数据库系统丨数据库常用恢复技术
文章目录
- 0. 概述
- 1. 数据转储
- [1] 数据转储的概念
- [2] 静态转储和动态转储。
- [3]海量转储和增量转储
- [4] 数据转储方法
- 2. 登记日志文件
- [1] 以记录为单位的日志文件
- [2] 以数据块为单位的日志文件
- [3] 日志文件的作用
- [4] 利用日志文件恢复示例图
- [5] ”日志先写“原则
- 3. 检查点恢复技术
- [1] 两个问题
- [2] 检查点
- [3] 示意图
- 4. 数据库镜像
- [1] 介质故障
- [2] 数据库镜像
- [3] 双磁盘镜像技术
- 5. 远程备份系统
- [1] 必要性
- [2] 远程备份系统
- [3] 同步方法
- [4] 示意图
- [5] 分布式数据库
0. 概述
数据库的恢复是指DBMS必须具有把数据库从错误状态恢复到某一已知的正确状态(亦称为一致状态或完整状态)的功能。尽管数据库系统中采取了各种保护措施来防止数据库的安全性和完整性被破坏,保证并发事务的正确执行,但是计算机系统中硬件故障、软件错误、操作员失误及恶意破坏仍是不可避免的,这些故障轻则造成运行事务非正常中断,影响数据库中数据的正确性,重则破坏数据库,使数据库中全部或部分数据丢失,因此DBMS必须具有数据库的恢复功能。
数据库恢复的基本单位是事务。数据库恢复机制包括一个数据库恢复子系统和一套特定的数据结构。
实现可恢复性的基本原理是重复存储数据,即数据冗余。
恢复机制涉及的两个关键问题是:
- 如何建立冗余数据
- 如何利用这些冗余数据实施数据库恢复。
建立冗余数据最常用的技术是数据转储和登录日志文件。它们是数据库恢复的基本技术,通常在一个数据库系统中,这两种方法是一起使用的。
1. 数据转储
[1] 数据转储的概念
数据转储就是DBA定期地将整个数据库复制到磁带或另一个磁盘上保存起来的过程。
这些备用的数据文本称为后备副本或后援副本。当数据库遭到破坏后可以将后备副本重新装人。
但重装后备副本只能将数据库恢复到转储时的状态,要想恢复到故障发生时的状态,必须重新运行自转储以后的所有更新事务。
转储是十分耗费时间和资源的,不能频繁进行。DBA应该根据数据库使用情况确定一个适当的转储周期。转储周期可以是几小时、几天,也可以是几周、几个月。
[2] 静态转储和动态转储。
转储按转储时的状态分为静态转储和动态转储。
- 静态转储
静态转储是在系统中无运行事务时进行的转储操作。即转储操作开始的时刻,数据库处于一致性状态,而转储期间不允许对数据库的任何存取、修改活动。显然,静态转储得到的一定是一个数据一致性的副本。
静态转储简单,但转储必须等待正在运行的用户事务结束才能进行,同样,新的事务必须等待转储结束才能执行。显然,这会降低数据库的可用性。
- 动态转储
动态转储是指转储期间允许对数据库进行存取或修改。即转储和用户事务可以并发执行。
它不用等待正在运行的用户事务结束,必须把转储期间各事务对数据库的修改记下来,建立日志文件(Log File)。这样,后援副本加上日志文件就能把数据库恢复到某一时刻的正确状态。
[3]海量转储和增量转储
转储按方式不同分为海量转储和增量转储。
- 海量转储
海量转储是指每次转储全部数据库。
