1. AlexNet(2012)
论文来自“ImageNet Classification with Deep Convolutional Networks”,在2012年ILSVRC(ImageNet Large-Scale Visual Recognition Challenge)赢得了分类识别第一名的好成绩。2012年也标志卷积神经网络在TOP 5测试错误率的元年,AlexNet的TOP 5错误率为15.4%。
AlexNet由5层卷积层、最大池化层、dropout层和3层全连接层组成,网络用于对1000个类别图像进行分类。
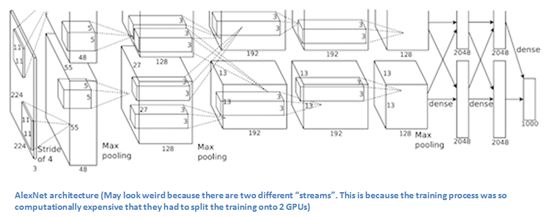
主要内容
1.在ImageNet数据集上训练网络,其中数据集超过22000个类,总共有大于1500万张注释的图像。
2.ReLU非线性激活函数(ReLU函数相对于tanh函数可以减少训练时间,时间上ReLU比传统tanh函数快几倍)。
3.使用数据增强技术包括图像转换,水平反射和补丁提取。
4.利用dropout方法解决过拟合问题。
5.使用批量随机梯度下降训练模型,使用特定的动量和权重衰减。
6.在两台GTX 580 GPU上训练了五至六天。
2. VGG Net(2014)
2014年牛津大学学者Karen Simonyan 和 Andrew Zisserman创建了一个新的卷积神经网络模型,19层卷积层,卷积核尺寸为3×3,步长为1,最大池化层尺寸为2×2,步长为2.
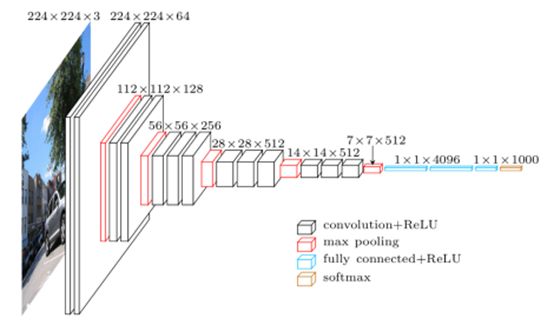

主要内容
1.相对于AlexNet模型中卷积核尺寸11×11,VGG Net的卷积核为3×3。作者的两个3×3的conv层相当于一个5×5的有效感受野。这也就可以用较小的卷积核尺寸模拟更大尺寸的卷积核。这样的好处是可以减少卷积核参数数量。
2.三个3×3的conv层拥有7×7的有效感受野。
- 随着每层输入volume的空间尺寸减小(conv和pool层的结果),volume的深度会随着卷积核数量的增加而增加。
4.每经过一次maxpolling层后,输出的深度翻倍。
在训练过程中使用比例抖动数据增强技术。
在每个conv层之后使用ReLU激活函数,使用批梯度下降优化算法进行训练。
在4个Nvidia Titan Black GPU上训练两到三周。
训练超参数设置
