NDK学习笔记:RtmpPusher之利用faac库将pcm格式编码为aac
NDK学习笔记:RtmpPusher之利用faac将pcm格式编码为aac
打算一篇总结完知识点。faac的源码编译过程就不介绍了,网上很多。而且faac版本貌似已经稳定不更新,所以直接拿人家编译好的库也没问题(我github工程里面就是已经是最后一个版本的了)。
不废话,开始代码,java层代码如下:
private AcousticEchoCanceler canceler;
private int audioRecordChannelNum = 1;
private int sampleRateInHz = 44100;
private int minBufferSize;
private boolean isAudioRecord;
private AudioRecord audioRecord;
private void initRecordAudio() {
// 单声道 44100
int channelConfig = audioRecordChannelNum == 1 ?
AudioFormat.CHANNEL_IN_MONO : AudioFormat.CHANNEL_IN_STEREO;
minBufferSize = AudioRecord.getMinBufferSize(sampleRateInHz, channelConfig, AudioFormat.ENCODING_PCM_16BIT);
audioRecord = new AudioRecord(MediaRecorder.AudioSource.MIC,
sampleRateInHz, channelConfig,
AudioFormat.ENCODING_PCM_16BIT, minBufferSize);
if (AcousticEchoCanceler.isAvailable()) {
initAEC(audioRecord.getAudioSessionId());
}
//启动录音子线程
isAudioRecord = true;
new Thread(new AudioRecordTask()).start();
}
private class AudioRecordTask implements Runnable{
@Override
public void run() {
audioRecord.startRecording();
//开始录音
while(isAudioRecord) {
//通过AudioRecord不断读取音频数据
byte[] buffer = new byte[minBufferSize];
//ByteBuffer byteBuffer = ByteBuffer.allocateDirect(minBufferSize);
int len = audioRecord.read(buffer, 0, buffer.length);
if(len > 0){
if(rtmpPusher!=null){
rtmpPusher.feedAudioData(buffer, buffer.length);
}
}
}
}
}
// android.os.Build.VERSION.SDK_INT >= 16;
public boolean initAEC(int audioSession) {
if (canceler != null) {
return false;
}
canceler = AcousticEchoCanceler.create(audioSession);
if (canceler != null) {
canceler.setEnabled(true);
return canceler.getEnabled();
}
return false;
}
-------------------------------------------------------------------------------------
if(rtmpPusher == null) {
rtmpPusher = new RtmpPusher();
}
prepareAudioEncoder(sampleRateInHz, audioRecordChannelNum);这一段是系统API的运用,主要是依靠AudioRecord配合AcousticEchoCanceler(系统的回声消除),打开系统麦克风进行录音操作,获取一手的pcm格式的音频数据。 之后我们就可以把pcm格式的数据喂养到RtmpPusher里面了,记得喂养前找个恰当时机调用prepareAudioEncoder初始化音频编码器。 然后我们直接到prepareAudioEncoder的实现。
JNIEXPORT void JNICALL
Java_org_zzrblog_ffmp_RtmpPusher_prepareAudioEncoder(JNIEnv *env, jobject jobj,
jint sampleRateInHz, jint channelNum)
{
if(gRtmpPusher == NULL) {
gRtmpPusher = (RtmpPusher*)calloc(1, sizeof(RtmpPusher));
}else if(gRtmpPusher->faac_encoder != NULL){
return;
}
gRtmpPusher->sampleRateInHz = sampleRateInHz;
