Apache Hadoop Zookeeper示例
文章来自:https://examples.javacodegeeks.com/enterprise-java/apache-hadoop/apache-hadoop-zookeeper-example/
===文章采用Google Translator=====Google翻译:建议先看原文。
在这个例子中,我们将探讨Apache Zookeeper,从简介开始,然后是设置Zookeeper并使其运行的步骤。
1.介绍
Apache Zookeeper是分布式系统的构建块。当设计分布式系统时,总是需要开发和部署可以通过集群协调的东西。这是Zookeeper进入图片。它是一个由Apache维护的开源项目,用于维护和协调分布式集群。Zookeeper提供的一些服务包括:
命名服务:名称服务用于将名称映射到某种数据,然后可以使用此名称访问。例如,DNS服务器映射到服务器的IP地址,然后客户端可以使用该URL名称访问服务器。在分布式系统中,我们可能需要使用分配给它们的名称来检查服务器或节点的状态。这可以通过使用由Zookeeper默认提供的命名服务接口来完成。
配置管理:Zookeeper还提供集中管理分布式系统配置的选项。配置可以集中存储在Zookeeper上,任何加入分布式系统的新节点都可以从Zookeeper中选择配置。这使得管理配置很容易,免费。
领导选举:分布式系统通常需要一个自动故障转移策略,以防一些节点故障。Zookeeper提供了使用leader选择功能这样做的选项。
锁定:在每个分布式系统中,将有一些共享资源,并且多个服务可能需要访问此资源。因此,为了允许对此资源的序列化访问,需要锁定机制。Zookeeper提供这个功能。
同步:对共享资源的访问也需要在分布式设置中同步。Zookeeper还提供了一个简单的接口。
2. Zookeeper如何工作?
Zookeeper遵循客户端 - 服务器模型。其中客户端是集群中的计算机。 这些机器也称为节点。 这些客户端使用服务器提供的服务。Zookeeper协调分布式系统,但它本身也是一个分布式系统。 分布式模式下的Zookeeper服务器集合称为Zookeeper集合。

在任何给定的时间,一个客户端可以只连接到一个Zookeeper服务器,但每个zookeeper服务器可以处理多个客户端的时间。客户端定期向服务器发送ping(心跳),以使其知道它是活动的并连接到服务器。Zookeeper服务器还响应一个确认通知它还活着并连接。这些ping / heartbeats的频率可以在配置文件中设置,我们将在下一节中看到。
如果客户端没有收到来自在指定时间段内连接到的服务器的确认,客户端然后尝试从池连接到另一个服务器,并且在成功的连接上,客户端会话被传送到新的Zookeeper服务器它连接到。
