一个一样的创建节点请求,这个时候一样的事物请求可能会被执行了多次。因此在Zookeeper3.2版本开始,就有了会话转移的概念,并且封装了一个SessionMovedExection异常出来,在处理客户端请求之前,会检查一遍,请求的会话是不是当前服务端的,如果不存在当前服务端的会话,会直接抛出SessionMovedExection异常,当然这个时候客户端已经断开了连接,接受不到服务端的异常响应了。