【交易架构day8】洋码头交易系统的演进之路——先生存后发展
按:我们谈系统演化,本质上是一个动态进化的过程,谁先做、谁后做,第一枪打在哪、这是关键。先保生存、再发展是比较好的策略。本文来自洋码头架构师张志强、涂文杰两位的分享。
1. 交易1.0
和许多业务优先、快速起步的创业型公司一样,洋码头的核心业务最初都在一个主站系统中。该系统很快发展成一个小型巨无霸,服务拆分势在必行。从主站系统剥离出所有订单相关功能,快速封装出一套独立部署的Restful风格的服务就形成了交易系统1.0。
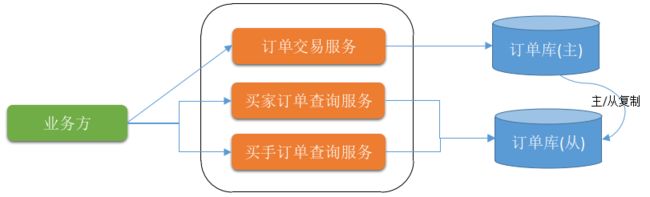 图1 - 1.0架构图
图1 - 1.0架构图
在1.0版本,数据库读/写分离,订单操作服务和订单查询服务分离,买家订单查询服务和买手订单查询服务分离。
2. 交易2.0
随着业务发展,订单在线实时查询/聚合的场景/条件越来越复杂。为保证足够的性能,查询服务引入了越来越多,越来越复杂(譬如大量的SQL Join操作等)的查询存储过程,系统的可读性,可维护性下降;同时,为应对不断增加的查询条件及其组合,在核心的订单表上添加了越来越多的索引,严重影响了系统的下单峰值处理能力。因此,交易2.0的关键目标是:
-
查询服务去存储过程
-
订单表去索引
为此,我们将操作类数据源与查询类数据源彻底分离。操作类数据源为支持事务的SQL数据库,专注在写的高效,不提供查询服务。查询类数据源为文档型(Document)NoSQL数据库(Mongodb/ElasticSearch),专门用于各类订单查询,专注在读的高效与便捷。每完成一次订单操作场景(譬如订单支付成功),SQL数据库中被变更且需要被查询到的数据会被即时同步到Mongodb/ElasticSearch中。一个订单的所有能被查询的信息结构化在一个Document中,拿到订单ID,就能按需从Document中取数据构造查询结果,再无在1.0版本中大量多SQL表复杂JOIN操作的痛苦。同时,因为SQL数据库只负责写,各主要SQL业务表上订单ID之外的索引基本被清除,下单TPS可达原来的2~3倍。以下是版本2.0的总体架构图:
 图2 - 2.0架构图
图2 - 2.0架构图
2.1 订单查询库的设计
l 订单明细Mongodb Collection(order):一个Document对应一个订单的所有可能被查询的结构化数据。数据量最大,更新最频繁,因此该Collection除订单ID主键外,再无其他索引。
l 买家查询索引Mongodb Collection(userOrderIndex):一个Document对应一个订单,只存放可被作为买家查询条件的字段(如用户ID userId,下单时间addTime等,订单状态status等)。除订单ID主键外,有各个查询条件字段的组合索引。
l 买手查询索引Mongodb Collection(sellerOrderIndex):一个Document对应一个订单,只存放可被作为买手查询条件的字段(如买手ID sellerId,下单时间addTime,订单状态status等)或有被聚合/汇总场景的字段(如订单金额amount等)。除订单ID主键外,有各个查询条件字段的组合索引。
l 订单明细ElasticSearch库(orderES):Mongodb之外,订单明细在ElasticSearch也有一份,主要用于跨买家/买手的查询(如来自客服系统的查询)和分词查询(例如根据商品描述中某些个关键词查询等)
基于上述的查询库,
-
对于买家查询服务,基本流程:根据查询条件从userOrderIndex查出所有orderIds,再根据orderIds,从order查询订单明细。
-
对于买手查询服务,基本流程:根据查询条件从sellerOrderIndex查出所有orderIds,再根据orderIds,从order查询订单明细。
-
对于跨买家/买手或分词查询:直接查orderES 库。
2.2 同步服务设计
不难看出,同步服务是整个2.0版本设计的重中之重。这里描述下同步服务设计/实现的关键点。
2.2.1 如何确保每一个SQL操作,最新数据都会被同步到查询库
订单的每一个操作场景(如下单,支付,发货等)都对应一个同步指令syncCmd。在订单操作数据库事务内将syncCmd也入库。事务成功,再通过MQ将syncCmd发送给同步服务。伪码如下:
| BeginT doOrderOperations insert(syncCmd) EndT mqClient.send(syncCmd) |
同步服务接收到syncCmd后先将指令落地到自己的mongodb库,再将SQL数据库中的syncCmd置为“已接收”。
为应对总线不可用或延迟的极端Case,同步服务有检测SQL数据库中长期(譬如超过300ms)处于“待接收”状态的syncCmd并将之落地到mongodb库的补单任务。
对于已落地到mongodb的syncCmd,同步服务确保其一定被执行成功,即从SQL数据库中读取对应的最新数据并写入到order/ userOrderIndex/ sellerOrderIndex/ orderES中。
2.2.2 订单并发操作场景,如何保证同步数据的正确性
考虑一个场景:虚拟商品的订单,订单支付成功即自动发货。在SQL数据库中,订单状态先到paid("已支付"),然后瞬时跃迁为shipped("已发货")。支付同步指令paidSyncCmd和发货同步指令shippedSyncCmd几乎同时到达同步服务。假设执行paidSyncCmd时,从SQL数据库读出的状态是paid,执行shippedSyncCmd时,从SQL数据库读出的状态是shipped,但在往查询库写入时,极有可能shippedSyncCmd早于paidSyncCmd,这样,查询库中,该订单状态先被shippedSyncCmd改为shipped,又被paidSyncCmd覆写为paid,与SQL数据库不一致。
对于该并发问题,有两种处理方案:
-
方案1:更新订单状态时,必须把允许的前置状态作为更新条件的一部分。
-
方案2:同步指令执行成功后,再从SQL库查一遍最新的状态,与查询库比较,如不一致再把最新状态同步到查询库。
方案1需要准确梳理每一个状态的前置状态,且在状态冲突时还要确保除状态之外的其他字段照常同步,实现和维护成本高。
方案2通过double check解决。好理解且实现简单,但引入了额外的查询操作。
考虑到基于ID的查询,对于SQL数据库和Document型数据库都是极其轻量级的操作,我们采纳简单易懂的方案2。
3. 交易3.0
尽管交易2.0下单TPS比1.0提升了2~3倍,但业务峰值增长更快,逐渐逼近我们产线压测的单库下单最大安全TPS。交易3.0迫在眉睫,且目标清晰:
-
基于积累的业务理解及预期和日常开发维护过程中的痛点重新设计订单的存储模型,尽可能精简,尽可能减少下单数据库I/O;
-
支持SQL数据库分库分表,使得无需变更应用,通过水平加数据库实例就能应对节节跃升的下单峰值。
得益于交易2.0中订单操作数据源与查询数据源已彻底分离,在交易3.0升级改造SQL库存储模型过程中,订单查询类服务无需任何变更。
3.1 分库分表方案
3.1.1 垂直切分
为尽可能的减少下单数据库I/O,将下单时的订单数据分为核心数据和扩展数据。核心数据指用户下单后立时必见和去支付时必需的数据。核心数据在下单时同步写入,放在订单核心库(core-db),core-db分库分表。扩展数据指下单时传入但下单后可稍延迟输出或非支付过程中必需的长文本数据(如收件人地址,商品描述等),扩展数据下单时异步写入,放在订单扩展库(ext-db),ext-db不分库分表
3.1.2 core-db水平切分
按用户ID (userId)将core-db中的订单相关业务表分库分表。譬如userId的某几位可以决定订单在那个库(例如core-db_3),另几位可以决定业务表表名(order_59,order_detail_59, payment_59, sync_cmd_59等)。
给定userId,就知道其各个订单业务表的表名及所在库。同一个userId的订单业务表都在同一个库,尽可能避免跨库事务。
3.1.3 订单ID设计
订单ID设计遵循如下原则:
-
数字型
-
尽可能的短
-
与2.0版本未分库分表的订单ID显著区分
-
根据ID,就知道该订单对应的业务表的表名及所在库
-
同一用户的订单ID无需严格递增,但整体趋势是递增的
-
订单ID不能体现任何订单量信息。譬如只是简单的以数据库某个自增sequence作为订单ID,别人只要在一个时间段内下两单,对比这两单的ID,就知道了平台在该时间段内的订单量。
