第五届中间件大赛总结(复赛)
一.写在前面
复赛的题目是百万级别的消息引擎的设计与实现,最后成绩是65名。就个人感觉而言,复赛是比初赛要热闹的多,第四届的初赛是dubbo mesh,要考察方方面面,但是第五届的主要复写负载均衡算法,考察面相对较窄,复赛就不一样了,文件I/O,内存映射,零拷贝,堆外内存操作,甚至GC优化,操作系统层面的pageCache都要涉及到,中间还不断去翻RocketMQ的源码用于参考,不由得感慨,RocketMQ真是大师级的作品。
二.复赛
1.题目
实现一个进程内消息持久化存储引擎,要求包含以下功能:
- 发送消息功能
- 根据一定的条件做查询或聚合计算,包括
A. 查询一定时间窗口内的消息
B. 对一定时间窗口内的消息属性某个字段求平均,以及求和
消息内容简化成两个字段,一个是业务字段a(整数),一个是时间戳(long)。实际存储格式用户自己定义,只要能实现对应的读写接口就好
评测:
-
发送阶段:假设发送消息条数为N1,所有消息发送完毕的时间为T1;发送线程多个,消息属性为: a(随机整数), t(输入时间戳模拟值,和实际时间戳没有关系, 线程内升序).消息总大小为50字节,消息条数在20亿条左右,总数据在100G左右
-
查询聚合消息阶段:有多次查询,消息总数为N2,所有查询时间为T2; 返回以t和a为条件的消息, 返回消息按照t升序排列
-
查询聚合结果阶段: 有多次查询,消息总数为N3,所有查询时间为T3; 返回以t和a为条件对a求平均的值
2.分析
消息队列的题目,提供读写接口的引擎,Jvm相关参数-Xmx4g -XX:MaxDirectMemorySize=2g -XX:+UseConcMarkSweepGC
1.消息20亿条,每条50字节,总共100G,和去年一样,100G的数据量是无法全部放到内存里面,需要落盘以支持消息堆积;
2.发送线程是12个线程并发发送,。每个消息的时间戳线程内有序,不同线程之间不保证顺序,但整体递增,换句话,线程间的无序是并发导致的,并不是独立生成的,这点很重要;
3.系统SSD性能大致如下: iops 1w 左右;块读写能力(一次读写4K以上) 在200MB/s 左右,这个主要关系读写性能,优化存储结构来充分利用iops,实际上我最后一般吞吐率是达不到最大,IOPS会达到瓶颈;
4.压缩算法,支持压缩,但是不能过分利用数据特性,特别比赛到后面白热化阶段,大佬们居然可以16G的数据全压进堆内内存,然后全内存操作,来提高第三阶段的TPS, 也是非常大胆有想法的思路,最后这种办法被主办方禁用了,可能考察I/O优化和存储结构才是复赛的本意吧,毕竟,生产的数据不可能全放内存,比赛更多是模拟生产的状态,来产生更好创意和解决方案,而不是就比赛论比赛。
3.方案
1.整体思路
- 还是按块存储,或者按块建索引,稀疏索引,常驻内存,不落盘;
- 数据落盘,但是A,T,body分开落盘,一个全量,一个单独A,T的,当然后面我的做法,有优化空间,刚开还担心冗余数据会不会影响写性能,实际会是会的,但是影响非常小,冗余一份数据用于提高读的TPS做法,对写性能性能影响不大,但是读性能提升非常明显
- 排序,因为最后提供出去的消息需要按T升序排列,其实即便结果不需要升序,只要指定时间区间了,排序的也是避免不了的,因为指定时间区间,如果不顺序落盘的,随机I/O的会被大量浪费,最开始为了提高写性能,没有在落盘的时候排序,最后读性能成绩很低,实际上在落盘排序是性价比很高的方案
- 平均值方案,就是第三阶段的方案,实际上最后成绩第三阶段的成绩占总成绩的80%左右,大佬们的天王山,不过个人对第三阶段的提升并不大,没有压缩,也没有使用内存存储,还是按硬盘/O的方式来做的,但是就硬盘I/O来言,也还是有优化空间,当时读的瓶颈上来了,其实并不是吞吐率到头了,而是IOPS到达瓶颈,下一步应该是减少I/O次数。当时,这是后话
2.系统设计:
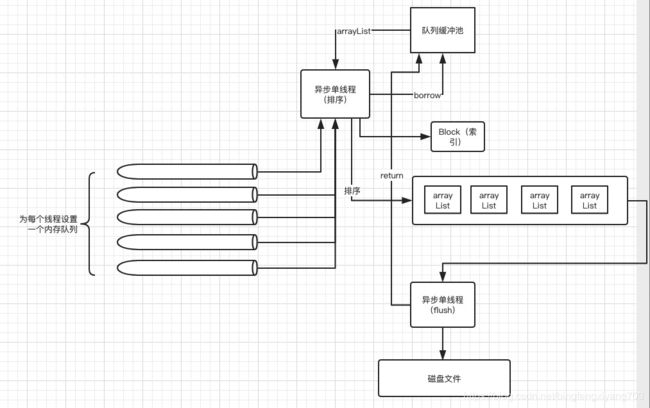
总体上是三个队列,2个线程
- 缓冲队列,用来缓冲评测程序过来数据,用户后续处理,最出是没有这个缓冲队列的,直接在发送函数里面进行排序,实际上不同线程之间的时差跨度还是非常大的,如果等到所有线程都大于某个数,写过程会超时
- 缓冲池,这个是块结构的缓冲池,里面每一个元素是一个ArrayList,用于后续flush线程使用,主要用于复用,开始设计是有Bytebuffer,但是buffer不可扩容,只要做成队列,然后flussh线程转换成buffer
