dex文件格式
dex文件格式
Android 4.0源码Dalvik/docs目录下文档dex-format.html有详细介绍dex文件格式
1.dex文件中的数据结构

dex文件使用到的数据类型
- u1~u8表示1到8字节的无符号数,而sleb128、uleb128与uleb128p1则是dex文件中特有的LEB128数据类型。
- 每个LEB128由1~5个字节组成,所有的字节组合在一起表示一个32位的数据。
- LEB128,每个字节只有7位为有效位,如果第1个字节的最高位为1,表示LEB128需要使用到第2个字节,如果第2个字节的最高位为1,表示会使用到第3个字节,以此类推,直到最后的字节最高位为0,当然,LEB128最多只会使用到5个字节,如果读取5个字节后下一个字节最高位仍为1,则表示该dex文件无效,Dalvik虚拟机在验证dex时会失败返回。

Android源码dalvik\libdex\Leb128.h文件中可以找到LEB128的实现,读取无符号LEB128(uleb128)数据的代码:
DEX_INLINE int readUnsignedLeb128(const ul** pStream){
const ul* ptr=*pStream;
int result=*(ptr++);
if(result>0x7f){ //大于0x7f表示第1个字节最高位为1
int cur=*(ptr++); //第2个字节
result=(result&0x7f)|((cur&0x7f)<<7);//前2个字节组合
if(cur>0x7f){ //大于0x7f表示第2个字节最高位为1
cur=*(ptr++); //第3个字节
result|=(cur&0x7f)<<14; //前3个字节的组合
if(cur>0x7f){
cur=*(ptr++); //第4个字节
result|=(cur&0x7f)<<21;//前4个字节的组合
if(cur>0x7f){
cur=*(ptr++); //第5个字节
result|=cur<<28;//前5个字节的组合
}
}
}
}
*pStream=ptr;
return result;
}对于有符号的LEB128(sleb128)来说,计算方法与无符号的LEB128是一样的,只是对无符号LEB128最后一个字节的最高有效位进行了符号扩展。读取有符号LEB128数据的代码如下:
DEX_INLINE int readSignedLeb128(const ul** pStream){
const ul* ptr=*pStream;
int result=*(ptr++);
if(result<=0x7f){ //小于0x7f表示第1个字节的最高位不为1
result=(result<<25)>>25; //对第1个字节的最高有效位进行符号扩展
}else{
int cur=*(ptr++); //第2个字节
result=(result&0x7f)|((cur&0x7f)<<7);//前2个字节组合
if(cur<=0x7f){
result=(result<<18)>>18;//对结果进行符号位扩展
}else{
cur=*(ptr++); //第3个字节
result|=(cur&0x7f)<<14; //前3个字节的组合
if(cur<=0x7f){
result=(result<<11)>>11;//对结果进行符号位扩展
}else{
cur=*(ptr++); //第4个字节
result|=(cur&0x7f)<<21;//前4个字节的组合
if(cur<=0x7f){
result=(result<<4)>>4;//对结果进行符号位扩展
}else{
cur=*(ptr++); //第5个字节
result|=cur<<28;//前5个字节的组合
}
}
}
}
*pStream=ptr;
return result;
}uleb128p1类型很简单,值为uleb128的值加1。
c0 83 92 25计算uleb128值:
第1个字节0xc0大于0x7f,表示需要用到第2个字节。result=0xc0&0x7f
第2个字节0x83大于0x7f,表示需要用到第3个字节。result2 = result1 + (0x83 & 0x7f) << 7
第3个字节0x92大于0x7f,表示需要用到第4个字节。result3 = result2 + (0x92 & 0x7f) << 14
第4个字节0x25小于0x7f,表示到了结尾。result4 = result3 + (0x25 & 0x7f) << 21
最后计算结果为0x40 + 0x180 + 0x48000 + 0x4a00000 = 0x4a481c0
2.dex文件整体结构
dex文件由多个结构体组合而成。

- dex header:dex文件头,它指定了dex文件的一些属性,并记录了其它6部分数据结构在dex文件中的物理偏移
- string_ids到class_def结构为“索引结构区”,真实的数据存放在data数据区
- link_data:静态链接数据区
未经过优化的dex文件结构:
struct DexFile{
DexHeader Header;
DexStringId StringIds[stringIdsSize];
DexTypeId TypeIds[typeIdsSzie];
DexProtoId ProtoIds[protoIdsSize];
DexFieldId FieldIds[fieldIdsSize];
DexMethodId MethodIds[methodIdsSize];
DexData Data[];
DexLink LinkData;
};(DexFile结构的声明在Android系统源码dalvik\libdex\DexFile.h文件中的,是dex文件被映射到内存中的结构,保存的是各个结构的指针,其中还包括了DexOptHeader与DexFile尾部的附加数据)
- DexHeader结构占用0x70个字节

