达梦数据库表简单测试
DM数据库表简单测试
本篇内容仅为在学习过程中,做的简单测试的相关记录。
非完全的功能性测试。
1、普通表简单测试
功能上和其他关系型数据库表功能一样。
----创建测试表包含常用数据类型、自增列、检查约束、非空约束、缺省值列
create table "TEST"."TAB2"
(
"ID" INT not null ,
"NAME" VARCHAR2(50) not null ,
"AGE" NUMBER(22, 6) check(age>=18) not null ,
"JOB" VARCHAR(50),
"BIRTHDAY" DATE not null ,
"WORKTIME" DATETIME(6),
"LOCATION" CHAR(10) default ('CHINA') not null,
"COUNT" INT IDENTITY(1,1), ---自增列种子为1,增量为1,自增列中增量不能为0,可以为负值
primary key("ID")
)
storage(initial 1, next 1, minextents 1, fillfactor 0, on TEST)
;
1.1 自增列简单测试
DM自增列使用说明:
1. IDENTITY 适用于 INT(-2147483648~ +2147483647)、 BIGINT(-263~
+263-2)类型的列。 每个表只能创建一个自增列;
2.不能对自增列使用 DEFAULT 约束;
3.必须同时指定种子和增量值,或者二者都不指定。如果二者都未指定,则取默认值(1,1)。 若种子或增量为小数类型,报错;
4.最大值和最小值为该列的数据类型的边界;
5.建表种子和增量大于最大值或者种子和增量小于最小值时报错;
6.自增列一旦生成,无法更新,不允许用 UPDATE 语句进行修改;
7. 临时表、列存储表、水平分区表不支持使用自增列
-----插入数据,并查询
insert into test.TAB2(id,name,age,job,BIRTHDAY)
VALUES(10,'A',26,'SALES',to_date('1994-01-01','yyyy-mm-dd'));
insert into test.TAB2(id,name,age,job,BIRTHDAY)
VALUES(11,'B',22,'SALES',to_date('1998-01-01','yyyy-mm-dd'));
insert into test.TAB2(id,name,age,job,BIRTHDAY)
VALUES(12,'C',20,'SALES',to_date('1999-01-01','yyyy-mm-dd'));
commit;

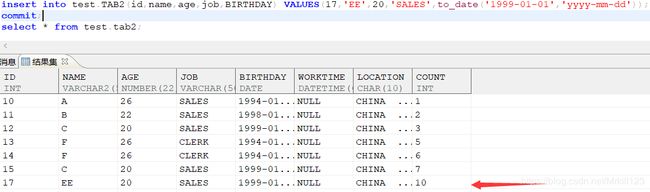
手动对自增列插入指定的值:
设置SET IDENTITY_INSERT TABLE_NAME ON; 属性可以手动指定插入自增列的值,并且在插入数据是需要显示指定自增列列名。如果插入时,既不指定自增列名也不给自增列赋值,则新插入行中自增列的当前值由系统自动生成。
SET IDENTITY_INSERT TEST.TAB2 ON;
insert into test.TAB2(id,name,age,job,BIRTHDAY,COUNT)
VALUES(13,'F',26,'CLERK',to_date('1994-01-01','yyyy-mm-dd'),5);
insert into test.TAB2(id,name,age,job,BIRTHDAY,COUNT)
VALUES(14,'F',26,'CLERK',to_date('1994-01-01','yyyy-mm-dd'),6);
--不指定自增列且不给自增列赋值,则新插入行中自增列的当前值由系统自动生成。
insert into test.TAB2(id,name,age,job,BIRTHDAY)
VALUES(15,'C',20,'SALES',to_date('1999-01-01','yyyy-mm-dd'));
Commit;
SET IDENTITY_INSERT TEST.TAB2 OFF; ---此属性恢复默认系统自动插入自增列的值
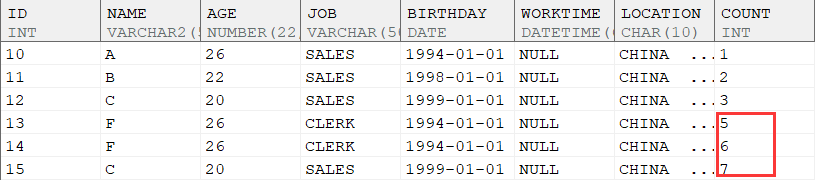 可以看到当设置了identify_insert on属性后,插入时不指定自增列也不给自增列赋值则新插入的自增列的值会由系统生成。
可以看到当设置了identify_insert on属性后,插入时不指定自增列也不给自增列赋值则新插入的自增列的值会由系统生成。
对于自增列的表插入数据时,
如果插入的值违反表字段的约束导致插入失败,每失败一次自增列的最新值都会增加定义的增量值。
验证如下:
模拟两次插入违反约束失败:
上一个成功插入的自增列的值为7