gRtmpPusher->channelNum = channelNum;
// 初始化faac音频编码器
gRtmpPusher->faac_encoder = faacEncOpen((unsigned long) sampleRateInHz,
(unsigned int) channelNum,
&(gRtmpPusher->nInputSamples),
&(gRtmpPusher->nMaxOutputBytes));
if(!gRtmpPusher->faac_encoder){
LOGE("音频编码器打开失败");
return;
}
//设置音频编码参数
faacEncConfigurationPtr pFaacConfigure = faacEncGetCurrentConfiguration(gRtmpPusher->faac_encoder);
pFaacConfigure->mpegVersion = MPEG4;
pFaacConfigure->allowMidside = 1;//是否允许MidSide Coding(详情百度)
pFaacConfigure->aacObjectType = LOW;//设置AAC类型
pFaacConfigure->outputFormat = 0; //输出是否包含ADTS头
// RAW_STREAM = 0, ADTS_STREAM=1 (ADTS可以实现单帧单独解码,raw由于缺少头无法单帧解码,因此无法续传跳播)
pFaacConfigure->useTns = 1; //是否使用瞬时噪声定形滤波器(具体作用不是很清楚)
pFaacConfigure->useLfe = 0; //是否允许一个声道为低频通道
pFaacConfigure->bitRate = 48000; //设置比特率
pFaacConfigure->inputFormat = FAAC_INPUT_16BIT; //设置输入PCM格式
pFaacConfigure->quantqual = 100;//数字信号的质量
pFaacConfigure->bandWidth = 0; //频宽
pFaacConfigure->shortctl = SHORTCTL_NORMAL;
if(!faacEncSetConfiguration(gRtmpPusher->faac_encoder, pFaacConfigure)) {
LOGE("%s","音频编码器配置失败..");
return;
}
LOGI("%s","音频编码器配置成功");
}faac音频编码器的流程比较简单,第一步就是faacEncOpen获取编码器句柄faacEncHandle。
方法共有四个参数,前两个是传入参数,后两个是回传的参数。
sampleRateInHz是音频采样的频率;
channelNum是声道数;
nInputSamples代表当前输入采样率对应的采样个数;
nMaxOutputBytes代表当前设置的aac编码输出之后的最大字节数;
然后第二步,调用faacEncGetCurrentConfiguration获取当前配置参数,并进行一些针对性的自定义设置。这一步你可以对应理解为x264的 x264_param_default_preset 。上面这些设置详尽我也不太懂,我就关心三个参数:
1、outputFormat:Bitstream output format (0 = Raw; 1 = ADTS) 输出是否包含ADTS头,一般都是用0,什么时候用1呢?
在此之前先来认识什么是ADTS头信息:ADTS是Audio Data Transport Stream的简称。是AAC音频文件常见的传输格式。有的时候当你编码AAC裸流的时候,会遇到写出来的AAC文件并不能在PC和手机上播放,很大的可能就是AAC文件的每一帧里缺少了ADTS头信息文件的包装拼接。只需要加入头文件ADTS即可。一个AAC原始数据块长度是可变的,对原始帧加上ADTS头进行ADTS的封装,就形成了ADTS帧。
下图简单呈现了ADTS头文件结构和信息:AAC音频文件的每一帧由ADTS Header和AAC Audio Data组成。(关于ADTS的头信息介绍和代码追加ADTS-Header的方法也很固定,比如可以参考这里。我这里节省篇幅就不一一介绍了。)
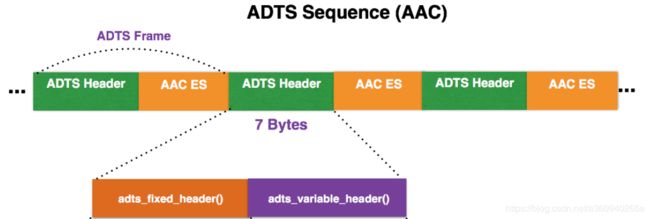
如果是解析音视频文件(譬如MP4)的时候,如果mp4容器头能正确识别音轨参数,解码器能正确初始化,那么音轨上的AAC码流可以不带ADTS。反之,就必须带ADTS,让解码器在默认初始化设置的时候,动态的识别当前音频码流的设置。如果是解析动态码流,如果能提前知道音频的设置参数,并在初始化音频解码器前设置正确,那么就不需要带ADTS头,反之,则需要通过动态码流设置ADTS,让解码器在默认初始化设置的时候,动态的识别当前音频码流的设置。
一句话总结,ADTS就是让解码器知道当前准备要解码的音频码流是怎样的设置参数,好让解码器能最好的达到解码效率。
编码器已经知道音频的参数了,而且这里是PCM转AAC,ADTS只是针对解码aac的时候使用的。所以我就设置为0(Raw)。
2、bitRate:设置音频码流的比特率。这个比特率能更好的控制网络传输时候的带宽。控制吞吐量