- 70个字节解释如下:
- magic字段标识了一个有效的dex文件,值固定为
64 65 78 0a 30 33 35 00,转换为字符串为dex.035 - checksum段为dex文件的校验和,通过它来判断dex文件是否被损坏或篡改。
- signature字段用来识别最佳化之前的dex文件
- fileSize字段记录了包括DexHeader在内的整个dex文件的大小
- headerSize字段记录了DexHeader结构本身占用的字节数,目前它的值为0x70。
- endianTag字段指定了dex运行环境的cpu字节序,预设值ENDIAN_CONSTANT等于0x12345678,表示默认采用Little-Endian字节序
- linkSize字段与linkOff字段指定链接段的大小与文件偏移,大多数情况下它们的值都为0。
- mapOff字段指定了DexMapList结构的文件偏移
- 接下来的字段分别表示DexStringId、DexTypeId、DexProtoId、DexFieldId、DexMethodId、DexClassDef以及数据段的大小与文件偏移。
- magic字段标识了一个有效的dex文件,值固定为
- 70个字节解释如下:
- DexHeader结构下面的数据为”索引结构区“与”数据区“
- “索引结构区”中各数据结构的偏移地址都是从DexHeader结构的stringIdsOff~classDefsOff字段的值指定的,它们并非真正的类数据,而是指向dex文件的data数据区(DexData字段,实际上是ubyte字节数组,包含了程序所有使用到的数据)的偏移或数据结构索引。
3.dex文件结构分析
Dalvik虚拟机解析dex文件的内容,最终将其映射成DexMapList数据结构。
- DexHeader结构的mapOff字段指明了DexMapList结构在dex文件中的偏移:
struct DexMapList{
u4 size; //DexMapItem的个数
DexMapItem list[1]; //DexMapItem结构
};
//size字段表示接下来有多少个DexMapItem结构
//DexMapItem的结构如下:
struct DexMapItem{
u2 type; //kDexType开头的类型
u2 unused; //未使用,用于字节对齐
u4 size; //指定类型的个数
u4 offset; //指令类型数据的文件偏移
};- type字段为一个枚举常量,通过类型名称很容易判断具体类型:

DexMapItem中的size字段指定了特定类型的个数,它们以特定的类型在dex文件中连续存放。
offset为该类型的文件起始偏移地址。
以Hello.dex为例,DexHeader结构的mapOff字段值为0x290,读取0x290处的一个双字值为0x0d,表明接下来会有13个DexMapItem结构。使用任意的十六进制编辑器打开Hello.dex,我使用的是winhex
//Hello.java public class Hello { public int foo(int a, int b) { return (a + b) * (a - b); } public static void main(String[] argc) { Hello hello = new Hello(); System.out.println(hello.foo(5, 3)); } }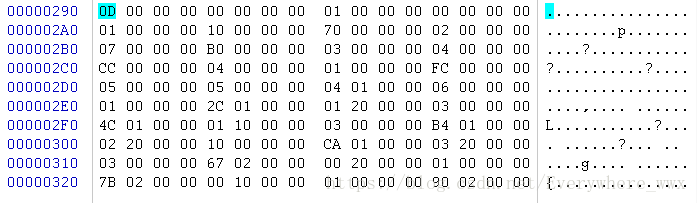
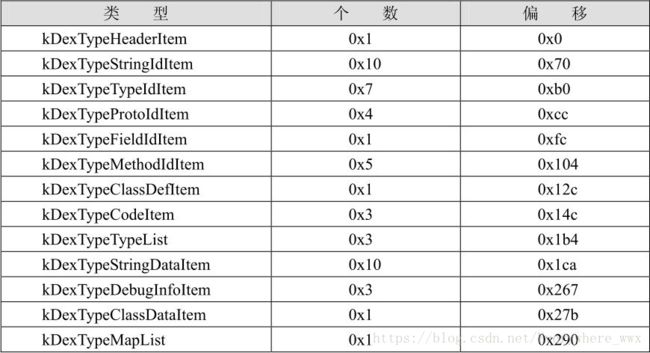
根据结构描述,可以整理出13个DexMapItem结构如表:

对比文件头DexHeader部分:
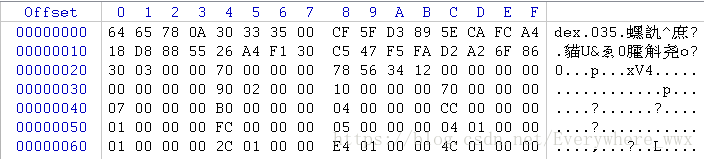
kDexTypeHeaderItem描述了整个DexHeader结构,它占用了文件的前0x70个字节的空间,而接下来的kDexTypeStringIdItem~kDexTypeClassDefItem与DexHeader当中对应的类型及类型个数字段的值是相同的。kDexTypeHeaderItem
kDexTypeHeaderItem描述了整个DexHeader结构,它占用了文件的前0x70个字节的空间
kDexTypeStringIdItem
- 比如kDexTypeStringIdItem对应了DexHeader的stringIdsSize与stringIdsOff字段,表明了在0x70偏移处,有连续0x10个DexStringId对象。
//DexStringId结构声明 struct DexStringId{ u4 stringDataOff; //字符串数据偏移 };DexStringId结构只有一个stringDataOff字段,直接指向字符串数据,从0x70开始,整理16个字符串。


上表中的字符串并非普通的ascii字符串,它们是由MUTF-8编码来表示的。MUTF-8含义为Modified UTF-8,即经过修改的UTF-8编码,它与传统的UTF-8很相似,但有以下几点区别:
- MUTF-8使用1~3字节编码长度。
- 大于16位的Unicode编码U+10000~U+10ffff使用3字节来编码。
- U+0000采用2字节来编码。
- 采用类似于C语言中的空字符null作为字符串的结尾。
MUTF-8可表示的有效字符范围有大小写字母与数字、“$”、“-”、“_”、U+00a1~U+1fff、U+2010~U+2027、U+2030~U+d7ff、U+e000~U+ffef、U+10000~U+10ffff。它的实现代码如下:
DEX_INLINE const char* dexGetStringData(const DexFile* pDexFile,const DexStringId* pStringId){ const u1* ptr=pDexFile->baseAddr+pStringId->stringDataOff; //指向MUTF-8字符串的指针 //Skip the uleb128 length. while(*(ptr++)>0x7f) /*empty*/; return (const char*) ptr; }MUTF-8字符串的头部存放的是由u1eb128编码的字符的个数。注意:这里是个数,如字符序列“
02 e4 bd a0 e5 a5 bd 00”头部的02即表示字符串有两个字符,“e4 bd a0”是UTF-8编码字符“你”,“e5 a5 bd”是UTF-8编码字符“好”,而最后的空字符0表示字符串结尾,不过字符个数好像没有算上它。eg:
0A 48 65 6C 6C 6F 2E 6A 61 76 61 00=>10个字符+hello.java+00
kDexTypeTypeIdItem
kDexTypeStringIdItem对应DexHeader中的typeIdsSize与typeIdsOff字段,指向的结构体为DexTypeId,声明如下:
c
struct DexTypeId{
u4 descriptorIdx; //指向DexStringId列表的索引
};
descriptorIdx为指向DexStringId列表的索引,它对应的字符串代表了具体类的类型。从0xb0开始有7个DexTypeId结构,也就是有7个字符串的索引,整理后:


kDexTypeProtoIdItem
kDexTypeProtoIdItem对应DexHeader中的protoIdsSize与protoIdsOff字段,指向的结构体为DexProtoId,声明如下:
c
struct DexProtoId{
u4 shortyIdx; //指向DexStringId列表的索引
u4 returnTypeIdx; //指向DexTypeId列表的索引
u4 parametersOff; //指向DexTypeList的偏移
};
DexProtoId是一个方法声明结构体:
- shortyIdx为方法声明字符串
- returnTypeIdx为方法返回类型字符串
parametersOff指向一个DexTypeList结构体,存放了方法的参数列表,DexTypeList声明如下:
struct DexTypeList{ u4 size; //接下来DexTypeItem的个数 DexTypeItem list[1]; //DexTypeItem结构 }; //DexTypeItem声明如下: struct DexTypeItem{ u2 typeIdx; //指向DexTypeId列表的索引 };DexTypeItem中的typeIdx最终也是指向一个字符串.
从0xcc开始有4个DexProtoId结构,整理后如表