下一次正确插入的自增列的值应该为10
1.2 非空约束
DM默认对表中非空约束字段插入空字符串与NULL得到的结果是不同的,空字符串可以成功,null会违反约束,与SQL Server相同,但是与Oracle中都会违反非空约束。测试如下:
DM中:


Oracle中:

修改兼容模式为Oracle,重启服务后插入与Oracle中一样:
sp_set_para_value(2,'COMPATIBLE_MODE',2);
重启数据库。

与Oracle中效果相同,达梦在与Oracle的兼容性上做的还是挺灵活的。
1.3 数据类型别名
---初始化类型别名运行环境
call sp_init_dtype_sys(1);
---创建VARCHAR2(60)的数据类型别名‘STR’
CALL SP_DTYPE_CREATE('STR','VARCHAR2',60,NULL);
---使用创建的类型别名建表并插入数据;
create table tab1(id INT,NAME "STR");
insert into tab1 values(1,null);
insert into tab1 VALUES(2,'');
insert into tab1 values(3,'A');
commit;
---查询表数据
select * from tab1;
---删除创建的类型别名
CALL SP_DTYPE_DELETE('STR');

注意:
在创建类型别名时,指定别名名称需要避免一些关键字。虽然创建别名时没有提示错误,但是在建表示会出现提示:无效的数据类型。
达梦数据库关键字可以在官方文档《DM8 SQL手册》 "附录1 关键字和保留字" 中查看。
比如下面创建了名为STRING的类型别名:

