分享Spark MLlib训练的广告点击率预测模型
2015年,全球互联网广告营收接近600亿美元,比2014年增长了近20%。多家互联网巨头都依赖于广告营收,如谷歌,百度,Facebook,互联网新贵们也都开始试水广告业,如Snapchat, Pinterest, Spotify.

作为互联网广告的老大哥,谷歌花了很大的力气研发自己的社交网络,Google+,并期待能与Facebook,Twitter抗衡。然后事与愿违,Google+的份额依然低于1% 。
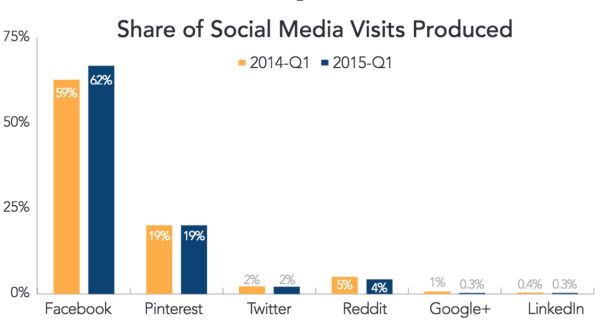
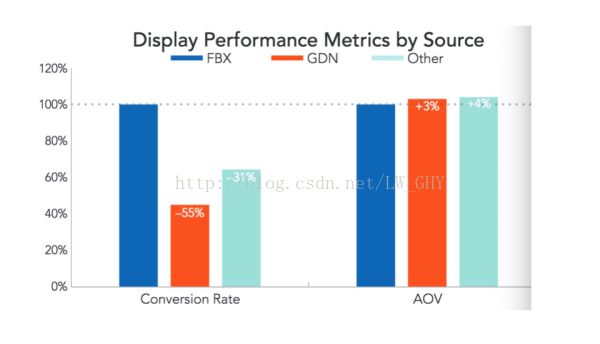
2015年,谷歌终于不再强迫用户把Google+和谷歌家的其他服务绑定,如Youtube。笔者认为谷歌花大量人力财力研发Google+并将其与其他服务绑定的原因之一是搜集用户的喜好数据来为自家的广告业务服务。更具体的说是为了更好地预测广告的点击率。在这方面,Facebook似乎更胜一筹。2015年第一季度,Facebook广告的转换率比Google Display Ads Network (GDN)高出了55%。笔者并不感到惊讶,Facebook显然比谷歌更了解用户的喜好,笔者猜测用户的行为,包括点赞, 评论,关注等,都为广告算法提供了关于用户的喜好或类别的信息。这些信息会用于广告的点击率预测,而点击率预测又会应用于广告排序算法。
今天我就带大家来用 Spark MLlib训练一个广告点击率预测的模型。
环境配置
Java
Spark 2.0.0
安装很简单,pre-built版本的spark下载下来即可
Downloads | Apache Spark
Python
数据
Kaggle Avazu挑战赛中的广告数据
Click-Through Rate Prediction
元数据
id: ad identifier
click: 0/1 for non-click/click
hour: format is YYMMDDHH, so 14091123 means 23:00 on Sept. 11, 2014 UTC.