通过上表可以发现,方法声明由返回类型与参数列表组成,并且返回类型位于参数列表的前面。
kDexTypeFieldIdItem
kDexTypeFieldIdItem对应DexHeader中的fieldIdsSize与fieldIdsOff字段,指向的结构体为DexFieldId,声明如下:
c
struct DexFieldId{
u2 classIdx; //类的类型,指向DexTypeId列表的索引
u2 typeIdx; //字段的类型,指向DexTypeId列表的索引
u4 nameIdx; //字段名,指向DexStringId列表的索引
};
DexFieldId结构中的数据全部是索引值,指明了字段所在的类、字段的类型以及字段名。
从0xfc开始共有1个DexFieldId结构,整理后如:


kDexTypeMethodIdItem
kDexTypeMethodIdItem对应DexHeader中的methodIdsSize与methodIdsOff字段,指向的结构体为DexFieldId,声明如下:
c
struct DexMethodId{
u2 classIdx; //类的类型,指向DexTypeId列表的索引
u2 protoIdx; //声明类型,指向DexprotoId列表的索引
u4 nameIdx; //方法名,指向DexStringId列表的索引
};
DexMethodId结构的数据也都是索引值,指明了方法所在的类、方法的声明以及方法名。
从0x104开始共有5个DexMethodId结构,整理后的结果


kDexTypeClassDefItem
kDexTypeClassDefItem对应DexHeader中的classDefsSize与classDefsOff字段,指向的结构体为DexClassDef,声明如下:
c
struct DexClassDef{
u4 classIdx; //类的类型,指向DexTypeId列表的索引
u4 accessFlags; //访问标志
u4 superclassIdx; //父类类型,指向DexTypeId列表的索引
u4 interfacesOff; //接口,指向DexTypeList的偏移
u4 sourceFileIdx; //源文件名,指向DexStringId列表的索引
u4 annotationsOff; //注解,指向DexAnnotationsDirectoryItem结构
u4 classDataOff; //指向DexClassData结构的偏移
u4 staticValuesOff;//指向DexEncodeArray结构的偏移
};
- classIdx字段是一个索引值,表明类的类型
- accessFlags字段是类的访问标志,它是以ACC_开头的一个枚举值
- superclassIdx字段是父类类型索引值
- 如果类中含有接口声明或实现,interfacesOff字段会指向1个DexTypeList结构,否则这里的值为0
- sourceFileIdx字段是字符串索引值,表示类所在的源文件名称
- annotationsOff字段指向注解目录结构,根据类型不同会有注解类、注解方法、注解字段与注解参数,如果类中没有注解,这里的值则为0
- classDataOff字段指向DexClassData结构,它是类的数据部分
- staticValuesOff字段指向DexEncodedArray结构,记录了类中的静态数据

