Pycharm环境python爬虫初试笔记
使用Pycharm进行爬虫,根据https://python.gotrained.com/scrapy-tutorial-web-scraping-craigslist/ 提供的教程进行尝试。
爬虫项目的建立需要一系列相关文件,上网查其它资料以及上述教程都是使用了命令提示符进行项目创建,也是比较方便的。安装好scrapy相关环境后,将目录设为需要建立项目的目录,在命令提示符中键入
scrapy startproject scr # scr为爬虫项目的名称随后进入项目目录,即键入
cd scr然后使用scrapy的genspider指令创建爬虫,并指定将要进行爬虫的网站的URL
scrapy genspider jobs newyork.craigslist.org/search/egr
# jobs为自己指定的爬虫的名称,后边的URL注意不需要添加https://,因为scrapy会自己添加这时scrapy会自动在当前目录建立一个python项目,基本框架已经搭好,使用pycharm打开项目,树状图如下图所示

jobs.py文件此时内容如下
# -*- coding: utf-8 -*-
import scrapy
class JobsSpider(scrapy.Spider):
name = 'jobs' # 爬虫名称
allowed_domains = ['craigslist.org'] # 此处为修改后扩大范围的URL,为了便于后边的多页抓取操作
start_urls = ['http://newyork.craigslist.org/search/egr/'] # 开始抓取的起点
def parse(self, response): # 爬虫主函数,不能更名,但可以额外添加函数
pass我们要抓取该网页的所有职位头衔(即名称),该网页如下图所示
在我们要抓取的部分右键,检查元素(这里是Edge浏览器),可以得到该部分对应的脚本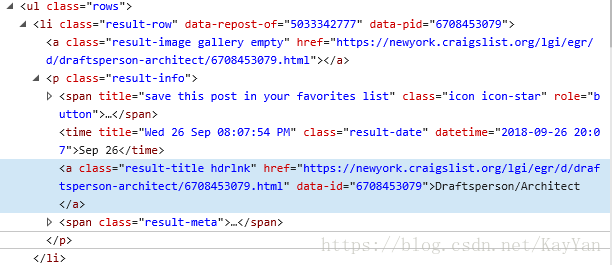
可以发现我们第一步要抓取的部分为标签中的文本,此标签的标志特征为它的类,即
class="result-title hdrlnk"据此,使用如下代码替换pass语句
titles = response.xpath('//a[@class="result-title hdrlnk"]/text()').extract()response为downloader返回的对象,代表该网页的全部源代码,可以通过print(response.body)检视。xpath语句用于提取HTML的特定部分,这里暂不深入考虑。该语句中:
// 表示从我指定的标签开始而非,这里为a,即。
[@class="result-title hdrlnk"] 表示提取的标签必须为有该指定的类的标签,类都需要写在@后边。
/ 后边表示要提取的内容,text()即表示提取标签的文本。
extract() 表示将源代码中所有满足前两步约束的标签的内容全部提取,如果使用extract_first(),则只提取第一个。
这时运行爬虫,返回的titles为一个列表,因此可以对其循环,将其存储于一个字典中,代码如下
for title in titles:
yield {'Title': title}比较实用的方式是将爬到的数据存储在CSV文件中,scrapy支持csv,json或XML输出。在命令提示行中输入
scrapy crawl jobs -o result.csv # o代表输出,后边为文件名即可得到该页的全部职位信息,如下图
上述选取标签特征的方式仅能获取某职位的名称,如果想得到更多信息,比如工作地点(括号内容)
![]()
上述方法便行不通了,观察脚本,可以发现每一个职位都有一个
标签语句,其类为“result-info”
如果抓取每一个职位对应的p标签,那么该标签的内容就相当于一个”容器“,其中存储了该职位的名称、地点、URL等信息
首先抓取该”容器“
jobs = response.xpath('//p[@class="result-info"]')语法规则与前文大同小异,此时的jobs为存储所有容器的一个”列表“(也许是),可以进行遍历操作,观察上图脚本,职位名称存储于标签中,工作地址位于标签中,URL信息同样位于标签中,对应的提取代码为
for job in jobs:
title = job.xpath('a/text()').extract_first()
address = job.xpath('span[@class="result-meta"]/span[@class='
'"result-hood"]/text()').extract_first('')[2:-1]
rel_url = job.xpath('a/@href').extract_first() # 相对URL
abs_url = response.urljoin(rel_url)
# 绝对URL,也可用字符串相加,不过就需要在extract_first()中设置函数参数为‘’
# extract_first()中‘’的意义为当符合向不存在时使输出为空字符串,而非none
# [2:-1]的为了去掉工作地址文本中的括号
注释:xpath语句中的‘/’表示下一子级,‘[ ]’表示特征属性,需要用‘@’作前缀。
这样,再次运行爬虫,在命令提示符中输入
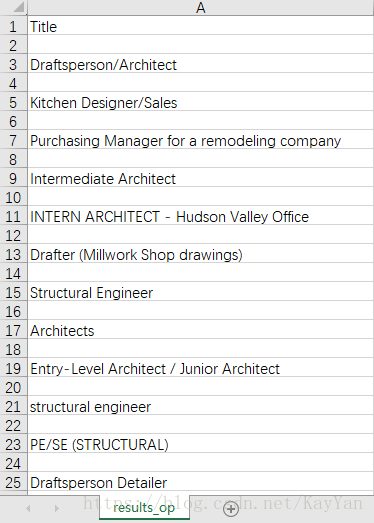
scrapy crawl -o result_op.csv得到的输出表格如下图所示

下面进一步考虑多页码的情况,网页本身往往不只有一页,为了自动爬遍所有存在信息的网页,可以对该网页的翻页按钮‘next’进行检视
![]()
利用其class属性,获取其对应的URL,代码为
rel_next_url = response.xpath('//a[@class="button next"]/@href').extract_first()
abs_next_url = response.urljoin(rel_next_url)随后利用scrapy的Request对象(注:目前暂时不明白Request的机理....)进行每页的循环调用(?),使用前需要先import一下
from scrapy import Request生成Request对象
yield Request(abs_next_url, callback=self.parse)这里callback可以不写,默认也是parse函数。此时全部的代码为
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
class JobsSpider(scrapy.Spider):
name = 'jobs'
allowed_domains = ['craigslist.org']
start_urls = ['http://newyork.craigslist.org/search/egr/']
def parse(self, response):
jobs = response.xpath('//p[@class="result-info"]')
for job in jobs:
title = job.xpath('a/text()').extract_first()
address = job.xpath('span[@class="result-meta"]/span[@class='
'"result-hood"]/text()').extract_first('')[2:-1]
# extract_first()中‘’的意义为当符合向不存在时使输出为空字符串,而非none
rel_url = job.xpath('a/@href').extract_first()
abs_url = response.urljoin(rel_url)
yield {'Title': title, 'Address': address, 'URL': abs_url}
rel_next_url = response.xpath('//a[@class="button next"]/@href').extract_first()
abs_next_url = response.urljoin(rel_next_url)
yield Request(abs_next_url, callback=self.parse)
再爬一下,可以发现能爬到的信息涵盖了所有页码的内容。
注:多页码时allowed_domains不能使用默认的URL(默认生成的与start_urls一样),否则仍然只爬当前页的内容。大概意思就是扩大URL的范围。
(待续)