Zookeeper遵循类似于文件系统的分层系统在节点中存储数据,它被称为znode。Znode源自“Zookeeper数据节点”。每个znode作为一个目录,可以有多个子节点,层次结构继续。为了访问znode,Zookeeper遵循文件路径类似的结构。例如:到znode firstnode的路径和相应的子节点可以看起来像这样:/firstnode/sub-node/sub-sub-node
3.Zookeeper设置
在本节中,我们将通过在localhost上设置Zookeeper服务器的步骤来进行实验。Zookeeper在包中提供单个服务器,可以直接在机器上运行。
3.1系统要求
- Java,JDK 6或更高版本(我们将使用JDK 8)
- 最小2GB RAM
- 双核处理器
- Linux操作系统。 Linux作为开发和生产系统都受到支持。 Windows和MacOSX只支持作为开发系统,而不是作为生产系统。
3.2安装Java
首先,我们将检查是否在系统上安装了Java,如果没有,我们需要首先安装Java。要检查是否安装了Java,请使用:
java -version如果这返回Java版本号,则安装Java。 确保它至少是JDK 6或更高版本。如果没有安装Java,我们必须先安装它。 使用以下命令安装Java JDK 8。
sudo apt-get update
sudo apt-get intstall openjdk-8-jre-headless第一个命令将更新所有已安装的软件包,第二个命令将安装OpenJDK 8.以下是我们在运行上述命令后得到的控制台输出:
要检查安装是否成功,请再次运行命令:
java -version3.3下载Zookeeper
下一步是从Resease网站下载稳定版本的Zookeeper。从发布站点的下载部分手动下载稳定版本(在编写本文时,稳定版本为3.4.6)。 我们可以使用网站中提到的任何镜像(如下面的屏幕截图所示),并解压缩/解压到所需的文件夹。
或使用以下命令下载和解压:
wget http://www.eu.apache.org/dist/zookeeper/stable/zookeeper-3.4.6.tar.gz
tar -xvf zookeeper-3.4.6.tar.gz
cd zookeeper-3.4.6/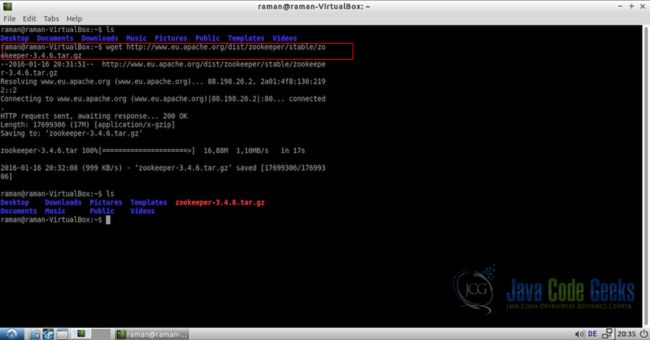
3.4数据目录
接下来,我们需要一个目录来存储与znode和其他zookeeper元数据相关的数据。为此,我们将在/ var / lib /中通过名称zookeeper创建一个新目录
sudo mkdir /var/lib/zookeeper
cd /var/lib
ls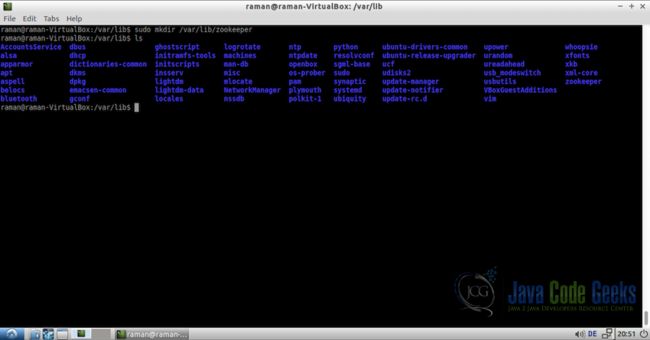
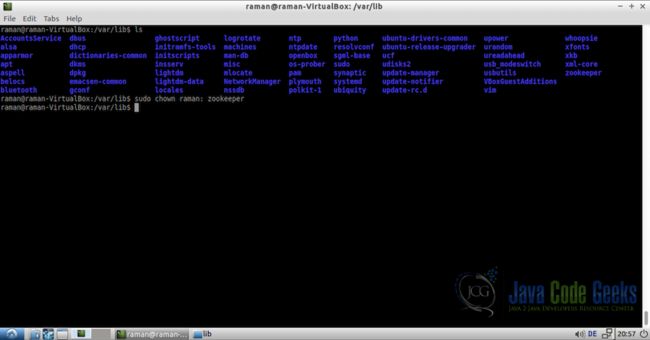
当使用sudo创建此目录时,它将默认使用root作为所有者,我们需要更改为Zookeeper将运行的用户,以便Zookeeper服务器可以访问该目录没有任何麻烦。要更改用户,请从文件夹/ var / lib运行以下命令:
cd /var/lib
sudo chown raman: zookeeper注意:":"和zookeeper之间有一个空格。这里我们只提到raman用户作为目录的所有者,没有用户组(usergroup在:)之后。 所以它会将用户的默认用户组分配给目录zookeeper。
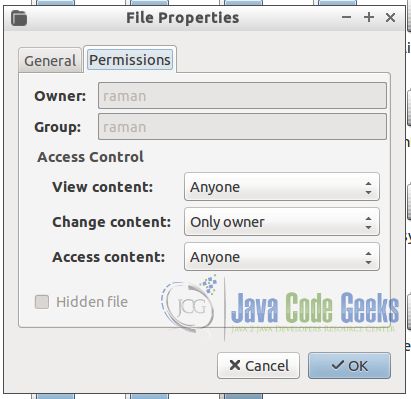
要确保所有者已更改,请转到/ var / lib / zookeeper目录的属性并检查权限。它应该分配给我们设置的用户:
3.5配置文件
现在是时候对Zookeeper服务器的配置进行必要的更改。它已经包含我们将用作模板的示例配置文件。 示例配置文件位于文件夹zookeeper-3.4.6 / conf /中,并命名为zoo-sample.cfg
首先让我们将文件重命名为zoo.cfg。 文件的名称无关紧要,但conf文件夹中应该只有一个.cfg文件。
cd zookeeper-3.4.6/conf
mv zoo-sample.cfg zoo.cfg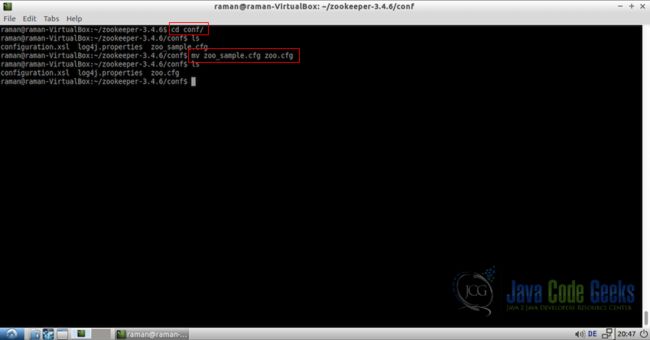
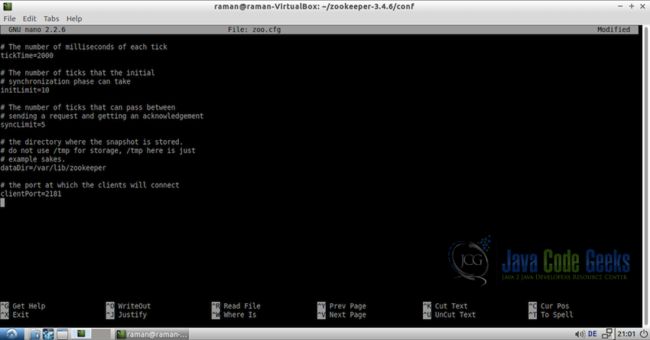
现在,让我们编辑这个zoo.cfg文件。 在这个例子中,我们使用了nano编辑器,但是你可以使用任何你喜欢的编辑器。
nano zoo.cfgtickTime = 2000
initLimit=10
syncLimit=5
dataDir=/var/lib/zookeeper
clientPort=2181注意:dataDir应该设置为我们在上一步创建的目录,即/ var / lib / zookeeper
让我们简要概述这些配置设置的含义:
- tickTime:Zookeeper对所有系统节点进行心跳检测,以检查所有节点是否存活和连接的时间。
- initTime:初始同步阶段可以采用的滴答数。
- syncTime:在发送请求和获取确认之间可以通过的tick数。
- dataDir:由Zookeeper存储内存数据库快照和事务日志的目录。
- clientPort:将用于客户端连接的端口。
3.6启动服务器
现在是启动Zookeeper服务器的时候了。 Zookeeper自带了一个脚本文件,以方便启动服务器。该文件称为zkServer.sh。 所以要启动服务器使用以下代码:
cd zookeeper-3.4.6/
bin/zkServer.sh start它应该显示类似以下屏幕截图的控制台输出:

4. Zookeeper服务器基本交互
4.1启动CLI
一旦Zookeeper服务器成功运行,我们可以启动CLI(命令行界面)与服务器交互。使用以下命令:
cd zookeeper-3.4.6/
bin/zkCLi.sh -server使用此命令,控制台将进入Zookeeper命令行模式,我们可以使用Zookeeper特定的命令与服务器交互。