DexClassData结构的声明在DexClass.h文件中,它的声明如下:
c
struct DexClassData{
DexClassDataHeader header; //指定字段与方法的个数
DexField* staticFields; //静态字段,DexField结构
DexField* instanceFiels; //实例字段,DexField结构
DexMethod* directMethods; //直接方法,DexMethod结构
DexMethod* virtualMethods; //虚方法,DexMethod结构
};
//DexClassDataHeader结构记录了当前类中字段与方法的数目
struct DexClassDataHeader{
u4 staticFieldsSize; //静态字段个数
u4 instanceFieldsSize; //实例字段个数
u4 directMethodsSize; //直接方法个数
u4 virtualMethodsSize; //虚方法个数
};
DexClassDataHeader的结构与DexClassData一样,都是在DexClass.h文件中声明的。
(为什么不是在DexFile.h中声明呢?它们都是DexFile文件结构的一部分!可能的原因是DexClass.h文件中所有结构的u4类型的字段其实都是uleb128类型,u1eb128使用1~5个字节来表示一个32位的值,大多数情况下,字段中这些数据可以用小于2个字节的空间来表示,因此,采用uleb128会节省更多的存储空间。
c
struct DexField{
u4 fieldIdx; //指向DexFieldId的索引
u4 accessFlags; //访问标志
};
- fieldIdx字段为指向DexFieldId的索引
accessFlags字段与DexClassDef中的相应字段的类型相同。
DexMethod结构描述方法的原型、名称、访问标志以及代码数据块,它的结构声明如下:
struct DexMethod{ u4 methodIdx; //指向DexMethodId的索引 u4 accessFlags; //访问标志 u4 codeOff; //指向DexCode结构的偏移 }; struct DexCode{ u2 registersSize; //使用的寄存器个数 u2 insSize; //参数个数 u2 outsSize; //调用其他方法时使用的寄存器个数 u2 triesSize; //Try/Catch个数 u4 debugInfoOff; //指向调试信息的偏移 u4 insnsSize; //指令集个数,以2字节为单位 u2 insns[1]; //指令集 //2字节空间用于结构对齐 //try_item[triesSize] DexTry结构 //Try/Catch中handler的个数 //catch_handler_item[handlersSize],DexCatchHandler结构 };通过上面层层的分析,到这里终于看到存放指令集的结构。
registersSize字段指定了方法中使用的寄存器个数,即Smali语法时的“.register”指令的值。
- insSize字段指定了方法的参数个数,即Smali语法中的“.paramter”指令。
- outsSize指定方法调用外部方法时使用的寄存器个数
- triesSize字段指定方法中Try/Catch的个数
- 如果dex文件保留了调试信息,debugInfoOff字段会指向它,调试信息的解码函数为dexDecodeDebugInfo()。可在DexDebugInfo.cpp文件中查看其实现
- insnsSize字段指定了接下来的指令个数
- insns字段即为真正的代码部分
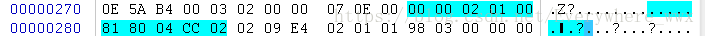
- 0x27b开始先读取DexClassDataHeader结构,为4个uleb128值,结果分别为0、0、2、1,表示该类不含字段,有2个直接方法与1个虚方法。- 由于类中不含字段,因此DexClassData结构中的两个DexField结构也就没戏了,从0x27f开始直接解析DexMethod - 第1个字段为0,指向的DexMethodId为第1条,也就是"``"方法 - 第2个字段“81 80 04”为10001,访问标志为`ACC_PUBLIC | ACC_CONSTRUCTOR` - 第3个字段“cc 02”为14c,指向DexCode结构 **(uleb如何计算:`[cc&7f+(02&7f)<<7]=14c`)** 
- 从0x14c开始解析DexCode,得出结果为:寄存器个数、参数、内部函数使用寄存器都为1个
- 方法中有4条指令,指令为“7010 0400 0000 0e00”
- dalvik-bytecode.html:[密码: cewq]中查找到70的Opcode为invoke-direct,格式为35c
- instruction-formats.html:[密码: k6n6],查找到35c的指令格式为A|G|op BBBB F|E|D|C,有7中表达方式。```asm [A=5] op {vC, vD, vE, vF, vG}, meth@BBBB [A=5] op {vC, vD, vE, vF, vG}, type@BBBB [A=4] op {vC, vD, vE, vF}, kind@BBBB [A=3] op {vC, vD, vE}, kind@BBBB [A=2] op {vC, vD}, kind@BBBB [A=1] op {vC}, kind@BBBB [A=0] op {}, kind@BBBB ``` ```c /*指令7010中A为1,G为0,表示采用代码为“[A=1] op {vC}, kind@BBBB”方式,且其中的vC为v0寄存器; 指令后面的BBBB与“F|E|D|C”都是16位,7010后面的两个16位都为0,因此BBBB=4且F=E=D=C=0; BBBB为kind@类型,它是指向DexMethodId列表的索引值,通过查找得到方法名为“”; 指令0e00直接查表得到return-void;*/ 7010 0400 0000 invoke-direct{v0},Ljava/lang/Object;. :()V 0e00 return-void ``` 观察DexMapItem结构:
- 分析整体结构:
- kDexTypeCodeItem与上面分析的DexCode结构相对应
- kDexTypeTypeList与上面分析的DexTypeList结构相对应
- kDexTypeStringDataItem则指向了DexStringId字符串列表的首地址
- kDexTypeDebugInfoItem指向了调试信息偏移,与DexCode的debugInfoOff字段指向的内容相同
- kDexTypeClassDataItem指向了DexClassData结构
- kDexTypeMapList指向了DexMapItem结构自身
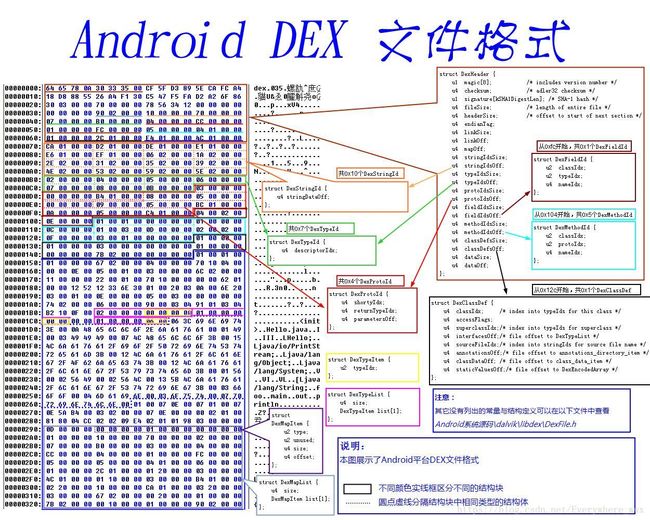
自此:DEX文件格式分析完了,仔细让我琢磨了好多天。。
新博客:showmeshell.top