3.1.4 技术选型
应用对分库分表的访问,大体有两种方案:
-
在应用和各分库之间部署一个独立的中间件服务(如mycat,http://mycat.io/),应用通过中间件访问数据库,中间件为应用做路由和聚合操作。
-
将对分库分表的路由/聚合功能封装为第三方类库直接内嵌在应用(如sharding-jdbc, https://github.com/sharding-sphere/sharding-sphere)
基于简单易用,维护部署成本低的考量,我们选择了sharding-jdbc。
3.2 种子服务
在单数据库场景下,业务ID一般可通过数据库Sequence生成。分库的场景下,再通过一个固定库的Sequence生成全局ID,显然不合适。为此,在交易3.0项目中,我们基于内存双buffer+数据库实现了一个简单、高效、稳定的种子服务,单机可达3.5w+的TPS。其基本思想是:数据库存放种子当前可被分配的最大值,种子服务根据内存中的当前值分配种子,当检测到当前值快接近最大值时,按一定步长更新数据库中的最大值。该种子服务已被广泛应用于其他业务系统中。
种子服务ID生成序列图:
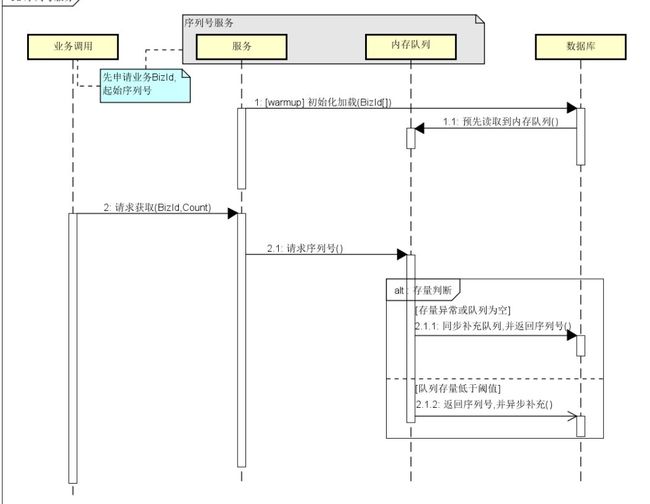 图3- 种子服务ID生成序列图
图3- 种子服务ID生成序列图
3.3 分库分表下的补单处理
开发分布式应用,补单场景随处可见。以下单为例,下单前,要调库存服务扣库存;若下单失败,要返库存。存在这样的case:刚调库存服务扣完库存,还没来得及生成订单,系统由于各种原因中断运行了(如运维发布重启),导致该返库存的没返库存。这时,就需要一个补单定时任务:扫描扣库存指令表,对于扣库存成功但没下单成功的指令,补调返库存。在单库单表时,通过<时间段,状态>扫描扣库存指令表是可行的。但如果指令表被分库分表了呢?假设被分成了8个库,每个库中的指令表又分了100张,一次补单检测就要做800张表的扫描动作,显然不可接受。分库分表下的补单设计,我们有两种方案,业务方可按需选择:
-
利用我们高可用的分布式调度服务(dScheduler):在扣库存之前,往调度服务发送一个10s之后运行的任务项,任务项中带有扣库存指令ID(cmdId)。10s之后,dScheduler用cmdId回调交易,交易确认cmdId对应的扣库存是否需要返库存。调度服务有高可靠性和完备的重试机制,只要不是业务服务机器的硬盘和网络同时故障,任务项一定会被送达调度服务;对于收到的任务项,调度服务确保其一定被业务方执行成功。
-
利用本地文件队列组件(fileQueue):扣库存之前,将
交易3.0产线压测,在只使用一个库实例的条件下,TPS是2.0的3~4倍。更重要的是,3.0的TPS是随数据库实例数线性增长的。通过水平扩展交易操作服务和数据库的实例数,就能成倍数的提升系统峰值处理能力,下单写入不再成为系统的瓶颈。下单TPS可以轻松倍增了,到一个临界点,同步服务/查询库反倒成为瓶颈,导致查询延迟。打破一个瓶颈,往往就会检测到接下来环节的新瓶颈。事实上,我们已在继续优化查询库和同步服务的路上,主要方向是:
-
将同步指令与订单数据分库存储。
-
与SQL写库一样,在不变更同步服务/查询服务前提下,订单mongodb查询库(order/userOrderIndex/sellerOrderIndex)也有完全的水平扩展能力。
4. 小结
技术无止境,技术服务于业务。业务的模式创新和高速发展,需要技术架构不断同步升级。技术人最大的成就感无疑就是设计适合的技术方案,踏实的落地,完美的支撑起业务。谨以此文与所有正在和曾在交易领域奋斗的同学们共勉!这里要特别感谢我们的自动化测试和DBA同学,没有完备的自动化测试用例,我们一次次再造式重构不会这么从容;没有DBA专深的数据库技术支持,我们的一次次存储模型升级改造不会这么有底气。
=>更多文章请参考:《中国互联网业务研发体系架构指南》https://blog.csdn.net/Ture010Love/article/details/104381157
=>更多行业权威架构案例、领域标准及技术趋势请关注微信公众号 '软件真理与光':
 更多权威内容关注公众号:软件真理与光
更多权威内容关注公众号:软件真理与光