2、分区表简单测试
达梦数据库和Oracle一样支持多种类型的分区,也兼容Oracle大部分的系统视图,但是达梦数据库无法像Oracle那样在收集表的统计信息后,可以在DBA_TAB_PARTITIONS等分区表相关视图中查看到分区中的数据行数num_rows。
达梦数据库 DM 支持对表进行水平分区。对于水平分区,提供以下分区方式:
范围(range)水平分区:对表中的某些列上值的范围进行分区,根据某个值的范
围,决定将该数据存储在哪个分区上;
哈希(hash) 水平分区:通过指定分区编号来均匀分布数据的一种分区类型,通
过在 I/O 设备上进行散列分区,使得这些分区大小基本一致;
列表(list) 水平分区:通过指定表中的某个列的离散值集,来确定应当存储在
一起的数据。例如,可以对表上的 status 列的值在('A', 'H', 'O')放在一个
分区,值在('B', 'I', 'P')放在另一个分区,以此类推;
多级分区表:按上述三种分区方区进行任意组合,将表进行多次分区,称为多级分
区表。
也支持和Oracle 11g 的interval类型分区,可以根据加载数据,自动创建指定间隔的分区。
例如自动按月分区:
partition by range(ALLOCATION_TIME)
INTERVAL (NUMTOYMINTERVAL(1,'month'))
(
PARTITION p20204 VALUES LESS THAN to_date('2020-04-01','yyyy-mm-dd'),
PARTITION p20205 VALUES LESS THAN to_date('2020-05-01','yyyy-mm-dd')
) STORAGE(ON MAIN);
分区表的执行计划操作符为:PARALLEL
创建分区表
---创建范围分区表:
create table tab_par1
(
id int,
name varchar2(20),
mtime DATEtime
)PARTITION BY RANGE(mtime)
(PARTITION p2017 VALUES LESS THAN ('2018-01-01'),
PARTITION p2018 VALUES LESS THAN ('2019-01-01'),
PARTITION p2019 VALUES LESS THAN ('2020-01-01'),
PARTITION p202001 VALUES LESS THAN ('2020-02-01'),
PARTITION p202002 VALUES LESS THAN ('2020-03-01'),
PARTITION p202003 VALUES LESS THAN ('2020-04-01'),
PARTITION p202004 VALUES LESS THAN ('2020-05-01'),
PARTITION p_other VALUES LESS THAN (MAXVALUE)
);
---创建哈希分区表:
create table TAB_PAR2
(ID INT,
NAME VARCHAR2(20),
CITY CHAR(10)
)
PARTITION BY HASH(CITY)
(PARTITION P1,
PARTITION P2,
PARTITION P3,
PARTITION P4);
---创建列表分区表
create table TAB_PAR3
(ID INT,
NAME VARCHAR2(20),
CITY CHAR(10)
)
PARTITION BY LIST(CITY)
(PARTITION P1 VALUES('长沙','深圳'),
PARTITION P2 VALUES('上海','杭州'),
PARTITION P3 VALUES('北京','安徽'));
---创建组合分区表LIST-RANGE
CREATE TABLE TAB_PAR4(
ID INT,
NAME CHAR(20),
MTIME DATETIME,
CITY CHAR(10)
)
PARTITION BY LIST(CITY)
SUBPARTITION BY RANGE(MTIME) SUBPARTITION TEMPLATE(
SUBPARTITION P11 VALUES LESS THAN ('2019-04-01'),
SUBPARTITION P12 VALUES LESS THAN ('2019-08-01'),
SUBPARTITION P13 VALUES LESS THAN ('2019-12-01'),
SUBPARTITION P14 VALUES EQU OR LESS THAN (MAXVALUE))
(
PARTITION P1 VALUES ('长沙', '武汉')
(
SUBPARTITION P11_1 VALUES LESS THAN ('2019-12-01'),
SUBPARTITION P11_2 VALUES EQU OR LESS THAN (MAXVALUE)
),
PARTITION P2 VALUES ('上海', '北京', '深圳'),
PARTITION P3 VALUES (DEFAULT)
);
创建垂直分区表:
当前版本创建失败

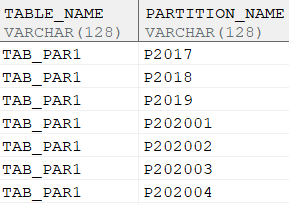
删除分区
---删除分区P_OTHER
ALTER TABLE TAB_PAR1 DROP PARTITION P_OTHER;
select table_name,PARTITION_NAME from DBA_TAB_PARTITIONS order by 2;
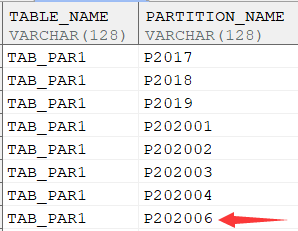
新增分区
---新增分区P_202006
alter table TAB_PAR1 add partition p202005 values LESS THAN ('2020-07-01');
select table_name,PARTITION_NAME from DBA_TAB_PARTITIONS order by 2;
分区拆分
---拆分分区P_202006为P_202005,P_202006_1两个分区
ALTER TABLE TAB_PAR1 SPLIT PARTITION P202006 AT ('2020-05-30') INTO (PARTITION P202005,PARTITION P202006_1);
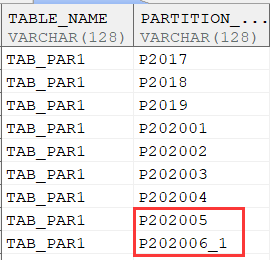
查询拆分后的数据,也已经分布到拆分的两个新分区里面了:


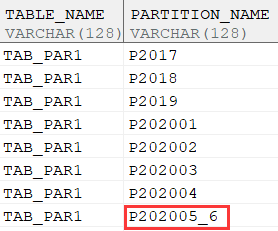
分区合并
---合并分区,将P_202005,P_202006_1两个分区合并为P_202005_6
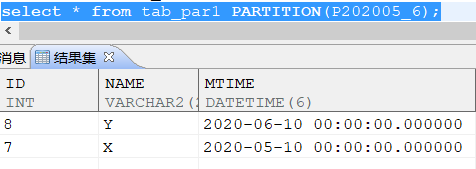
ALTER TABLE TAB_PAR1 MERGE PARTITIONS P202005,P202006_1 INTO PARTITION P202005_6;
交换分区
---交换分区,将P2019分区的数据交换到新建的表中
新建交换表,表结构与分区表字段相同:
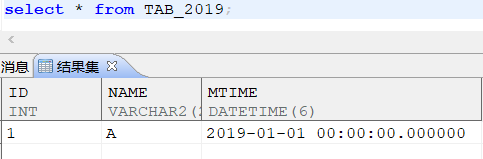
create table tab_2019
(
id int,
name varchar2(20),
mtime DATETIME)
交换分区:
ALTER TABLE TAB_PAR1 EXCHANGE PARTITION P2019 WITH TABLE TAB_2019;
注意:
如果表结构不一样,交换分区时会提示错误“交换对象不匹配”。
查询表数据:
列存表简单使用
---创建huge表空间以及列存表并插入数据
create huge tablespace HTS_TBS path '/data/dmdbms/data/DAMENG/HTS_TBS01.DBF';
--创建事务型HUGE表,b列默认不收集统计信息,指定a列压缩级别为1(最低压缩级别)
create huge table h1 (a int,b int storage(stat none)) storage(with delta,on hts_tbs) compress level 1 (a);
--创建非事务型HUGE表,a列默认不收集统计信息,指定b列压缩级别为9(最高压缩级别)
create huge table h2 (a int storage(stat none),b int) storage(without delta,on hts_tbs) compress level 9 (b);
insert into h1 values(1,2);
insert into h1 values(2,3);
insert into h1 values(3,4);
insert into h2 values(1,2);
insert into h2 values(2,3);
insert into h2 values(3,4);
commit;
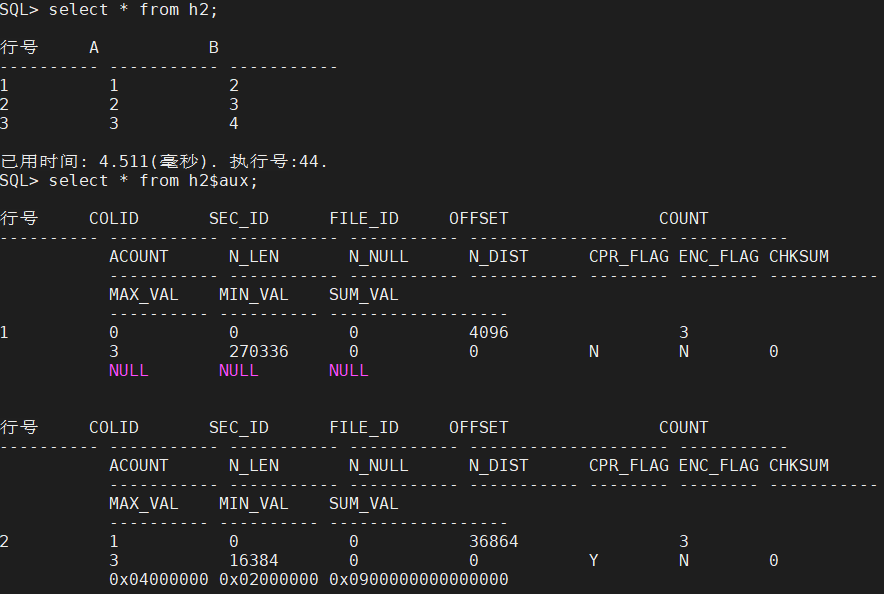
select * from h1;
select * from h1$aux;
select * from h2;
select * from h2$aux;