第五届中间件大赛总结(初赛)
一.写在前面
第五届中间件大赛结束了,后面马上投入到下阶段的工作项目,甚至连总结都没来得及写,趁着这一段时间相对充裕,把之前比赛的中收获记下来,为了更好的前行。
成绩:初赛:160,复赛:65 ,这个成绩很菜,在大佬面前根本拿不出手,更多的是为了能够学习更多知识,技能以及和更多的同学交流。
![]()
![]()
二.初赛
初赛的题目是 自适应负载均衡的设计实现
1.要求
修改题目提供的扩展接口(UserLoadBalance),实现一套自适应负载均衡机制。要求能够具备以下能力:
1、Gateway(Consumer) 端能够自动根据服务处理能力变化动态最优化分配请求保证较低响应时间,较高吞吐量;
2、Provider 端能自动进行服务容量评估,当请求数量超过服务能力时,允许拒绝部分请求,以保证服务不过载;
3、当请求速率高于所有的 Provider 服务能力之和时,允许 Gateway( Consumer ) 拒绝服务新到请求。
2.分析:
dubbo的题目,复写负载均衡算法,以达到自适应分配流量的效果。具体的说,就是根据不同provider的处理能力来分配请求,以求达到整体的吞吐率(TPS)最大化。其中,每个provider的处理能力是不断(阶段)变化的。
这里面有两个关键指标,一个是rt,单个请求的处理耗时,一个是cmt, 一个provider进程的最大并发线程数,这两个是描述一个provider处理能力的具体指标,一般来讲,一个单机(进程)实例的吞吐率(tps) 和这个两个参数的关系是
![]()
即并发线程数越多,单个处理时间越短,处理的总请求数就越多,处理能力就越强,实际情况是,rt和cmt都是受实际硬件,内存,网络等条件制约,并且到一定程度会达到瓶颈,而且会不断变化,比赛中评测程序会模拟cmt,rt的变化,选手是要尽可能把流量分配给最好的那个provider,以及把每个provider都打到自己能承受负荷的最大值,是这个比赛的目的所在。
在这个思路下,容易想到的就是根据tps来分配流量,本人不才,最后采用的方案也是根据tps来分配流量,后面会分享下具体的做法,总体说下,根据provider统计的tps来分配流量,这种方法基线高,但也没有太大的潜力可挖掘,因为一个是具有滞后性,一个是具有宏观性,滞后性是指tps的统计会晚于实际变化,总是采用上一次的结果来反馈,会有时延,第二个粒度太粗,实际上并无法反应真正的处理能力,有会一定程度过载。
3.方案:
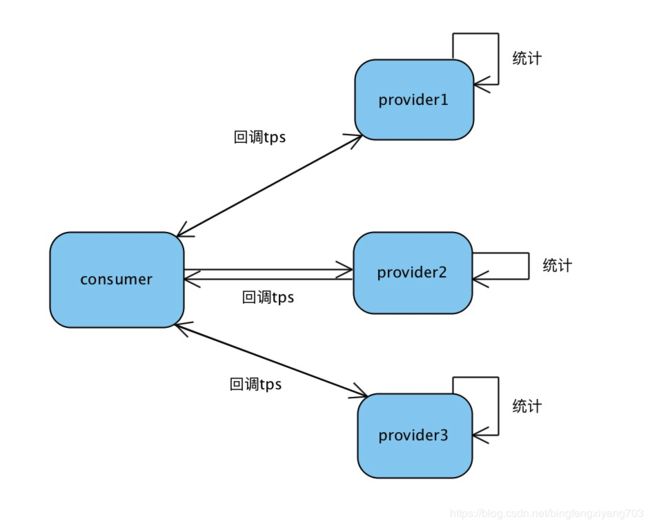
dubbo提供类似于AOP的filter,在每个provider服务调用的filter里埋点,统计单位时间内的成功请求数,比赛里面提供几个工具,一个是provider对conusmer的callback,用户反向通信,一个是定时任务,两者结合起来,完成统计数据的传输,将provider的tps传给消费者,供流量分配时使用。
consumer侧,采用加权的随机分配方案,权重就是provider反馈回来的tps,默认初始值是一样的,也即是平均分配,后面根据反馈的tps值按权重分配。
这里面有两个注意的点
1.采样的周期,不宜过长或者过短,过长数据不及时,过短不足以达到目标的最佳状态,实际上周期也没有算,是调试出来的
2.没有放在consumer侧统计,本身可以直接放在consumer,但实测会带来很多性能损耗
4.代码
负载均衡的代码:
int length = invokers.size(); // 总个数
boolean sameWeight = true;
for (int i = 0; i < length; i++) {
int weight = getQpsWeight(invokers.get(i));
totalWeight += weight; // Sum
if (sameWeight && i > 0 && weight != getQpsWeight(invokers.get(i - 1))) {
sameWeight = false;
}
}
if (totalWeight > 0 && !sameWeight) {
// 如果不是所有的 Invoker 权重都相同,那么基于权重来随机选择。权重越大的,被选中的概率越大
int offset = ThreadLocalRandom.current().nextInt(totalWeight);
for (int i = 0; i < length; i++) {
offset -= getQpsWeight(invokers.get(i));
if (offset < 0) {
return invokers.get(i);
}
}
}
// 如果所有 Invoker 权重相同
return invokers.get(ThreadLocalRandom.current().nextInt(length));
}
private int getQpsWeight(Invoker invoker){
return DataNode.getInvokerData(invoker.getUrl().getPort()).getSuccessQps();
}
filter埋点的代码:
@Activate(group = Constants.PROVIDER)
public class TestServerFilter implements Filter {
@Override
public Result invoke(Invoker invoker, Invocation invocation) throws RpcException {
try{
SimpleStatNode.collectData();
return invoker.invoke(invocation);
}catch (Throwable t){
throw (RuntimeException) t;
}
}第一段代码,消费端使用采集过来的qps数据,进行加权随机,权重就是对应的provider的qps
第二段代码是采集服务端的qps数据,每一个成功请求,对应的qps数据+1,类型采用LongAddr,定时任务向consumer汇报,同时清零前1秒的数据,重新统计
5.性能分析:
性能最终在1268999分,后面参数在调优的话,包括权重比值和采样周期,都无法在提高了,后来对比了大佬的算法,考量点有这么几个:
1.采样的滞后性: 采用总是采集前1秒的数据,尽管官方公布的变化周期是6S,虽然在采用周期的粒度内,但是在变化的转折点上有较大的性能损失,至少在临界点附近采用的仍是之前的权重,就会有不饱和或者过载的产生
2.宏观性,或者粒度太粗,tps是过去1s内的平均效果,对于1S内有1W-2W的请求而言,并不能根据实时的处理能力进行流量分配,rt和cmt都是变化的,而且变化节奏不一样,从整体上看,似乎tps大的可以得到更高的调度额,实际上,他本身的能力也变化的,并不能达到 每个proivder在每个时间段的自身的最大理想值,所以为了保证能充分压榨,所以总是存在过载,通过过载反馈调节tps达到平衡,所以可以看到这种算法总是不是100%,有性能损失。
3.RT指标的缺失,RT指标是一个关键指标,在这个算法下,没有使用到这个信息,在开始做的时候,是有考虑到统计RT的,单后来得到这个数据之后无从下手,或者当时的调试方式认为RT的影响因素已经包含在tps里面了,就没有对RT做专门的反馈平衡(实际做了,在整体思路不变的情况下,效果并不理想),这是这次比赛比较大的遗憾。后面看到前几名大佬,使用RT做探步算法的时候,才明白,这个参数才是微观上调节流量分配的关键所在。