- ArrayList队列,用户异步处理待flush的数据块,这个数据的参数调优非常影响写性能,最后产生了大量的FULL GC,后面会说道
- 排序线程:排序线程单独拿出来是为了能够不影响评测程序正常工作引入的,因为如果在写发方法本身里面排序,性能消耗非常大
- 落盘线程,主要讲阻塞队列中的数据块(准确说是数组)落盘。
3.整体流程:
- 1.消息进来之后首先进入对应进程的内存队列中,这个队列的长度是50W,如果超过最大长度线程阻塞;等待队列被消费;
- 2.排序线程会在另一端对队列进行消费,这里面主要会有一个设定的递增值,比如2000,在基数+2000之间的消息会被填进arrayList,然后所有线程队列的数>基数+2000之后,对应的ArrayList进行排序,生成索引,相当于这一块数据会作为一个block块落盘,索引只要记录时间偏移量,消息数量,文件起始偏移量和终止偏移量,总之是一个稀疏索引,记录此block在文件中的偏移位置,供后面读取快速检索,但是这个粒度是一个整块,所以,块的大小是调优参数,太小,写速度会受影响,太大,索引的区分不高;
- 3.然后,该数据块会被送到另一个flush队列里面。另一个落盘线程,会专门从落盘队列里去数据,然后转换成ByteBuffer,落盘,写入文件;
- 4.为了避免中间的缓冲队列撑满内存,ArrayList的设计采用的池话的策略,在使用缓冲buffer的时候,从pool里面borrow,然后在落盘完成之后归还,池的大小也是重要的调优参数。
4.I/O选择
一般文件I/O有四种,一个是传统BIO,一个是RandomAcessFile的文件NIO接口,还有一个FileChannel,另外,还有一个是mmp,内存映射,第一种肯定不考虑,第二种的接口可用的定制参数太少,API用起来不方便,最后采用的FileChanel +堆外内存的方式进行;为什么没有使用mmp,虽然mmp号称是内存读写,并使用了零拷贝,减少一次内核态向用户态的转换,但实测的性能,在高压力请求(指IOPS接近打满)的情况下,mmp的性能并不比FileChannel好,甚至还出现了小幅的下滑,这里面可能的原因:
- 1.虽然是内存映射,但是实际还是依托了操作系统层面的pagecache,写盘相当于是写pageCache,然后操作系统层面专门有一个flush的线程来将数据落库,同时已经存在的pagecache可以作为读的缓存使用
- 2.mmp引入了虚拟内存的概念,这个虚拟内存不是操作系统层面那个虚拟内存,这个是堆外内存,相当于是使用堆外内存实现零拷贝,实际上FileChannel可以配合堆外内存使用,也可以起到类似的效果,所以mmp在filechannel面前优势不大
有资料的标签,在大量小文件块操作的时候,mmp 比filechanel的效果可能要好,但这个目前在这次比赛中无处验证,有兴趣的同学可以研究下;
另外,这里面附篇大佬的文章,大家可以参考下
1.https://www.cnkirito.moe/file-io-best-practise/
4.代码
I/O的问题先讨论到这,接着看下代码
索引block的字段, 内存索引,没有落库,大概每2000个消息一个块,20亿调消息大概是100W块,内存大概是200M,这个4G内存,够用
public class Block {
private long positionOffset;
private long TOffset;
private long startTimeTramp;
private long endTimeTramp;
private int mesNum;
private long sum;
}buffer池,准确说是数组池的设计
public class ArrayListPool {
private static final int total_size = 1000;
private LinkedBlockingQueue> bufferList = new LinkedBlockingQueue<>();
private AtomicInteger usedCount = new AtomicInteger(0);
public ArrayList borrow() throws Exception{
if (usedCount.get() <= total_size){
ArrayList list = new ArrayList(4000);