训练使用加动量的小批基于反向传播的梯度下降法来优化多项逻辑回归目标。批数量为256,动量为0.9,权值衰减参数为5x10−410−4,在前两个全连接层使用dropout为0.5,学习率为0.01,且当验证集停止提升时以10的倍数衰减,同时,初始化权重取样于高斯分布N(0,0.01),偏置项初始化为0。
为了获得初始化的224x224大小的图片,通过在每张图片在每次随机梯度下降SGB时进行一次裁减,为了更进一步的增加训练集,对每张图片进行水平翻转以及进行随机RGB色差调整。
初始对原始图片进行裁剪时,原始图片的最小边不宜过小,这样的话,裁剪到224x224的时候,就相当于几乎覆盖了整个图片,这样对原始图片进行不同的随机裁剪得到的图片就基本上没差别,就失去了增加数据集的意义,但同时也不宜过大,这样的话,裁剪到的图片只含有目标的一小部分,也不是很好。
VGG Net论文的核心
VGG Net是CNN领域最有影响力的论文之一,因为它强化了卷积神经网络必须具有一定的深度才能使视觉数据的得到有效分层描述的观点。保持深度并把事情简单化。
3. GoogLeNet(2015)
GoogleNet是一个具有22个conv层的CNN网络,是ILSVRC2014中以6.7%的TOP5错误率登顶大赛榜首的CNN模型,VGG Net以7.3%位居其下。据我所知,这是第一篇偏离conv和polling顺序堆叠的CNN架构。而且这篇论文的作者也强调,这个模型需要着重考虑内存和功耗(大量堆叠conv层和polling层容易导致过拟合并且消耗大量的计算机算力和内存)。
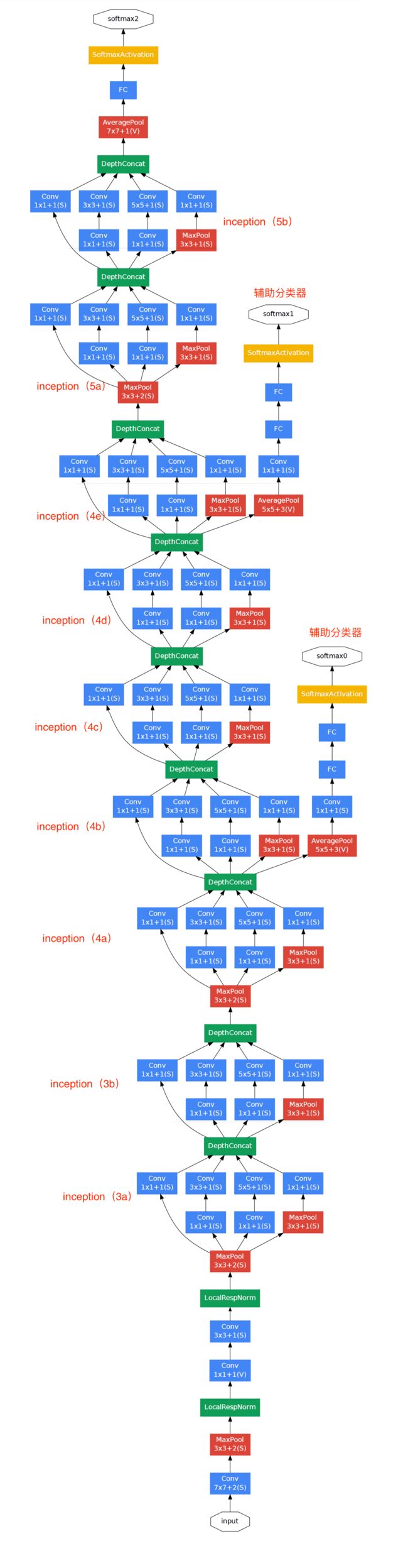
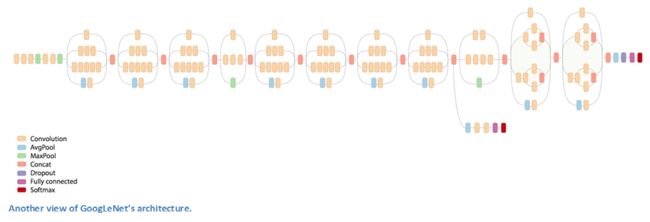
首先看看GoogLeNet的结构,我们注意到,此模型是并行处理的网络。
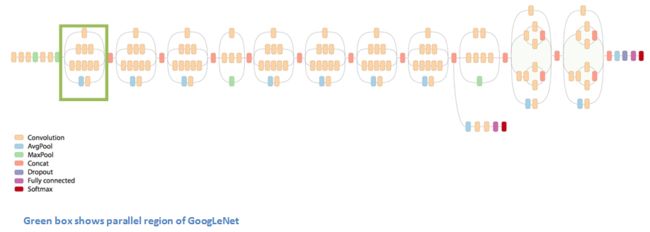
上图这个绿色的小方块被称为“Inception module”。它的组成如下面放大的结构:
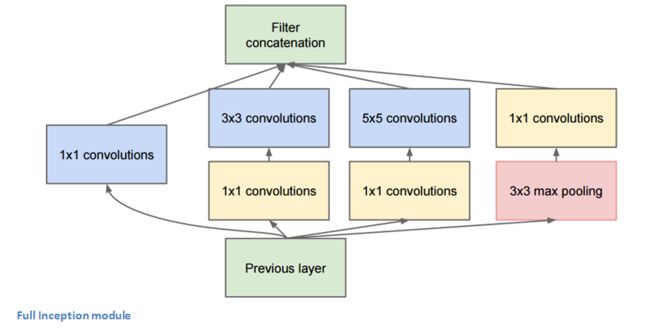
上图中,底部的绿色框是模型的输入部分,最上面的是模型的输出部分(将这张照片右转90度可以让您看到与显示完整网络的最后一张照片相关的模型)。在传统ConvNet的每一层,需要选择是否进行池化或转换(还有卷积核大小的选择)。Inception模块允许并行执行所有这些的操作。
事实上,这正是作者提出的“天真”的想法。
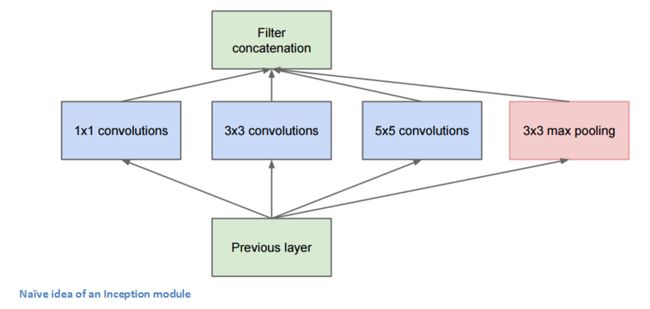
为什么上面这个想法“天真”?