3、inputFormat:设置输入PCM格式,有四个选项:FAAC_INPUT_NULL、FAAC_INPUT_16BIT、FAAC_INPUT_24BIT、FAAC_INPUT_32BIT分别对应的是一个采样点对应所占的空间。 我们在java代码中通过AudioRecord设置获取的PCM数据编码格式为AudioFormat.ENCODING_PCM_16BIT,所以这里也应该设置对应的FAAC_INPUT_16BIT。
然后我们就可以调用faacEncSetConfiguration,把定义好的编码环境重新设置到faacEncHandle。到此初始化音频编码器成功。
然后我们开始分析喂养PCM数据到faac编码器的函数feedAudioData(难点来了。)
JNIEXPORT void JNICALL Java_org_zzrblog_ffmp_RtmpPusher_feedAudioData
(JNIEnv *env, jobject jObj, jbyteArray j_pcm_array, jint len)
{
if(gRtmpPusher==NULL || gRtmpPusher->faac_encoder==NULL)
return;
// 传入的pcm_array 编码是 ENCODING_PCM_16BIT
jbyte* pPcmArray = (*env)->GetByteArrayElements(env, j_pcm_array, 0);
// 16位 两字节 相当于 short
int16_t * pcm_input = (int16_t *)malloc(gRtmpPusher->nInputSamples * sizeof(int16_t));
// 8位 1字节 相当于 char / byte
uint8_t * aac_output = (uint8_t *)malloc(gRtmpPusher->nMaxOutputBytes * sizeof(uint8_t));
int nByteCount = 0; //缓存计算位
unsigned int pcm_short_buf_size = (unsigned int) len / 2; //传入的byte数组包含多少个16位的pcm编码采样数据
int16_t* pcm_short_buf = (int16_t*) pPcmArray;
while (nByteCount < pcm_short_buf_size) {
// 针对每nInputSamples个16位pcm数据操作
unsigned int audioLength = gRtmpPusher->nInputSamples; //aac编码输入的默认采样个数
if ((nByteCount + gRtmpPusher->nInputSamples) >= pcm_short_buf_size) {
audioLength = pcm_short_buf_size - nByteCount;
}
for (int i = 0; i < audioLength; i++) {
// 每次从传入的pcm音频队列中读出量化位数为16位的pcm数据。
pcm_input[i] = (pcm_short_buf + nByteCount)[i];
}
nByteCount += gRtmpPusher->nInputSamples;
//利用FAAC进行编码
int byteslen = faacEncEncode(gRtmpPusher->faac_encoder,
pcm_input, audioLength,
aac_output, gRtmpPusher->nMaxOutputBytes);
if (byteslen < 1) {
continue;
}
// 从aac_output中得到编码后的aac数据流,放到数据队列
add_aac_body(aac_output, byteslen);
}
//处理完当前批pcm数据了,释放资源
(*env)->ReleaseByteArrayElements(env, j_pcm_array, pPcmArray, NULL);
if (aac_output)
free(aac_output);
if (pcm_input)
free(pcm_input);
}先从faac编码的接口faacEncEncode入手,其方法在头文件的定义如下:
int FAACAPI faacEncEncode(faacEncHandle hEncoder, // 编码器句柄
int32_t * inputBuffer, // 输入的PCM数据
unsigned int samplesInput,// 输入的采样数
unsigned char *outputBuffer,// 编码结果输出
unsigned int bufferSize); // 输出的内存空间大小五个参数意义如上注释,一眼看上去感觉没什么难度是吧,我们一个个参数看。
1、faacEncHandle,就是我们初始化的 gRtmpPusher->faac_encoder。这个参数没疑问。
2、int32_t * inputBuffer,输入数据,int32_t 意思就是32位的整形,对应C语法上的就是 signed int , 但是我们传入进来的jbyteArray j_pcm_array,经过(*env)->GetByteArrayElements 获取到的是 jbyte* 头指针。 这个类型在jni.h定义成int8_t,8位的整形,也就是C语法上的 signed char,如何正确的转化?
3、输入的采样个数,这个参数意义有点熟悉,是初始化打开编码器的时候回传的gRtmpPusher->nInputSamples吗?