- 增量转储
增量转储则指每次只转储上一次转储后更新过的数据。
从恢复角度看,一般说来,用海量转储得到的后备副本进行恢复会更方便些。但如果数据库很大,事务处理又十分频繁,则增量转储方式更实用、有效。
[4] 数据转储方法
数据转储有两种方式,分别可以在两种状态下进行,因此数据转储方法可以分为4类,见下表。

2. 登记日志文件
日志文件是用来记录事务对数据库的更新操作的文件。概括起来,日志文件主要有两种格式:
-
以记录为单位的日志文件
-
以数据块为单位的日志文件。
[1] 以记录为单位的日志文件
一个日志记录(LogRecord)包括每个事务开始的标记、结束标记和每个更新操作。
[2] 以数据块为单位的日志文件
包括事务标识和被更新的数据块。
由于将更新前的整个块和更新后的整个块都放人日志文件中,操作的类型和操作对象等信息就不必放人日
志记录中。
[3] 日志文件的作用
日志文件在数据库恢复中起着非常重要的作用。可以用来进行事务故障恢复和系统故障恢复,并协助后备副本进行介质故障恢复。具体的作用如下:
①事务故障恢复和系统故障必须用日志文件。
②在动态转储方式中必须建立日志文件,后备副本和日志文件综合起来才能有效地恢复数据库。
③在静态转储方式中,也可以建立日志文件。
④当数据库毁坏后可重新装人后备副本把数据库恢复到转储结束时刻的正确状态,然后利用日志文件,把已完成的事务进行重做处理,对故障发生时尚未完成的事务进行撤销处理。这样不必重新运行那些已完成的事务程序就可把数据库恢复到故障前某一时刻的正确状态。
[4] 利用日志文件恢复示例图
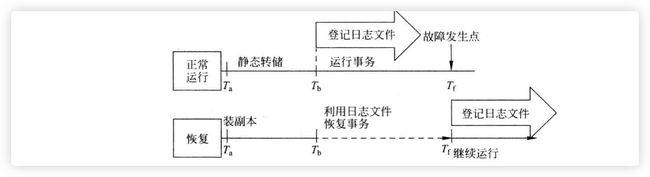
[5] ”日志先写“原则
把对数据的修改写到数据库中与把表示这个修改的日志记录写到日志文件中是两个不同的操作。有可能在这两个操作之间发生故障,即这两个写操作只完成了一个。如果先写了数据库修改,而在运行记录中没有登记下这个修改,则以后就无法恢复这个修改了。如果先写日志,但没有修改数据库,按日志文件恢复时只不过是多执行一次不必要的撤销(UNDO)操作,并不会影响数据库的正确性。
3. 检查点恢复技术
[1] 两个问题
利用日志技术进行数据库恢复时,恢复子系统必须搜索日志,确定哪些事务需要REDO(重做),哪些事务需要UNDO。
一般需要检查所有日志记录。这样做有两个问题:
- 一是搜索整个日志将耗费大量的时间;
- 二是很多需要REDO处理的事务实际上已经将它们的更新操作结果写到数据库中了,然而恢复子系统又重新执行了这些操作,浪费了大量时间。
为了解决这些问题,人们研究发展了具有检查点的恢复技术。
[2] 检查点
检查点(Check Point)也称安全点、恢复点。当事务正常运行时,数据库系统按一定的时间间隔设检查点。一旦系统需要恢复数据库状态,就可以根据最新的检查点的信息,从检查点开始执行,而不必从头开始执行那些被中断的事务。
具有检查点的恢复技术在日志文件中增加一类新的记录——检查点记录(检查点建立时所有正在执行的事务清单),增加一个重新开始文件(存储各检查点记录的地址),并让恢复子系统在登录日志文件期间动态地维护日志。
系统在检查点做的动作主要如下:
①暂时中止现有事务的执行。
②在日志中写人检查点记录,并把日志强制写人磁盘。