usedCount.incrementAndGet();
return list;
}
return bufferList.take();
}
public void returnBack(ArrayList list)throws Exception{
bufferList.put(list);
}
}
QueueExecutor.execute(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
while (true){
try {
Message message1= null;
ArrayList cacheList = arrayListPool.borrow();
RemainingCounter.temp_list = cacheList;
for (Map.Entry> entry: listQueue.entrySet()){
LinkedBlockingQueue queue =entry.getValue();
if (queue.peek() == null){
Thread.sleep(100);
}
while (queue.peek()!= null && queue.peek().getT() < num0){
if (dataBuffer.count < cacheList.size() ){
message1 = queue.peek();
cacheList.get(dataBuffer.count).setT(message1.getT());
cacheList.get(dataBuffer.count).setA(message1.getA());
cacheList.get(dataBuffer.count).setBody(message1.getBody());
queue.poll();
} else {
cacheList.add(queue.poll());
}
dataBuffer.count++;
}
if (queue.peek() == null){
if (!listBool.get(entry.getKey())){
Thread.sleep(500);
if (queue.peek() == null){
listBool.put(entry.getKey(),true);
}
}
}
}
if (checkMan()){
break;
}
if (dataBuffer.count < cacheList.size()){
for (int k= cacheList.size()-1;k>=dataBuffer.count;k--){
cacheList.remove(k);
}
}
cacheList.sort(new Comparator() {
@Override
public int compare(Message o1, Message o2) {
if (o1.getT() > o2.getT()) {
return 1;
}
if (o1.getT() == o2.getT()) {
return 0;
}
return -1;
}
});
dataBuffer.beginTimeTramp = cacheList.get(0).getT();
dataBuffer.endTimeTramp = cacheList.get(cacheList.size() - 1).getT();
Block block = new Block();
block.setStartTimeTramp(dataBuffer.beginTimeTramp);
block.setEndTimeTramp(dataBuffer.endTimeTramp);
block.setPositionOffset(fileOffset);
block.setTOffset(numOffset);
block.setMesNum(dataBuffer.count);
msgMap.add(block);
//放到一个队列里异步刷盘
WriteModule writeModule = new WriteModule();
writeModule.setMesNum(block.getMesNum());
writeModule.setList(cacheList);
workQueue.put(writeModule);
fileOffset += message_length * dataBuffer.count;