4、编码结果的输出指针,这个参数没什么异议。
5、输出的空间大小。这个就是参数4的长度了。也没异议。
接下来,我们就一起讨论分析第二第三个参数该要怎么处理。回到feedAudioData方法上。
首先第一步,我们获取传入进来的pcm字节数组的头指针(jbyte == signed char == 8位);第二步,根据编码器回传的输入采样个数,以FAAC_INPUT_16BIT(short == int16_t ==16位)为单位,分配好内存空间,同样根据编码器回传的输入最大字节数,以字节为单位(uint8_t == unsigned char == 8位)(注意这两个回传的单位,一个是个数,一个字节数);
第三步开始转化逻辑,请好好理解:首先我们另起一个 (short == int16_t ==16位)类型的指针,记为pcm_short_buf,指向pcm字节数组(强转型),这样每次操作都是以16位为单位(两个byte)。然后计算出 传入的pcm字节数组数组包含多少个16位的pcm编码采样数据,记为pcm_short_buf_size;因为我们不知道 16位的pcm编码采样数据的长度pcm_short_buf_size 和 编码器回传的输入的默认采样个数nInputSamples 的大小关系。所以我们只能每批次的操作,而且操作前都需要判断是否即将填满输入编码器的PCM内存空间,然后再一步步的从pcm_short_buf获取16位数据,写入即将输入编码器的PCM内存空间。 最后到faacEncEncode进行编码。
编码出来的AAC数据和视频的h264数据一样,都需要追加对应的头,才能在网络传输的过程中被识别。除了内容数据包以外,还需要在内容数据包之前,发送配置参数包。但是和x264不一样的是,faac这个库的配置参数包,不是需要编码出来的,能直接从faacEncoder中获取。
上代码之前先简单介绍AAC-Header的结构:
AAC header结构(2个字节)
1、SoundFormat,4bit,有以下选项
0 = Linear PCM, platform endian
1 = ADPCM
2 = MP3
3 = Linear PCM, little endian
4 = Nellymoser 16 kHz mono
5 = Nellymoser 8 kHz mono
6 = Nellymoser
7 = G.711 A-law logarithmic PCM
8 = G.711 mu-law logarithmic PCM
9 = reserved
10 = AAC
11 = Speex
14 = MP3 8 kHz
15 = Device-specific sound
2、SoundRate,2bit,抽样频率,有以下选项
0 = 5.5 kHz
1 = 11 kHz
2 = 22 kHz
3 = 44 kHz
对于AAC音频来说,总是0x11,即44khz.
3、SoundSize,1bit,音频的位数。
0 = 8-bit samples
1 = 16-bit samples
AAC总是为0x01,16位。
4、SoundType,1bit,声道
0 = Mono sound
1 = Stereo sound
5、AACPacketType,8bit。这个字段来表示AACAUDIODATA的类型
0 = AAC sequence header
1 = AAC raw。
配置参数包用类型0,内容数据包都用类型1。设置参数包要在内容数据包之前发送。
//添加AAC编码的sequence header
void add_aac_sequence_header()
{
if(gRtmpPusher==NULL || gRtmpPusher->faac_encoder==NULL)
return;
//从faacEncoder获取配置信息
unsigned char *spec_buf;
unsigned long len; //长度
faacEncGetDecoderSpecificInfo(gRtmpPusher->faac_encoder, &spec_buf, &len);
uint32_t body_size = 2 + len;
char* body = malloc(sizeof(char)*body_size);
//AUDIODATA的标志位,各位标志如下
body[0] = 0xAF;
// SoundFormat(4bits):10=AAC;
// SoundRate(2bits):3=44kHz;
// SoundSize(1bit):1=16-bit samples;
// SoundType(1bit):1=Stereo sound;
//AACAUDIODATA的AACPacketType
body[1] = 0x00;
// 1表示AAC raw,
// 0表示AAC sequence header
//AACAUDIODATA的RawData
memcpy(&body[2], spec_buf, len); /*spec_buf是AAC sequence header数据*/
// ... 未完待续 ...
free(spec_buf);
}
// 为内容数据包追加aac头
void add_aac_body(unsigned char *buf, int len)
{
if(gRtmpPusher==NULL)
return;
int body_size = len + 2;
char* body = malloc(sizeof(char)*body_size);
//AUDIODATA的标志位,各位标志如下
body[0] = 0xAF;
// SoundFormat(4bits):10=AAC;
// SoundRate(2bits):3=44kHz;
// SoundSize(1bit):1=16-bit samples;
// SoundType(1bit):1=Stereo sound;
//AACAUDIODATA的AACPacketType
body[1] = 0x01;
// 1表示AAC raw,
// 0表示AAC sequence header
//AACAUDIODATA的RawData
memcpy(&body[2], buf, (size_t) len); /*spec_buf是AAC raw数据*/
// ... 未完待续 ...
}
下章学习RTMP,利用rtmpdump库完成h264和aac的内容发送。顺带利用一下数据结构-双向列表,使整个流程结构得到优化。