C1 -- anonymized categorical variable
banner_pos
site_id
site_domain
site_category
app_id
app_domain
app_category
device_id
device_ip
device_model
device_type
device_conn_type
C14-C21 -- anonymized categorical variables
数据预处理
我们注意到数据中有字符串类型的值,如site_id,site_domain,site_category,app_id,app_domain,app_category等。我们需要将他们转换成数值型,公式如下:

代码:
import os
import sys
if __name__ == "__main__":
input_file = sys.argv[1]
preprocess_file = sys.argv[2]
test_flag = sys.argv[3]
print "input=" + input_file
print "preprocess_file=" + preprocess_file
output = open(preprocess_file, "w")
with open(input_file, "r") as lines:
next(lines)
for line in lines:
fields = line.split(",")
index = 5
end = 14
if test_flag == "1":
index = 4
end = 13
while index < end:
fields[index] = str(hash(fields[index]) % 1000000)
index += 1
newline = ",".join(fields)
output.write(newline)
output.close()代码:
import os
import sys
if __name__ == "__main__":
input_file = sys.argv[1]
train_file = sys.argv[2]
test_file = sys.argv[3]
test_start_date = sys.argv[4]
test_data_ouput = open(test_file, "w")
train_data_output = open(train_file, "w")
with open(input_file, "r") as lines:
next(lines)
for line in lines:
fields = line.split(",")
if fields[2].startswith(test_start_date):
test_data_ouput.write(line)
else:
train_data_output.write(line)
train_data_output.close()
test_data_ouput.close()Apache Spark是一个分布式计算框架,旨在简化运行于计算机集群上的并行程序的编写。该框架对资源调度,任务的提交、执行和跟踪,节点间的通信以及数据并行处理的内在底层操作都进行了抽象。它提供了一个更高级别的API用于处理分布式数据。从这方面说,它与Apache Hadoop等分布式处理框架类似。但在底层架构上,Spark与它们有所不同。
我们先介绍SparkContext对象。任何Spark程序的编写都是从SparkContext(或用Java编写时的JavaSparkContext)开始的。SparkContext的初始化需要一个SparkConf对象,后者包含了Spark集群配置的各种参数(比如主节点的URL)。初始化后,我们便可用SparkContext对象所包含的各种方法来创建和操作分布式数据集和共享变量。若要用Python代码来实现的话,可参照下面的代码:
sconf = SparkConf().setAppName(“WordCount") .setMaster(“local[4]")
sc = SparkContext(conf=sconf)RDD(Resilient Distributed Dataset,弹性分布式数据集)是Spark的核心概念之一。一个RDD代表一系列的“记录”(严格来说,某种类型的对象)。这些记录被分配或分区到一个集群的多个节点上(在本地模式下,可以类似地理解为单个进程里的多个线程上)。Spark中的RDD具备容错性,即当某个节点或任务失败时(因非用户代码错误的原因而引起,如硬件故障、网络不通等),RDD会在余下的节点上自动重建,以便任务能最终完成。我们可以把RDD看成数据和基于该数据计算的单元。
RDD也可以基于Hadoop的输入源创建,比如本地文件系统、HDFS和Amazon S3。基于Hadoop的RDD可以使用任何实现了Hadoop InputFormat接口的输入格式,包括文本文件、其他Hadoop标准格式、HBase、Cassandra等。以下举例说明如何用一个本地文件系统里的文件创建RDD:
rddFromTextFile = sc.textFile(“sample.txt")基于RDD的操作被分为转换(transformation)和执行(action)两种。一般来说,转换操作是对一个数据集里的所有记录执行某种函数,从而使记录发生改变;而执行通常是运行某些计算或聚合操作,并将结果返回运行SparkContext的那个驱动程序(driver)。
常见的转换操作: map, filer
常见的执行操作: count, take, collect, saveAsTextFile
基于SparkMLliB的模型训练
Spark提供丰富的机器学习库,包括:分类,回归,聚类等。此外还提供特征提取算法库。详见:
MLlib: Main Guide
本文将logistic regression 应用于处理过的数据,把 loss 收敛在 21.7左右
代码:
from __future__ import print_function
from pyspark import SparkContext
from pyspark.mllib.classification import LogisticRegressionWithLBFGS,
LogisticRegressionModel
from pyspark.mllib.regression import LabeledPoint
from pyspark.mllib.util import MLUtils
if __name__ == "__main__":
sc = SparkContext(appName="CTRLogisticRegression")
# $example on$
# Load and parse the data
def parsePoint(line):
values = [float(x) for x in line.split(',')]
features = values[0:1]
features.extend(values[2:])
return LabeledPoint(values[1],features)
data = sc.textFile("train_data")
testData = sc.textFile("test_data")
parsedTrainData = data.map(parsePoint)
parsedTestData = testData.map(parsePoint)
# Build the model
model = LogisticRegressionWithLBFGS.train(parsedTrainData)
# Evaluating the model on training data
labelsAndPreds = parsedTestData.map(lambda p: (p.label,
model.predict(p.features)))
trainErr = labelsAndPreds.filter(lambda (v, p): v != p).count() /
float(parsedTestData.count())
print("Training Error = " + str(trainErr))
# Save and load model
model.save(sc, "target/tmp/CTR")$SPARKPATH/bin/spark-submit kagggleLogisstic.py
$SPARKPATH 为spark安装目录
延伸
由于精度太低,上述例子训练处的模型显然是无法用于工业界的。特征工程(Feature engineering) 可以帮助我们提高模型的可靠性和准确性,那么如何进行特征工程来提高广告点击率预测的精度呢?有哪些额外的特征可以生成?为何Facebook的广告转换率比谷歌的高?这两者间有何联系?