这将导致输出太多,最终会得到一个非常深的通道。作者在论文中解决这个问题的方式是在3x3和5x5层之前添加1x1 conv操作,如上上幅图。1×1卷积提供了降维的方法。例如,假设图片输入尺寸为100x100x60(这不一定是图像的尺寸,只是网络任何层的输入)。应用20个1x1卷积核可以得到100x100x20 volume。这意味着3x3和5x5的卷积不会通过大量的卷积来处理。减小volume的深度,这可以被认为是“特征汇集”,类似于使用普通的maxpolling层来减小高度和宽度的尺寸。有关1x1卷积的有效性的更多信息可以看看这个视频。
1×1的卷积核的作用?
- 实现输入volume各通道之间的交互和信息整合
- 利用1×1的卷积核通道数进行降维或升维
为什么卷积核的尺寸为3x3?
这是能捕捉到图像各个方向信息的最小尺寸,如ZFNet中所说,由于第一层中往往含有大量的高频和低频信息,却没有覆盖到中间的频率信息,如果步长过大,则容易引起大量的信息混叠,因此卷积核的尺寸和步长都要尽量小
那么这个CNN架构是如何工作的呢?一个由中等大小的卷积核和一个池化层的模型网络。网络中conv层能够提取有关该volume中非常精细的纹理信息,而5x5卷积核则能够覆盖输入的大量感受野,从而也能提取其中的信息,还可以进行级联操作,从而减少spatial尺寸并减少过拟合。最重要的是,每个conv层之后都经过ReLU激活函数,这有助于提高网络的非线性性能。
主要内容
在整个架构中使用了9个Inception模块,总共超过100层!现在这是最深的CNN网络架构。
没有使用全连接层,使用的是averge polling,从7×7×1024的volume变成1×1×1024的volume,这减少了大量参数
参数是AlexNet的1/12,这其中的原因:①除去了全连接层;②1×1卷积核降维的效果。
利用R-CNN的概念(我们将在后面讨论这篇文章)介绍他们的检测模型。