numOffset += T_length * dataBuffer.count;
dataBuffer.count = 0;
dataBuffer.aMin =0;
dataBuffer.aMax=0;
dataBuffer.block_sum =0;
num0 = num0 + fix_length;
} catch (Exception e) {
e.printStackTrace();
}
}
}
});
} 这个是异步排序线程的代码,主要是取数据,排序,生成索引,丢入落盘队列,应该是这个思路的最主要的设计所在了
后面的代码不在一一帖进去了,已放到github上开源,有兴趣的同学可以拉下代码看下
5.分析:
这次名称不高的原因:
- 1.写阶段,以后FULL GC频繁出现,之前的设计是没有异步缓冲队列的,后面经群友启发,使用排序的方式,但排序的时候不同线程的T相差较大,如果按采用等待的方式的,30分钟根本不够,所以肯定有一个队列,但这个队列最后并不是full gc的来源,真正影响的是缓冲池的大小,后面才发现,其实4G内存,里面YoungGeneration只有300M左右,大部分都是老年代的,而且缓冲池有2个G左右,这个CMS算法每次回收老年代的时间有10S-20S左右,而且每分钟基本有一次,这的话,每次基本上都会超时,后来减少缓冲池的大小到500M,虽然还存在,但至少是20分钟至内能完成写操作。因为评测环境不能修改JVM的参数,不然换下垃圾回收算法可以看看效果,至少是学习JVM GC的一个很好素材
- 2.读消息阶段,其实读消息没有太多可说的,主要是要全量读,这个是分数都普遍较低的阶段,毕竟没法压缩
- 3.三阶段,我这里没有使用过多的设计,基本上还是按照正常文件I/O的方式来做,所以即使在有序的情况下,文件系统能提供的tps也只在7000分左右了,在往上只能使用算法或者升级数据结构来辅助了
6.总结:
后来看了大佬的分享,有几个思路,这里面记下,后面如果有长期赛,可以继续实践下:
- 1.IOPS的优化,实际上虽然T有序之后,单独读A 的范围已经限定很小,但是分数上不去主要是因为IOPS达到了极限,当时没有想到这点,以为是文件锁争用导致的,花了大量时间去看锁相关的内容,以及文件I/O api的问题,但是没有实质提升
- 2.排序,文件落盘时只对T排序,没有对A排序,这个算法有待优化,进行A的检索效率不高。实际上,可以数据块间使用T进行排序,块内对A进行排序,这个会缩小对A的检索范围,这个才是真正能减少IOPS的方法
- 3.压缩,对于时序的数据,本身就是可以压缩,最早的设计方案就是对T进行压缩,来减少单次I/O占用,后来精力都花在优化IO API上面了,另外,还有一个原因,当时在主办方通知A不能压缩之后,个人自己理解MQ这边可能更多是考察I/O本身,对于文件,操作系统,pageCache方面的优化,对于压缩反而没有关注,但实际上,时序数据压缩很重要,这也是一点遗憾吧
- 4.分文件,目前我这边的设计是100G的文件全部落到一个文件里面,这里面有利有弊,之前以后群友沟通,分文件的方式,在切换文件channel的时候,会产生性能损失,这个没有实际验证;不过,分文件之后又几个好处,一个是可能分而治之,避免filechannel的锁冲突,第二个可能充分利用多线程进行聚合,相当于原来是一个,现在可以10个filechannel一起读,然后在内存里面汇总,相当于也是空间换时间的做法,前提是不能到达IOPS
最后,在说说mmp,其实最后几天,没有改进算法和压缩,更多时间花在研究文件I/O的API上了,虽然最后并没有实际进展
1.mmp在第三阶段的性能上,实际比FileChannel + 堆外内存的性能还要差,大概在6000分左右,这个确实是不太好理解,个人认为可能跟映射的文件大小有关的,这个具体可以参考之前大佬的文章。
2.中间参考了RocketMQ的源码,发现MQ本身是既有mmp,又有FileChannel的,写入的时候更像是用后者实现的,MQ里面为什么会这么设计,可能在压测时候的发现了某些深层次的原因,这个就静待大佬解答了
7.写在最后:
最后在说几句题外话,对于上班族而言,做这个比赛确实比较累,但也很开心,平时看MQ的源码,总感觉泛泛而谈,只有真正自己去设计,去思考和实践才能发现里面的问题,以及好的思路是怎么诞生的。
另外,沟通交流真的学习的重要途径,闭门造车很容易陷入局部战争出不来,思维的碰撞,往往更能产生创意的火花。