③把主存中被修改的数据缓冲区强制写人磁盘。
④重新开始执行事务。
[3] 示意图
系统出现故障时恢复子系统将根据事务的不同状态采取不同的恢复策略,如图所示。

4. 数据库镜像
[1] 介质故障
介质故障是对系统影响最为严重的一种故障。
系统出现介质故障后,用户应用全部中断,恢复起来也比较费时。故DBA必须周期性地转储数据库,如果不及时而正确地转储数据库,一旦发生介质故障,会造成较大的损失。
[2] 数据库镜像
为避免磁盘介质出现故障影响数据库的可用性,许多DBMS提供了数据库镜像(Mirror)功能用于数据库恢复。其方法是DBMS根据DBA的要求,自动把整个数据库或其中的关键数据复制到另一个磁盘上,并自动保证镜像数据与主数据的一致性,即每当主数据库更新时,DBMS自动把更新后的数据复制过去,如图6-7(a)所示。
一旦出现介质故障,可由镜像磁盘继续提供使用,同时DBMS自动利用镜像磁盘数据进行数据库的恢复,不需要关闭系统和重装数据库副本,如图6-7(b)所示。
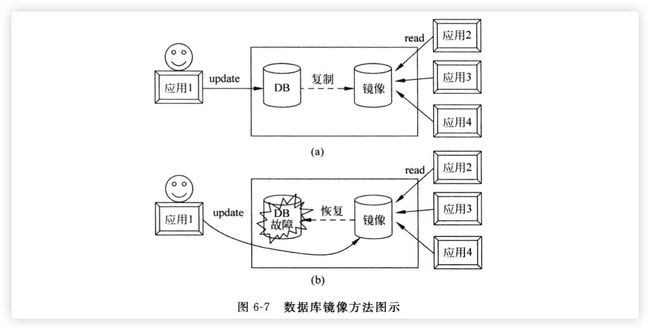
[3] 双磁盘镜像技术
在没有出现故障时,数据库镜像还可以用于并发操作,即当一个用户对数据加排他锁修改数据时,其他用户可以读镜像数据库上的数据,而不必等待该用户释放锁。
双磁盘镜像技术(MirroredDisk)常用于可靠性要求高的数据库系统。数据库以双副本的形式存放在2个独立的磁盘系统中,每个磁盘系统有各自的控制器和CPU,且可以互相自动切换。
5. 远程备份系统
[1] 必要性
现代数据库应用要求事务处理系统提供高可用性,即系统不能使用和等待的时间必须少之又少。传统的事务处理系统是集中式或局域客户/服务器模式。这样的系统易遭受火灾、洪水和地震等自然灾害的毁坏。故要求数据库系统有抗破坏力,使之无论在系统故障还是自然灾害下都能快速恢复运行。
[2] 远程备份系统
获得高可用性的方式之一是远程备份系统,即在一个主站点(Primary Site)执行事务处理,使用一个远程备份(RemoteBackup)站点以应付突发事件。一开始所有主站点的数据都被复制到远程备份站点。随着更新在主站点上执行,远程站点必须保持与主站点同步。
[3] 同步方法
通过发送所有主站点的日志记录到远程备份站点,远程备份站点根据日志记录执行同样的操作来达到同步。
注意不是传送更新的数据本身,而是传送更新数据的操作命令,这样可大大减少数据的传送量。
远程备份站点必须物理地与主站点分开放在不同的地区,这样发生在主站点的灾害就不会殃及远程备份站点。
[4] 示意图

当主站点发生故障时,远程备份站点就立即接管处理。但它首先使用源于主站点的数据副本(也许已过时)以及收到的来自主站点的日志记录执行恢复。事实上,远程备份站点执行的恢复动作就是主站点要恢复时需要执行的恢复动作。对于单站点的恢复算法稍加修改,就可用于远程备份站点的恢复。一旦恢复执行完成,远程备份站点就开始处理事务。即使主站点的数据全部丢失,系统也能恢复,相对单站点系统而言,这大大地提高了系统的可用性。
[5] 分布式数据库
另一种实现高可用性的方法是使用分布式数据库,将数据复制到不止一个站点。此时事务更新任何一个数据项,都被要求去更新其所有复制品。