在测试过程中,创建了多个相同的图像分割部分,然后将其输入至网络中,并利用softmax取平均值得到最终的分类结果。
利用一些高端的GPU进行了大概一周的训练。
GoogleNet论文的核心
GoogLeNet是第一个引入CNN层但不是必须依次叠加conv层和polling层的模型。作者表示,创造层次结构可以提高性能和计算效率。本文为我们在未来几年可以看到的一些令人惊叹的架构奠定了基础。
4. Microsoft ResNet (2015)
微软亚洲研究院2015年创造了一种令人难以置信的152层深度学习模型,ResNet在ILSVRC2015的错误仅仅为3.6%,已经高于了人类肉眼识别的错误率。
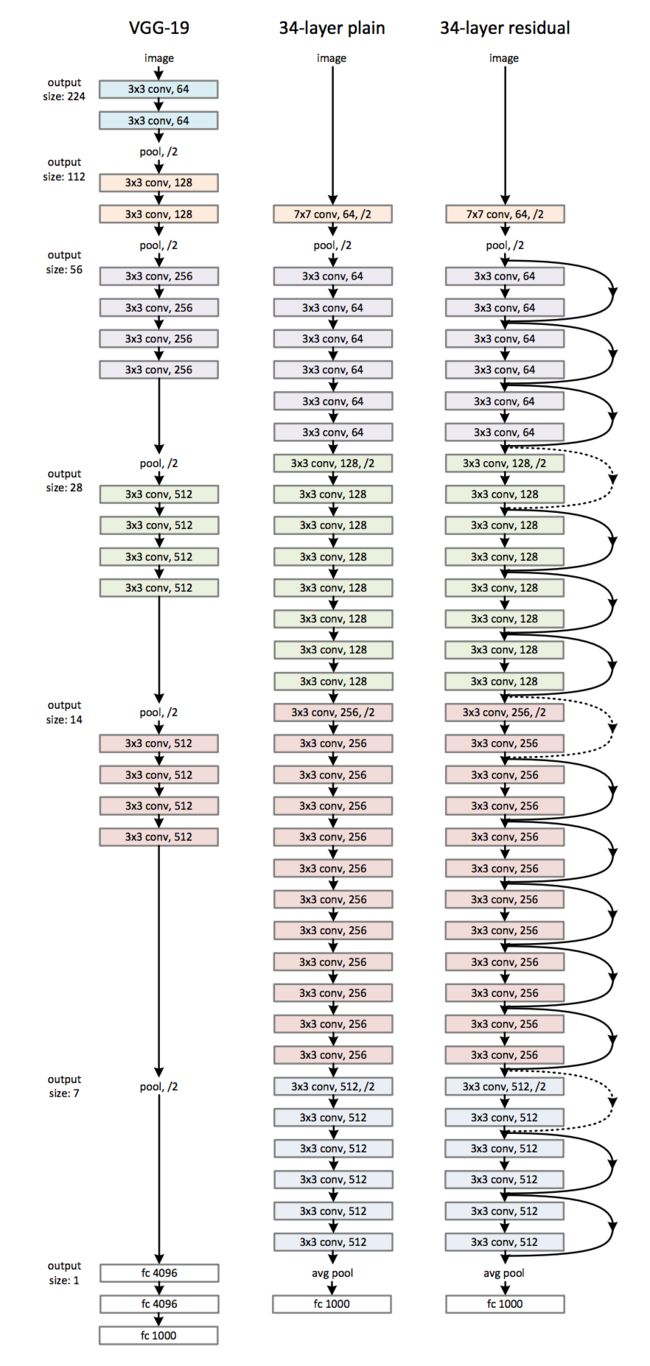
residual blocks的结构为conv-relu-conv排列,一个节点的输出为H(x)=F(x)+x, 其中F(x)为之前模型的输出结果,如下图所示
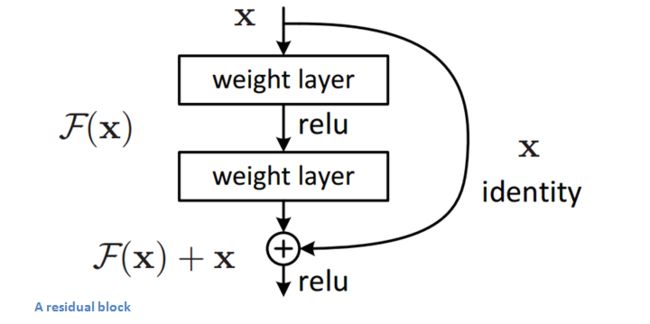
此结构层数很多,但是为什么不会出现梯度爆炸或梯度消失的情况呢?
就是因为上图这种加法操作,导致梯度反向传播过程中加上了原始输入,链式求导除了求relu,还有x本身。
主要内容
- 152层的结构,不可思议。
- 微软亚洲研究院的研究小组尝试过1202层的网络结构,但是测试精度很低,大概可能是由于过拟合的原因
- 在8台GPU机器上训练2到3周。
论文意义
3.6%的错误率足以说明ResNet模型是我们目前拥有的最好的CNN架构,是残留学习理念的一个伟大创新。
参考文献
1. The 9 Deep Learning Papers You Need To Know About (Understanding CNNs Part 3)
2. 深度学习之解读VGGNet
3. CNN 中, 1X1卷积核到底有什么作用呢? 打开这个链接,有比较详细的介绍
4. 深度学习之GoogLeNet解读
5. 经典的几个卷积神经网络(基本网络)