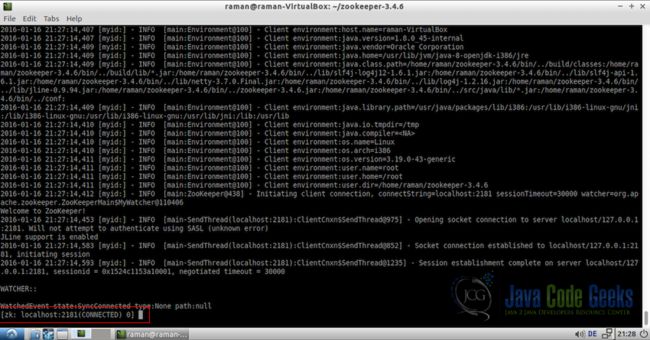
4.2创建第一个Znode
让我们从创建一个新节点开始。 下面是Zookeeper命令创建一个带有虚拟数据的新znode。
create /firstnode helloworlddummytext这里,firstnode是将在根路径上创建的znode的名称,如/表示根路径,helloworlddummytext是存储在znode内存中的虚拟文本。
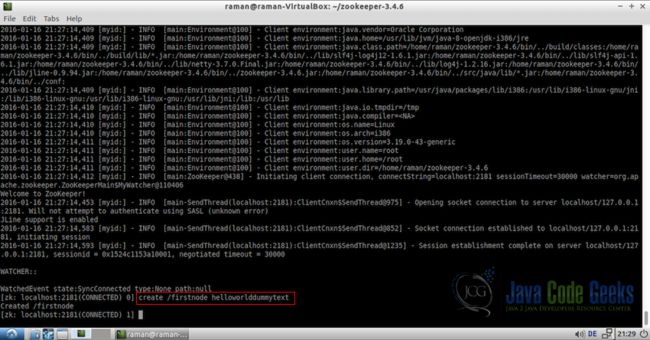
4.3从第一Znode检索数据
类似于我们如何创建一个新的znode,我们可以使用CLI(命令行界面)获得znode的详细信息和数据。以下是从znode获取数据的命令。
get /firstnode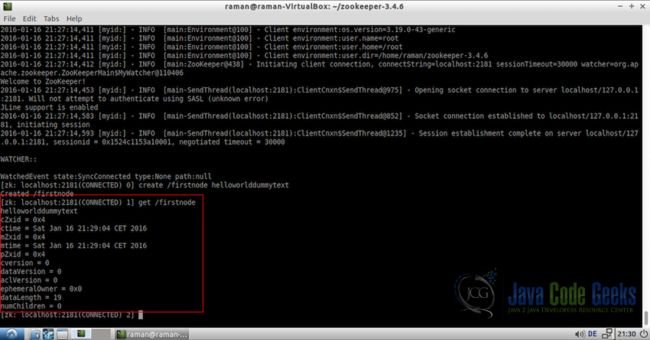
如果你在截图中注意到,连同我们在创建时存储在znode中的数据,服务器也返回了一些与这个特定znode相关的元数据。
元数据中的一些重要字段是:
- ctime:创建此znode的时间。
- mtime:上次修改时间。
- dataVersion:每次修改数据时发生变化的数据的版本
- datalength:存储在znode中的数据的长度。在这种情况下,数据是helloworlddummydata,长度为19。
- numchildren:此aprticualr znode的子项数。
4.4修改Znode中的数据
如果我们要修改特定节点中的数据,Zookeeper也为其提供一个命令。以下是如何修改现有znode中的数据:
set /firstnode helloworld
如果你注意到在上面的截图中datalength,mtime和dataversion也会更新,当一个新的值设置。
4.5创建子节点
在现有节点中创建子节点与创建新节点一样简单。我们只需要传递新子节点的完整路径。
create /firstnode/subnode subnodedata
get /firstnode/subnode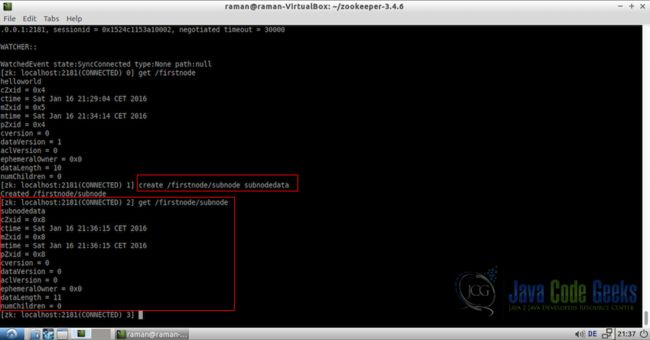
4.6删除节点
在Zookeeper CLI中使用rmr命令删除节点非常容易。删除节点也删除其所有子节点。 以下是我们为此示例创建的用于删除firstnode的代码:
rmr /firstnode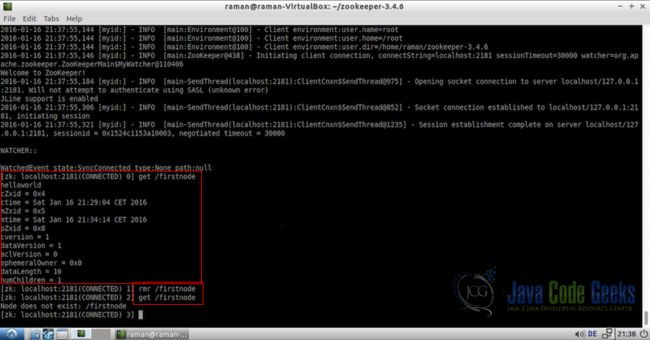
5.结论
这使我们得出这个Apache Zookeeper的介绍性例子的结论。在这个例子中,我们开始了Zookeeper的介绍和一般的架构,然后学习如何在单个机器中设置Zookeeper。 我们还看到使用Zookeeper CLI与Zookeeper服务接口也很容易,并且命令存在于所有的基本交互。
6.下载配置文件
您可以在此处下载此示例中使用的配置文件zoo.cfg:Zookeeper Configuration